







最近在看关于CNN的一些论文,经常遇到一些概念不明不白的,所以下决心把那些基础概念整明白。
本次博客主要是先介绍梯度下降法然后介绍反向传导法。其实从某种方向上看两者是很相似的。
一,梯度下降法
梯度下降法又称最速下降法。首先我们应该清楚,一个多元函数的梯度方向是该函数值增大最陡的方向。具体到假如是一元函数,其梯度方向就是切线方向。举个例子:
有函数y=x*x-3*x+2,有x0=0,步长为0.5,收敛精度为0.00001.其求解如下:
(1)计算x第i次的迭代公式:x(i)=x(i)-0.5*(2*x(i)-3);
(2)将初始的y0的值赋值给y1,并将x(i)带入到y0中去
(3)y0与y1的差值,若差值小于收敛精度就结束,否则迭代(1),(2),(3)直到差值达到收敛精度。
另外与最小二乘法类似梯度下降法主要是用于解决线性拟合问题。例如有m个样本点{(x1,y1),(x2,y2),...,(xm,ym)}
我们假设给出的函数模型是h(θ)=θ0+θ1*x1+...+θm*xm ,根据样本点求取具体θ集合的值。首先我们创建一个对函数模型h(θ)进行好坏评估的的损失函数:
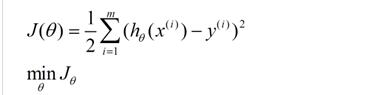
我们的目标是根据θ集来求取最小的J(θ)的值。
梯度下降法是按下面的流程进行的:
1)首先对θ赋值,这个值可以是随机的。
2)改变θ的值,使得J(θ)按梯度下降的方向进行减少。
首先我们对函数J(θ)相对于向量θ的每个分量求偏导。
然后利用求得的偏导分量迭代的求θ的值,
最后根据得到的θ值带入到J(θ)中,若J(θ)变化不大,则结束,否则迭代求解。
二,反向传导法
反向传播算法的思路如下:给定一个样例 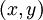 ,我们首先进行“前向传导”运算,计算出网络中所有的激活值,包括
,我们首先进行“前向传导”运算,计算出网络中所有的激活值,包括 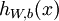 的输出值。之后,针对第
的输出值。之后,针对第  层的每一个节点
层的每一个节点  ,我们计算出其“残差”
,我们计算出其“残差” 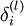 ,该残差表明了该节点对最终输出值的残差产生了多少影响。对于最终的输出节点,我们可以直接算出网络产生的激活值与实际值之间的差距,我们将这个差距定义为
,该残差表明了该节点对最终输出值的残差产生了多少影响。对于最终的输出节点,我们可以直接算出网络产生的激活值与实际值之间的差距,我们将这个差距定义为 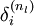 (第
(第 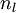 层表示输出层)。对于隐藏单元我们如何处理呢?我们将基于节点(译者注:第
层表示输出层)。对于隐藏单元我们如何处理呢?我们将基于节点(译者注:第 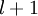 层节点)残差的加权平均值计算 ,这些节点以
层节点)残差的加权平均值计算 ,这些节点以 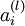 作为输入。下面将给出反向传导算法的细节:
作为输入。下面将给出反向传导算法的细节:
- 进行前馈传导计算,利用前向传导公式,得到
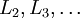 直到输出层
直到输出层 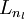 的激活值。
的激活值。 - 对于第 层(输出层)的每个输出单元 ,我们根据以下公式计算残差:
-
- 对
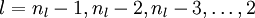 的各个层,第 层的第 个节点的残差计算方法如下:
的各个层,第 层的第 个节点的残差计算方法如下:
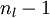 与的关系替换为与的关系,就可以得到:
与的关系替换为与的关系,就可以得到:
-
- 计算我们需要的偏导数,计算方法如下:
-
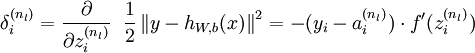
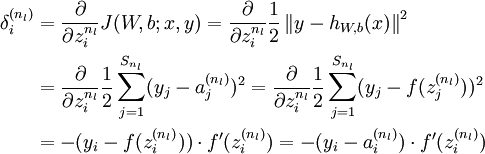
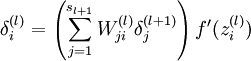
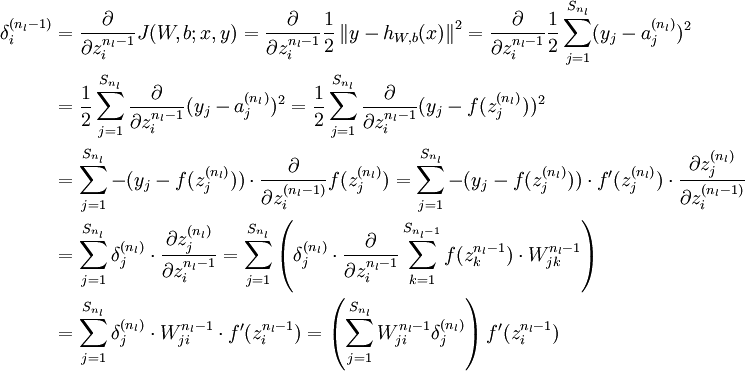
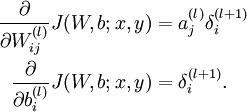
最后,我们用矩阵-向量表示法重写以上算法。我们使用“ ” 表示向量乘积运算符(在Matlab或Octave里用“.*”表示,也称作阿达马乘积)。若
” 表示向量乘积运算符(在Matlab或Octave里用“.*”表示,也称作阿达马乘积)。若 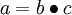 ,则
,则 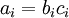 。在上一个教程中我们扩展了
。在上一个教程中我们扩展了 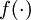 的定义,使其包含向量运算,这里我们也对偏导数
的定义,使其包含向量运算,这里我们也对偏导数 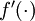 也做了同样的处理(于是又有
也做了同样的处理(于是又有 ![\textstyle f'([z_1, z_2, z_3]) = [f'(z_1), f'(z_2), f'(z_3)]](http://deeplearning.stanford.edu/wiki/images/math/c/7/5/c7515c53b59e670ceee277e06c1229cb.png) )。
)。
那么,反向传播算法可表示为以下几个步骤:
- 进行前馈传导计算,利用前向传导公式,得到 直到输出层 的激活值。
- 对输出层(第 层),计算:
-
- 对于 的各层,计算:
-
- 计算最终需要的偏导数值:
-
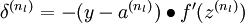
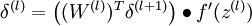
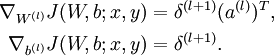
公式说明:J(W,b;x,y)表示的是单个样本(x,y)的损失函数,















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











