







第一个线索哪来的就不用探究了,但是一个案件必定是由大量的证据才能定案的。
每当我们的线人提供了一点点的小信息,我们都要自己分析,然后进行二次的甄选。
这必定是不合格的警探---我要的只是葫芦。
因为想要葫芦二区种植,但是种植的又不够全面,到头来除了证明自己SB以外没有其他。
要葫芦?两个办法:
1. 找人买
2. 找人种
找人买的话拿到的就只是成品,其中的猫腻也就不好把控了。
招人种,不用自己动手,但是能够清楚细节,学的全面了还能自己动手。
所以老爷们,能找到管家,那就别找临时工保姆,要不孩子不安全。
聪明人的聪明做法从来都不是吝啬传播知识,虽然能求的人只有你,但是你会因此忙碌不堪,还会被人怀恨在心。
在愚者中散播智慧,甄选代言人,就能够更好地管理,也不会让自己过于操劳。
所以,关键在于让手下的人能够拥有智慧。
就是传销嘛,发展下线就行了,反正最后大头都是你的,坐等收钱就行。
当捕捉回来一个网页,我们要先分类,辨别资源和链接,然后开展二次探索?
可以,但是真的太low了。
既然后潜入了组织,频繁的接头太容易暴露了吧,所以呢,让他们自己处理就好。
反正葫芦到手就行了,那些屁事怎敢劳我大驾,你说是不。
这个东西不陌生吧,这明显就是下一步的线索啊。
所以呢,我们给线人两个任务好了(反正累不着我)。
1. 根据线索找资源
2. 根据线索挖掘新线索
当然了,这都建立在解析线索的基础上。
所以总的应该是四部曲
1. 获取网页
2. 解析网页
3. 下载资源
4. 筛选新链接
只有让卧底深入的潜伏,资源才会完整。
现在来试试。
获取资源
from urllib import request
def getPage(url):
req = request.Request(url)
req.add_header("User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36")
response =request.urlopen(req)
page= response.read().decode()
return page
print(getPage('http://www.baidu.com'))解析资源
解析的方式呢,每个都是不一样的,我们都没办法有一个统一的标准。
用豆瓣电影top250来试试吧。
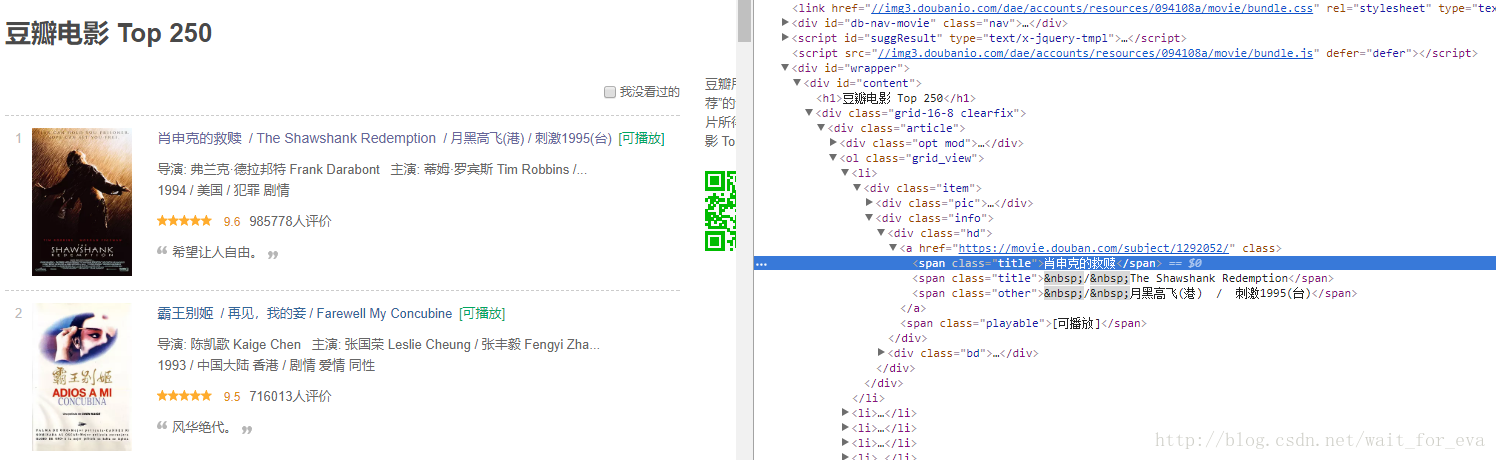
大概是这样的
r'(?<=<span class="title">).*?(?=</span>)'import re
def getResource(page):
regex = re.compile(r'(?<=<span class="title">).*?(?=</span>)')
resource = regex.findall(page)
return resource两个部分整体测试一下
from urllib import request
import re
def getPage(url):
req = request.Request(url)
req.add_header("User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36")
response =request.urlopen(req)
page= response.read().decode()
return page
def getResource(page):
regex = re.compile(r'(?<=<span class="title">).*?(?=</span>)')
resource = regex.findall(page)
return resource
print(getResource(getPage('https://movie.douban.com/top250')))['肖申克的救赎', ' / The Shawshank Redemption'......]输出
['肖申克的救赎', ' / The Shawshank Redemption'.......]
 肯定不是我们需要的,所以完整版应该是
def getResource(page):
regex = re.compile(r'(?<=<span class="title">).*?(?=</span>)')
resource = regex.findall(page)
return [x.strip(' / ') for x in resource]return [x.strip(' / ') for x in resource]
代码不显示好像。
资源保存
就只抓一个名字,评分啦,概述啦,先不管。
def saveResource(source_list):
with open(file='top250.txt',mode='wb') as f:
for source in source_list:
f.write(bytes(source+'\n',encoding='utf-8'))写个文件这么麻烦,其实不怪我,请听我一一道来:
1. 这傻东西不会换行,所以得手动加换行
2. 这个东西呢,又矫情,要认编码,我就干脆byte放进去,就是故意的
这就写进去了,大概这样的
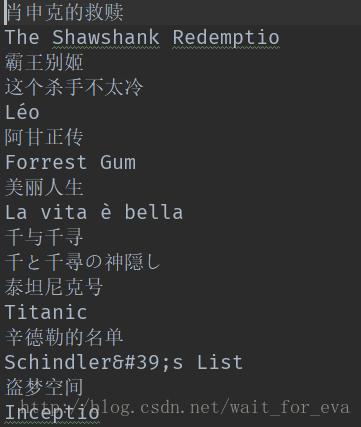
恩,没错了。就是有些名字还是有多余的东西。
这个你们看着办,要不等会我想办法。
跟踪链接
找新链接呢,有两种办法
1. 生成新链接
2. 捕获新链接
第一种呢,就是找规律,自己定,知道函数表达式了,后面的数要算出来就不是大问题了吧。
第二种呢,就是从网页中自己找。
先观察一下。
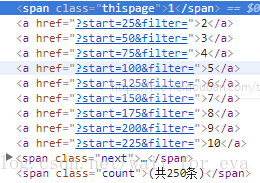
就是每次步进25嘛,不过要注意极限值。
可以这样生成
def createAddr():
head = 'https://movie.douban.com/top250'
count = 0
tail = '?start={}&filter='
while count <= 225:
yield head+tail.format(count)
count += 25
addrs = createAddr()
for addr in addrs:
print(addr)测试结果
可以对比一下,没错。
用抓的试一试。
难受的一逼,不过幸好弄出来了,弄出来是真的舒服,弄什么?粘稠不粘稠?
不告诉你,反正舒服多了。
def nextAddr(page):
head = 'https://movie.douban.com/top250'
regex1 = re.compile(r'(?<=<span class="thispage">\d</span>\n\s{16}\n\s{12}<a href=")\?start=\d{2,3}\&filter=(?=" >\d{1,2}</a>)')
#regex2 = re.compile(r'(?<=<span class="thispage">\d</span>\n\s{14}\n\s{12}<a href=")\?start=\d{2,3}\&filter=(?=" >\d{1,2}</a>)')
find = regex1.findall(page)
tail = find[0]
addr = head + tail
return addr
def test_nextAddr():
link = 'https://movie.douban.com/top250'
try:
while True:
print('link:{}'.format(link))
page = getPage(link)
link =nextAddr(page)
except:
print('over')
return
test_nextAddr()查询和测试方法都在这,结果如下
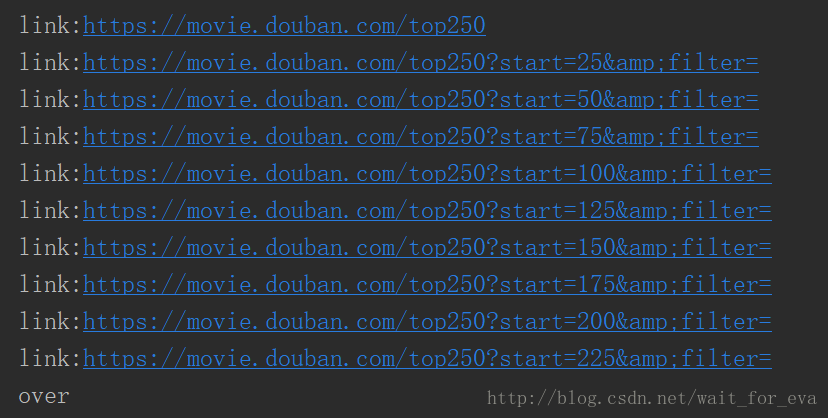
别问我为什么有个没用的regex2
regex1 = re.compile(r'(?<=<span class="thispage">\d</span>\n\s{16}\n\s{12}<a href=")\?start=\d{2,3}\&filter=(?=" >\d{1,2}</a>)') #regex2 = re.compile(r'(?<=<span class="thispage">\d</span>\n\s{14}\n\s{12}<a href=")\?start=\d{2,3}\&filter=(?=" >\d{1,2}</a>)')
亲身经历,这就是在大批量时,查询不方便,就是特么的过拟合。
不是一定匹配,限制就是特别大,波动允许范围很小。
简直蛋疼,不信下次用xpath试一下,简直不要太舒服。
接下来?组装变形金刚呗。
逻辑组织
def begin():
link = 'https://movie.douban.com/top250'
while link:
page = getPage(link)
resource = getResource(page)
saveResource(resource)
link = nextAddr(page)1. 访问网页
2. 获取资源
3. 处理资源
4. 更新链接
5. 循环执行
整体代码如下
from urllib import request
import re
def getPage(url):
req = request.Request(url)
req.add_header("User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36")
response =request.urlopen(req)
page= response.read().decode()
return page
def getResource(page):
regex = re.compile(r'(?<=<span class="title">).*?(?=</span>)')
resource = regex.findall(page)
return [x.strip(' / ') for x in resource]
def saveResource(source_list):
with open(file='top250.txt',mode='wb') as f:
for source in source_list:
f.write(bytes(source+'\n',encoding='utf-8'))
def createAddr():
head = 'https://movie.douban.com/top250'
count = 0
tail = '?start={}&filter='
while count <= 225:
yield head+tail.format(count)
count += 25
def nextAddr(page):
head = 'https://movie.douban.com/top250'
regex1 = re.compile(r'(?<=<span class="thispage">\d</span>\n\s{16}\n\s{12}<a href=")\?start=\d{2,3}\&filter=(?=" >\d{1,2}</a>)')
#regex2 = re.compile(r'(?<=<span class="thispage">\d</span>\n\s{14}\n\s{12}<a href=")\?start=\d{2,3}\&filter=(?=" >\d{1,2}</a>)')
find = regex1.findall(page)
if not find:
return None
tail = find[0]
addr = head + tail
return addr
def test_nextAddr():
link = 'https://movie.douban.com/top250'
try:
while True:
print('link:{}'.format(link))
page = getPage(link)
link =nextAddr(page)
except:
print('over')
return
def begin():
link = 'https://movie.douban.com/top250'
while link:
page = getPage(link)
resource = getResource(page)
saveResource(resource)
link = nextAddr(page)
if __name__ == '__main__':
begin()我就不注释了,都解释这么多了。
对了,不是说任务多了执行慢么,开线程吧
线程执行
def task(link):
page = getPage(link)
resource = getResource(page)
saveResource(resource)
if __name__ == '__main__':
links = createAddr()
for link in links:
t = threading.Thread(target=task,args=(link,))
t.start()
t.join()我为什么要多些一个方法?
你傻啊,前面的是从网页抓的链接,怎么多线程开启啊。
没有因果啦,你给你妈拉郎配,认识你爹,然后生出了你?
无限循环?那么问题来了,你爹还小的时候你怎么出生的?莫非,你不是亲生的?
不吹了。
线程就是两个参数,target(目标函数),args(参数),注意args传入的是元组,哪怕一个也要加逗号。
join阻塞,等待线程执行完毕。
还能有啥。
手动爬虫基本也没了,就是除了资源外还能跟踪新链接,然后多线程。
发现标题有点故弄玄虚,不过算了,不改了。
这说的不就是深入抓么,没表明我文章主旨?
进来才是有缘人嘛,才能获取我努力的精...................................................................................华啊(反正也没谁看,乐意就谢谢而已)。
还要,前面抓取的名称有些不要的字符的话,strip的时候全放一块就好,反正strip就是去除匹配到的,没有的话不会乱动的。
但是去除的东西和抓取的东西有一致的而且在边上的话,那就有点问题了。
不过这不是重点,随意了。
球头吗得,最后一点啊,如果线程涉及公共资源的时候,好比文件,一定要加锁保护好,虽然我没做。
没有加锁的话,后面的文件写入会覆盖前面的。
单线程的话最好也用整体的,每次打开文件读写也麻烦,浪费,关键也会覆盖。
我之前测试也是覆盖的,代码贴的也不知道是不是没问题,逻辑绝对正确,就是覆盖问题。
解决办法
1. 确认模式
2. 刷缓冲
模式:a,b,r,w+...
自己组合把,带上加号,具体随便百度,一般a+绝对没问题,用byte的话ab+
刷缓冲:f.flush()
每次写入的信息,都在缓冲区,一般等缓冲区慢了,或者要关闭了才会将缓冲区信息写入文件。
为了保证数据不丢失,发生啥幺蛾子,反正自己手动刷出去就没事了。
不过刷的频繁的话性能有影响,自己斟酌。
over














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









