







1背景介绍
现今分布式计算框架像MapReduce和Dryad都提供了高层次的原语,使用户不用操心任务分发和错误容忍,非常容易地编写出并行计算程序。然而这些框架都缺乏对分布式内存的抽象和支持,使其在某些应用场景下不够高效和强大。RDD(Resilient Distributed Datasets弹性分布式数据集)模型的产生动机主要来源于两种主流的应用场景:
Ø 迭代式算法:迭代式机器学习、图算法,包括PageRank、K-means聚类和逻辑回归(logistic regression)
Ø 交互式数据挖掘工具:用户在同一数据子集上运行多个Adhoc查询。
不难看出,这两种场景的共同之处是:在多个计算或计算的多个阶段间,重用中间结果。不幸的是,在目前框架如MapReduce中,要想在计算之间重用数据,唯一的办法就是把数据保存到外部存储系统中,例如分布式文件系统。这就导致了巨大的数据复制、磁盘I/O、序列化的开销,甚至会占据整个应用执行时间的一大部分。
为了解决这种问题,研究人员为有这种数据重用需要的应用开发了特殊的框架。例如将中间结果保存在内存中的迭代式图计算框架Pregel。然而这些框架只支持一些特定的计算模式,而没有提供一种通用的数据重用的抽象。于是,RDD横空出世,它的主要功能有:
Ø 高效的错误容忍
Ø 中间结果持久化到内存的并行数据结构
Ø 可控制数据分区来优化数据存储
Ø 丰富的操作方法
对于设计RDD来说,最大的挑战在于如何提供高效的错误容忍(fault-tolerance)。现有的集群上的内存存储抽象,如分布式共享内存、key-value存储、内存数据库以及Piccolo等,都提供了对可变状态(如数据库表里的Cell)的细粒度更新。在这种设计下为了容错,就必须在集群结点间进行数据复制(data replicate)或者记录日志。这两种方法对于数据密集型的任务来说开销都非常大,因为需要在结点间拷贝大量的数据,而网络带宽远远低于RAM。
与这些框架不同,RDD提供基于粗粒度转换(coarse-grained transformation)的接口,例如map、filter、join,能够将同一操作施加到许多数据项上。于是通过记录这些构建数据集(lineage世族)的粗粒度转换的日志,而非实际数据,就能够实现高效的容错。当某个RDD丢失时,RDD有充足的关于丢失的那个RDD是如何从其他RDD产生的信息,从而通过重新计算来还原丢失的数据,避免了数据复制的高开销。
尽管基于粗粒度转换的接口第一眼看起来有些受限、不够强大,但实际上RDD却能很好地用于许多并行计算应用,因为这些应用本身自然而然地就是在多个数据项上运用相同的操作。事实上,RDD能够高效地表达许多框架的编程模型,如MapReduce、DryadLINQ、SQL、Pregel和HaLoop,以及它们处理不了的交互式数据挖掘应用。
2 RDD简介
2.1概念
RDD是一种只读的、分区的记录集合。具体来说,RDD具有以下一些特点:
Ø 创建:只能通过转换(transformation,如map/filter/groupBy/join等,区别于动作action)从两种数据源中创建RDD:1)稳定存储中的数据;2)其他RDD。
Ø 只读:状态不可变,不能修改
Ø 分区:支持使RDD中的元素根据那个key来分区(partitioning),保存到多个结点上。还原时只会重新计算丢失分区的数据,而不会影响整个系统。
Ø 路径:在RDD中叫世族或血统(lineage),即RDD有充足的信息关于它是如何从其他RDD产生而来的。
Ø 持久化:支持将会·被重用的RDD缓存(如in-memory或溢出到磁盘)
Ø 延迟计算:像DryadLINQ一样,Spark也会延迟计算RDD,使其能够将转换管道化(pipeline transformation)
Ø 操作:丰富的动作(action),count/reduce/collect/save等。
关于转换(transformation)与动作(action)的区别,前者会生成新的RDD,而后者只是将RDD上某项操作的结果返回给程序,而不会生成新的RDD:
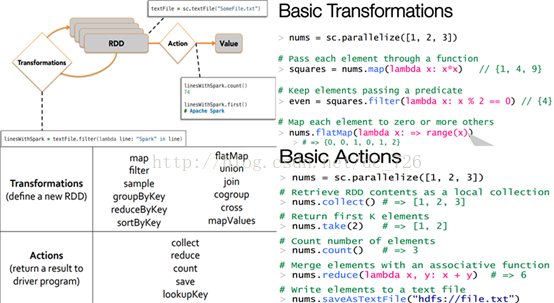
2.2例子
假设网站中的一个WebService出现错误,我们想要从数以TB的HDFS日志文件中找到问题的原因,此时我们就可以用Spark加载日志文件到一组结点组成集群的RAM中,并交互式地进行查询。以下是代码示例:
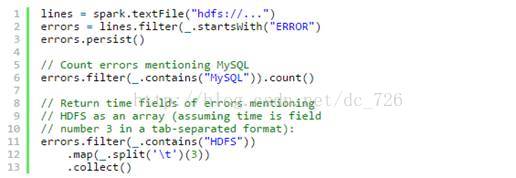
首先行1从HDFS文件中创建出一个RDD,而行2则衍生出一个经过某些条件过滤后的RDD。行3将这个RDD errors缓存到内存中,然而第一个RDD lines不会驻留在内存中。这样做很有必要,因为errors可能非常小,足以全部装进内存,而原始数据则会非常庞大。经过缓存后,现在就可以反复重用errors数据了。我们这里做了两个操作,第一个是统计errors中包含MySQL字样的总行数,第二个则是取出包含HDFS字样的行的第三列时间,并保存成一个集合。
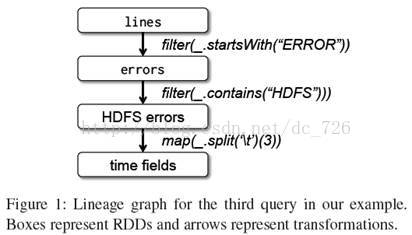
这里要注意的是前面曾经提到过的Spark的延迟处理。Spark调度器会将filter和map这两个转换保存到管道,然后一起发送给结点去计算。
2.3优势
RDD与DSM(distributed shared memory)的最大不同是:RDD只能通过粗粒度转换来创建,而DSM则允许对每个内存位置上数据的读和写。在这种定义下,DSM不仅包括了传统的共享内存系统,也包括了像提供了共享DHT(distributed hash table)的Piccolo以及分布式数据库等。所以RDD相比DSM有着下面这些优势:
Ø 高效的容错机制:没有检查点(checkpoint)开销,能够通过世族关系还原。而且还原只涉及了丢失数据分区的重计算,并且重算过程可以在不同结点并行进行,而无需回滚整个系统。
Ø 结点落后问题的缓和(mitigate straggler):RDD的不可变性使得系统能够运行类似MapReduce备份任务,来缓和慢结点。这在DSM系统中却难以实现,因为多个相同任务一起运行会访问同样的内存数据而相互干扰。
Ø 批量操作:任务能够根据数据本地性(data locality)被分配,从而提高性能。
Ø 优雅降级(degrade gracefully):当内存不足时,大分区会被溢出到磁盘,提供与其他现今的数据并行计算系统类似的性能。
2.4应用场景
RDD最适合那种在数据集上的所有元素都执行相同操作的批处理式应用。在这种情况下,RDD只需记录世族图谱中的每个转换就能还原丢失的数据分区,而无需记录大量的数据操作日志。所以RDD不适合那些需要异步、细粒度更新状态的应用,比如Web应用的存储系统,或增量式的Web爬虫等。对于这些应用,使用具有事务更新日志和数据检查点的数据库系统更为高效。
3 RDD表现形式
3.1深入RDD
使用RDD作为抽象的一个挑战就是:选择一种合适的表现形式,来追踪横跨众多转换的RDD世族关系。在Spark中,我们使用一种简单的、基于图的表现形式,使得Spark在无需为每个转换都增加特殊的处理逻辑的情况下,就能支持大量的转换类型,这大大简化了系统的设计。
总的来说,对于每个RDD都包含五部分信息,即数据分区的集合,能根据本地性快速访问到数据的偏好位置,依赖关系,计算方法,是否是哈希/范围分区的元数据:
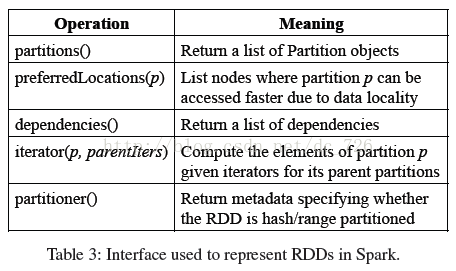
以Spark中内建的几个RDD举例来说:
| 信息/RDD | HadoopRDD | FilteredRDD | JoinedRDD |
| Partitions | 每个HDFS块一个分区,组成集合 | 与父RDD相同 | 每个Reduce任务一个分区 |
| PreferredLoc | HDFS块位置 | 无(或询问父RDD) | 无 |
| Dependencies | 无(父RDD) | 与父RDD一对一 | 对每个RDD进行混排 |
| Iterator | 读取对应的块数据 | 过滤 | 联接混排的数据 |
| Partitioner | 无 | 无 | HashPartitioner |
3.2工作原理
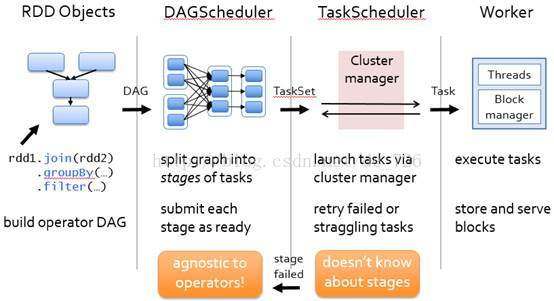
在了解了RDD的概念和内部表现形式之后,那么RDD是如何运行的呢?总高层次来看,主要分为三步:创建RDD对象,DAG调度器创建执行计划,Task调度器分配任务并调度Worker开始运行。
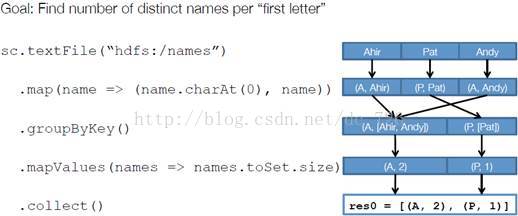
以下面一个按A-Z首字母分类,查找相同首字母下不同姓名总个数的例子来看一下RDD是如何运行起来的。
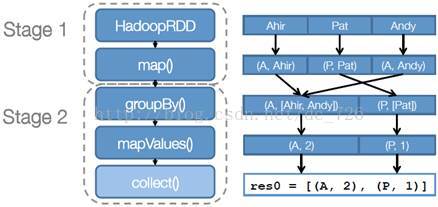
步骤1:创建RDD。上面的例子除去最后一个collect是个动作,不会创建RDD之外,前面四个转换都会创建出新的RDD。因此第一步就是创建好所有RDD(内部的五项信息)。
步骤2:创建执行计划。Spark会尽可能地管道化,并基于是否要重新组织数据来划分阶段(stage),例如本例中的groupBy()转换就会将整个执行计划划分成两阶段执行。最终会产生一个DAG(directed acyclic graph,有向无环图)作为逻辑执行计划。
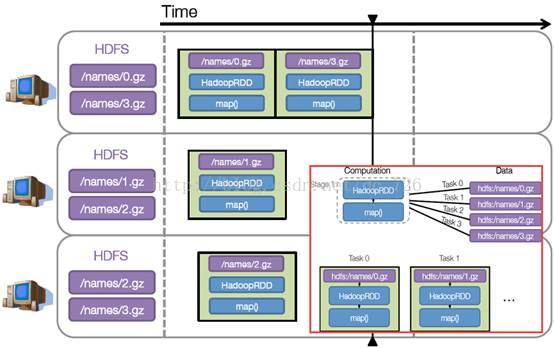
步骤3:调度任务。将各阶段划分成不同的任务(task),每个任务都是数据和计算的合体。在进行下一阶段前,当前阶段的所有任务都要执行完成。因为下一阶段的第一个转换一定是重新组织数据的,所以必须等当前阶段所有结果数据都计算出来了才能继续。
假设本例中的hdfs://names下有四个文件块,那么HadoopRDD中partitions就会有四个分区对应这四个块数据,同时preferedLocations会指明这四个块的最佳位置。现在,就可以创建出四个任务,并调度到合适的集群结点上。
3.3混排
(待补充:关于混排(Shuffle)是如何执行的)
3.4宽窄依赖
在设计RDD的接口时,一个有意思的问题是如何表现RDD之间的依赖。在RDD中将依赖划分成了两种类型:窄依赖(narrow dependencies)和宽依赖(wide dependencies)。窄依赖是指父RDD的每个分区都只被子RDD的一个分区所使用。相应的,那么宽依赖就是指父RDD的分区被多个子RDD的分区所依赖。例如,map就是一种窄依赖,而join则会导致宽依赖(除非父RDD是hash-partitioned,见下图)。
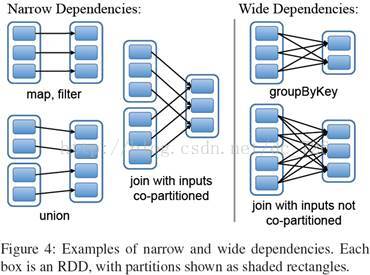
这种划分有两个用处。首先,窄依赖支持在一个结点上管道化执行。例如基于一对一的关系,可以在filter之后执行map。其次,窄依赖支持更高效的故障还原。因为对于窄依赖,只有丢失的父RDD的分区需要重新计算。而对于宽依赖,一个结点的故障可能导致来自所有父RDD的分区丢失,因此就需要完全重新执行。因此对于宽依赖,Spark会在持有各个父分区的结点上,将中间数据持久化来简化故障还原,就像MapReduce会持久化map的输出一样。
4内部实现
4.1调度器
Spark的调度器类似于Dryad的,但是增加了对持久化RDD分区是否在内存里的考虑。重温一下前面例子里介绍过的:调度器会根据RDD的族谱创建出分阶段的DAG;每个阶段都包含尽可能多的具有窄依赖的变换;具有宽依赖的混排操作是阶段的边界;调度器根据数据本地性分派任务到集群结点上。
4.2解释器集成
(待补充)
4.3内存管理
Spark支持三种内存管理方式:Java对象的内存存储,序列化数据的内存存储,磁盘存储。第一种能提供最快的性能,因为JVM能够直接访问每个RDD对象。第二种使用户在内存空间有限时,能选择一种比Java对象图更加高效的存储方式。第三种则对大到无法放进内存,但每次重新计算又很耗时的RDD非常有用。
同时,当有新的RDD分区被计算出来而内存空间又不足时,Spark使用LRU策略将老分区移除到磁盘上。
4.4检查点支持
尽管RDD的Lineage可以用来还原数据,但这通常会非常耗时。所以将某些RDD持久化到磁盘上会非常有用,例如前面提到过的,宽依赖的中间数据。对于Spark来说,对检查点的支持非常简单,因为RDD都是不可变的。所以完全可以在后台持久化RDD,而无需暂停整个系统。














 1078
1078











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









