









cuda concept
In November 2006, NVIDIA introduced CUDA®, a general purpose parallel computing platform and programming model that leverages the parallel compute engine in NVIDIA GPUs to solve many complex computational problems in a more efficient way than on a CPU.
main concept of cuda
主机
将CPU及系统的内存(内存条)称为主机。
设备
将GPU及GPU本身的显示内存称为设备。
线程(Thread)
一般通过GPU的一个核进行处理。
线程块(Block)
1. 由多个线程组成(可以表示成一维,二维,三维)。即线程的集合叫做线程块。
2. 各block是并行执行的,block间无法通信,也没有执行顺序。
3. 注意线程块的数量限制为不超过65535(硬件限制)。
For convenience, threadIdx is a 3-component vector, so that threads can be identified using a one-dimensional, two-dimensional, or three-dimensional thread index, forming a one-dimensional, two-dimensional, or three-dimensional block of threads, called a thread block. This provides a natural way to invoke computation across the elements in a domain such as a vector, matrix, or volume.
线程格(Grid)
由多个线程块组成(可以表示成一维,二维,三维)。即线程块的集合叫线程格。
Blocks are organized into a one-dimensional, two-dimensional, or three-dimensional grid of thread blocks. The number of thread blocks in a grid is usually dictated by the size of the data being processed or the number of processors in the system, which it can greatly exceed.
线程束
在CUDA架构中,线程束是指一个包含32个线程的集合,这个线程集合被“编织在一起”并且“步调一致”的形式执行。在程序中的每一行,线程束中的每个线程都将在不同数据上执行相同的命令。The multiprocessor creates, manages, schedules, and executes threads in groups of 32 parallel threads called warps. Individual threads composing a warp start together at the same program address, but they have their own instruction address counter and register state and are therefore free to branch and execute independently. The term warp originates from weaving, the first parallel thread technology. A half-warp is either the first or second half of a warp. A quarter-warp is either the first, second, third, or fourth quarter of a warp.
核函数(Kernel)
1. 在GPU上执行的函数通常称为核函数。
2. 一般通过标识符__global__修饰,调用通过<<<参数1,参数2>>>,用于说明内核函数中的线程数量,以及线程是如何组织的。尖括号中的参数是传递给运行时系统,进行设置GPU上线程和进程的组织方式,并告诉运行时如何启动设备代码。尖括号中的参数并不是传递给设备代码运行所需要的参数。设备代码核函数运行的参数传递在圆括号里面指定,就像标准的函数一样。参数1说明GPU设备在执行核函数的时候使用的并行线程块的数量。参数2说明GPU设备在执行核函数的时候,一个线程块中包含多少个线程。
3. 以线程格(Grid)的形式组织,每个线程格由若干个线程块(block)组成,而每个线程块又由若干个线程(thread)组成。
4. 是以block为单位执行的。
5. 叧能被在主机端代码中调用。
6. 调用时必须声明内核函数的执行参数。
7. 在编程时,必须先为kernel函数中用到的数组或变量分配好足够的空间,再调用kernel函数,否则在GPU计算时会发生错误,例如越界或报错,甚至导致蓝屏和死机。
8. CUDA编译器和运行时将负责实现从主机代码中调用设备代码的功能。CUDA C extends C by allowing the programmer to define C functions, called kernels, that, when called, are executed N times in parallel by N different CUDA threads, as opposed to only once like regular C functions.
A kernel is defined using the __global__declaration specifier and the number of CUDA threads that execute that kernel for a given kernel call is specified using a new <<<…>>>execution configuration syntax (see C Language Extensions). Each thread that executes the kernel is given a unique thread ID that is accessible within the kernel through the built-in threadIdx variable.
As an illustration, the following sample code adds two vectors A and B of size N and stores the result into vector C:
// Kernel definition
__global__ void VecAdd(float* A, float* B, float* C) {
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main() {
...
// Kernel invocation with N threads
VecAdd<<<1, N>>>(A, B, C);
...
}dim3结构类型
1. dim3是基亍uint3定义的矢量类型,相当亍由3个unsigned int型组成的结构体。uint3类型有三个数据成员unsigned int x; unsigned int y; unsigned int z;
2. 可使用亍一维、二维或三维的索引来标识线程,构成一维、二维或三维线程块。
3. dim3结构类型变量用在核函数调用的<<<,>>>中。
4. 对于一维的block,线程的threadID=threadIdx.x。
5. 对于大小为(blockDim.x, blockDim.y)的 二维 block,线程的`threadID=threadIdx.x+threadIdx.y*blockDim.x。`
6. 对于大小为(blockDim.x, blockDim.y, blockDim.z)的 三维 block,线程的`threadID=threadIdx.x+threadIdx.y*blockDim.x+threadIdx.z*blockDim.x*blockDim.y。`
7. 对于计算线程索引偏移增量为已启动线程的总数。如`stride = blockDim.x * gridDim.x; threadId += stride。`一维线程块(N表示数据的个数)
int offset = threadIdx.x+blockIdx.x*blockDim.x;
增量:blockDim.x*gridDim.x
__Pseudocode{
int offset = threadIdx.x * blockIdx.x * blockDim.x;
while(offset<N){
//...
//...
offset += blockDim.x * gridDim.x;
}
}二维线程块
int x=threadIdx.x+blockIdx.x*blockDim.x;
int y=threadIdx.y+blockIdx.y*blockDim.y;
int offset=y*blockDim.x*gridDim.x+x;
增量为:blockDim.x*blockDim.y*gridDim.x*gridDim.y
__Pseudocode{
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x+y*blockDim.x * gridDim.x;
while(offset< N){
//...
//...
offset += blockDim.x * blockDim.y * gridDim.x*gridDim.y;
}
}三维线程块
int x = threadIdx.x+blockIdx.x*blockDim.x;
int y = threadIdx.y+blockIdx.y*blockDim.y;
int z = threadIdx.z+blockIdx.z*blockDim.z;
int offset=(z*blockDim.y*gridDim.y+y)*blockDim.x*gridDim.x+x;
增量为:blockDim.x*gridDim.x*blockDim.y*gridDim.y*blockDim.z*gridDim.z;
__Pseudocode{
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int z = threadIdx.z + blockIdx.z * blockDim.z;
int offset = x+ blockDim.x * gridDim.x * (y + blockDim.y * gridDim.y*z);
while(offset < N){
//...
//...
offset += blockDim.x * blockDim.y * blockDim.z * gridDim.x * gridDim.y *gridDim.z;
}
}This type is an integer vector type based on uint3 that is used to specify dimensions. When defining a variable of type dim3, any component left unspecified is initialized to 1.
线程发散(Thread Divergence)
当某些线程需要执行一条指令,而其他线程不需要执行的时候,这种现象就称为线程发散。
__syncthreads()
Threads within a block can cooperate by sharing data through some shared memory and by synchronizing their execution to coordinate memory accesses. More precisely, one can specify synchronization points in the kernel by calling the __syncthreads() intrinsic function; __syncthreads() acts as a barrier at which all threads in the block must wait before any is allowed to proceed.
CUDA架构将确保,除非同一个线程块中的每一个线程都执行了__syncthreads(),否则没有任何线程能执行__syncthreads()函数之后的指令。遗憾的是,如果__syncthreads()位于发散分支中,那么一些线程永远都无法执行__syncthreads()。因此,由于要确保在每个线程执行完__syncthreads()后才能执行后面的语句,因此硬件将使这些线程保持等待。一直等,一直等,永久地等待下去。
threadIdx(线程索引)
线程thread的ID索引;如果线程是一维的那么就取threadIdx.x,二维的还可以多取到一个值threadIdx.y,以此类推到三维threadIdx.z。
This variable is of type uint3 (see char, short, int, long, longlong, float, double ) and contains the thread index within the block.
blockIdx(线程块的索引)
线程块的ID索引;同样有blockIdx.x,blockIdx.y,blockIdx.z。
This variable is of type uint3 (see char, short, int, long, longlong, float, double) and contains the block index within the grid.
gridDim(网格的大小)
线程格的维度,同样有gridDim.x,gridDim.y,gridDim.z。
This variable is of type dim3 (see dim3) and contains the dimensions of the grid.
blockDim(线程块的大小)
This variable is of type dim3 (see dim3) and contains the dimensions of the block.
warpSize(线程束)
This variable is of type int and contains the warp size in threads (see SIMT Architecture for the definition of a warp).
Function Type Qualifiers(函数修饰符)
Function type qualifiers specify whether a function executes on the host or on the device and whether it is callable from the host or from the device.
__global__,表明被修饰的函数在设备上执行,但在主机上调用。
The _global_ qualifier declares a function as being a kernel. Such a function is:
- Executed on the device,
- Callable from the host,
- Callable from the device for devices of compute capability 3.x (see CUDA Dynamic Parallelism for more details).
NOTE:
__global__ functions must have void return type.
Any call to a __global__ function must specify its execution configuration as described in Execution Configuration.
A call to a __global__ function is asynchronous, meaning it returns before the device has completed its execution.
__device__,表明被修饰的函数在设备上执行,但只能在其他__device__函数或者__global__函数中调用。
The __device__ qualifier declares a function that is:
- Executed on the device,
- Callable from the device only.
__host__
The host qualifier declares a function that is:
- Executed on the host,
- Callable from the host only.
It is equivalent to declare a function with only the __host__ qualifier or to declare it without any of the __host__, __device__, or __global__ qualifier; in either case the function is compiled for the host only.
NOTE:
The __global__ and __host__ qualifiers cannot be used together.
The __device__ and __host__ qualifiers can be used together however, in which case the function is compiled for both the host and the device. The __CUDA_ARCH__ macro introduced in Application Compatibility can be used to differentiate code paths between host and device:
__host__ __device__ func() {
#if __CUDA_ARCH__ >= 500
// Device code path for compute capability 5.x
#elif __CUDA_ARCH__ >= 300
// Device code path for compute capability 3.x
#elif __CUDA_ARCH__ >= 200
// Device code path for compute capability 2.x
#elif !defined(__CUDA_ARCH__)
// Host code path
#endif
}__ noinline__ and __forceinline__
The compiler inlines any device function when deemed appropriate.
The __noinline__ function qualifier can be used as a hint for the compiler not to inline the function if possible. The function body must still be in the same file where it is called.
The __forceinline__ function qualifier can be used to force the compiler to inline the function.
Variable Type Qualifiers(变量类型修饰符)
Variable type qualifiers specify the memory location on the device of a variable.
An automatic variable declared in device code without any of the __device__, __shared__ and __constant__ qualifiers described in this section generally resides in a register. However in some cases the compiler might choose to place it in local memory, which can have adverse performance consequences as detailed in Device Memory Accesses.
__device__
The __device__ qualifier declares a variable that resides on the device.
At most one of the other type qualifiers defined in the next two sections may be used together with __device__ to further specify which memory space the variable belongs to. If none of them is present, the variable:
- Resides in global memory space.
- Has the lifetime of an application.
- Is accessible from all the threads within the grid and from the host through the runtime library (cudaGetSymbolAddress() / cudaGetSymbolSize() / cudaMemcpyToSymbol() / cudaMemcpyFromSymbol()).
__constant__
The __constant__ qualifier, optionally used together with __device__, declares a variable that:
- Resides in constant memory space,
- Has the lifetime of an application,
- Is accessible from all the threads within the grid and from the host through the runtime library (cudaGetSymbolAddress() / cudaGetSymbolSize() / cudaMemcpyToSymbol() / cudaMemcpyFromSymbol()).
__shared__
The shared qualifier, optionally used together with device, declares a variable that:
- Resides in the shared memory space of a thread block,
- Has the lifetime of the block,
- Is only accessible from all the threads within the block.
When declaring a variable in shared memory as an external array such as
extern __shared__ float shared[];the size of the array is determined at launch time (see Execution Configuration)
__managed__
The __managed__ qualifier, optionally used together with __device__, declares a variable that:
- Can be referenced from both device and host code, e.g., its address can be taken or it can be read or written directly from a device or host function.
- Has the lifetime of an application.
__restrict__
nvcc supports restricted pointers via the restrict keyword.
Restricted pointers were introduced in C99 to alleviate the aliasing problem that exists in C-type languages, and which inhibits all kind of optimization from code re-ordering to common sub-expression elimination.
Here is an example subject to the aliasing issue, where use of restricted pointer can help the compiler to reduce the number of instructions:
Memory Model
Parent and child grids share the same global and constant memory storage, but have distinct local and shared memory.
Global Memory
通俗意义上的设备内存。
Zero Copy Memory
Zero-copy system memory has identical coherence and consistency guarantees to global memory, and follows the semantics detailed above. A kernel may not allocate or free zero-copy memory, but may use pointers to zero-copy passed in from the host program.
零拷贝内存实在固定内存的基础之上,进行操作的,故,首先判断设备是否支持重叠操作,即支持固定内存。
void checkDeviceProperties(){
cudaDeviceProp prop;
int deviceID;
cudaGetDevice(&deviceID);
int deviceCount;
cudaGetDeviceCount(&deviceCount);
printf("current system include %d devices....\n", deviceCount);
cudaGetDeviceProperties(&prop, deviceID);
//判断设备是否支持重叠操作,即可以使用固定内存
if (!prop.deviceOverlap){
printf("Device will not handle overlaps,so no speed up from streams\n");
return;
}
else{
printf("Device can handle overlaps,so there are speed up from streams\n");
}
//判断设备是否支持零拷贝内存操作,
if (!prop.canMapHostMemory != 1){
printf("Device cannot map memory...\n");
//return 0;
}
else{
printf("Device can map memory...\n");
}
//判断设备是否是集成显卡GPU
if (!prop.integrated)
{
printf("Device no integrated\n");
}
else{
printf("Device no integrated\n");
}
if (!prop.isMultiGpuBoard){
printf("Device no multigpu\n");
}
else{
printf("Device has multigpu\n");
}
//run_host_alloc_test();
}
//判断设备是否支持零拷贝内存操作
if (!prop.canMapHostMemory != 1){
printf("Device cannot map memory...\n");
//return 0;
}
else{
printf("Device can map memory...\n");
}如果设备要支持零拷贝内存,那么需要在运行时设置(开启)能分配零拷贝内存的状态。通过调用cudaSetDeviceFlags()来实现这个操作。并传递标识值cudaDeviceMapHost来表示我们希望设备映射主机内存。
cudaSetDeviceFlags(cudaDeviceMapHost);可以在CUDA C核函数中直接访问这种类型的主机内存,由于这种内存不需要将数据复制到GPU上,因此也称为零拷贝内存。零拷贝内存的定义是基于固定内存(或者说也锁定内存),这种新型的主机内存能够确保不会交换出物理内存。通过调用cudaHostAlloc()来分配这种内存。
如果要使用零拷贝内存机制,首先需要判断设备是否支持映射主机内存。
在使用标志cudaHostAllocMapped来分配主机内存以后,就可以从GPU中访问这块内存。然而,GPU的虚拟内存空间与CPU是不同的,因此在GPU上访问它们与在CPU上访问它们有着不同的地址,调用cudaHostAlloc()将返回这块内存在CPU上的指针,因此需要调用cudaHostGetDevicePointer()函数来获得这块内存在GPU上的有效指针。
调用cudaThreadSynchronize()将CPU和GPU进行同步。用来确保零拷贝内存的一致性。
int main()
{
cudaDeviceProp prop;
int deviceID;
cudaGetDevice(&deviceID);
cudaGetDeviceProperties(&prop, deviceID);
if (!prop.canMapHostMemory != 1){
printf("Device cannot map memory...\n");
return 0;
}
if (!prop.deviceOverlap){
printf("Device will not handle overlaps,so no speed up from streams\n");
return 0;
}
else{
printf("Device can handle overlaps,so there are speed up from streams\n");
}
system("pause");
return 0;
}对于集成GPU,使用零拷贝内存通常都会带来性能提升,因为内存在物理上就与主机是共享的。将缓冲区声明为零拷贝内存的唯一作用就是避免不必要的数据复制。
零拷贝内存同样不例外:每个固定内存都会占用系统的可用物理内存,这最终将降低系统的性能。
当输入内存和输出内存都只能使用一次时,那么在独立GPU上使用零拷贝内存将带来性能提升。
但是,由于GPU不会缓存零拷贝内存的内容,如果多次读取内存,那么最终将得不偿失。
每个GPU都有自己的线程。
Constant Memory
Constants are immutable(不可变的) and may not be modified from the device, even between parent and child launches. That is to say, the value of all __constant__ variables must be set from the host prior to launch. Constant memory is inherited automatically by all child kernels from their respective parents.
事实上,正是这种强大的计算优势激发了人们开始研究如何在图形处理器上执行通用计算。由于在GPU上包含有数百个数学计算单元,因此性能瓶颈通常并不在于芯片的数学计算吞吐量,而是在于芯片的内存带宽。CUDA C除了支持全局内存和共享内存,还支持另一种类型的内存。即常量内存。从常量内存的名字就可以看出来,常量内存用于保存在核函数执行期间不会发生变化的数据。常量内存采取了不同于标准全局内存的处理方式。在某些情况中,用常量内存来替换全局内存能有效地减少内存带宽。
与标准的全局内存相比,常量内存存在着一些限制,但是在某些情况中,使用常量内存将提升应用程序的性能。特别是,当线程束中的所有线程都访问相同的只读数据时,将获得额外的性能提升。在这种访问模式中使用常量内存可以节约内存带宽,不仅是因为这种模式可以读取操作在半线程束中广播,而且还因为在芯片上包含了常量内存缓存。
在许多算法中,内存带宽都是一种瓶颈,因此采用一些机制来改善这种情况是非常有用的。
Taking the address of a constant memory object from within a kernel thread has the same semantics as for all CUDA programs, and passing that pointer from parent to child or from a child to parent is naturally supported.
Shared and Local Memory
Shared and Local memory is private to a thread block or thread, respectively, and is not visible or coherent between parent and child. Behavior is undefined when an object in one of these locations is referenced outside of the scope within which it belongs, and may cause an error.
The NVIDIA compiler will attempt to warn if it can detect that a pointer to local or shared memory is being passed as an argument to a kernel launch. At runtime, the programmer may use the __isGlobal() intrinsic to determine whether a pointer references global memory and so may safely be passed to a child launch.
Note that calls to cudaMemcpy*Async() or cudaMemset*Async() may invoke new child kernels on the device in order to preserve stream semantics. As such, passing shared or local memory pointers to these APIs is illegal and will return an error.Local Memory
Local memory is private storage for an executing thread, and is not visible outside of that thread. It is illegal to pass a pointer to local memory as a launch argument when launching a child kernel. The result of dereferencing such a local memory pointer from a child will be undefined.
For example the following is illegal, with undefined behavior if x_array is accessed by child_launch:
int x_array[10]; // Creates x_array in parent's local memory child_launch<<< 1, 1 >>>(x_array);It is sometimes difficult for a programmer to be aware of when a variable is placed into local memory by the compiler. As a general rule, all storage passed to a child kernel should be allocated explicitly from the global-memory heap, either with cudaMalloc(), new() or by declaring __device__ storage at global scope. For example:
// Correct - "value" is global storage
__device__ int value;
__device__ void x()
{
value = 5;
child<<< 1, 1 >>>(&value);
}// Invalid - "value" is local storage
__device__ void y() {
int value = 5;
child<<< 1, 1 >>>(&value);
}
Texture Memory
Writes to the global memory region over which a texture is mapped are incoherent with respect to texture accesses. Coherence for texture memory is enforced at the invocation of a child grid and when a child grid completes. This means that writes to memory prior to a child kernel launch are reflected in texture memory accesses of the child. Similarly, writes to memory by a child will be reflected in the texture memory accesses by a parent, but only after the parent synchronizes on the child’s completion. Concurrent accesses by parent and child may result in inconsistent data.
纹理缓存是专门为那些在内存中访问模式中存在大量空间局部性(Spatial Locality)的图形应用程序而设计的。在某个计算应用程序中,这意味着一个线程读取的位置可能与邻近线程读取的位置”非常接近”。
- 位置:设备内存
- 目的:能够减少对内存的请求并提供高效的内存带宽。是专门为那些在内存访问模式中存在大量空间局部性的图形应用程序设计,意味着一个线程读取的位置可能与邻近线程读取的位置“非常接近”。如下图:
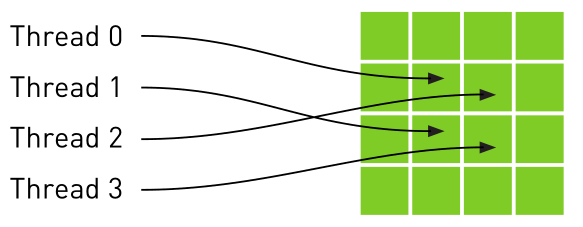
–
3. 纹理变量(引用)必须声明为文件作用域内的全局变量。
4. 形式:分为一维纹理内存 和 二维纹理内存。
4.1. 一维纹理内存
4.1.1. 用texture<类型>类型声明,如texture texIn。
4.1.2. 通过cudaBindTexture()绑定到纹理内存中。
4.1.3. 通过tex1Dfetch()来读取纹理内存中的数据。
4.1.4. 通过cudaUnbindTexture()取消绑定纹理内存。
–
4.2. 二维纹理内存
4.2.1. 用texture<类型,数字>类型声明,如texture<float,2> texIn。
4.2.2. 通过cudaBindTexture2D()绑定到纹理内存中。
4.2.3. 通过tex2D()来读取纹理内存中的数据。
4.2.4. 通过cudaUnbindTexture()取消绑定纹理内存。
固定内存(Pinned Memory)
CUDA运行时提供了自己独有的机制来分配主机内存:cudaHostAlloc()。事实上,malloc()分配的内存与cudaHostAlloc()分配的内存之间存在着一个重要的差异。C库函数malloc()将分配标准的、可分页的(Pagable)主机内存。而cudaHostAlloc()将分配页锁定的主机内存。页锁定内存也称为固定内存(Pinned Memory)或者不可分页内存。它有一个重要的属性,操作系统将不会对这块内存分页并交换到磁盘上。从而确保了该内存始终驻留在物理内存中。因此,操作系统能够安全地使某个应用程序访问该内存的物理地址,因为这块内存将不会被破坏或者重新定位。
事实上,当使用可分页内存进行复制时,CUDA驱动程序仍然会通过DAM内存把数据传输给GPU。因此,复制操作将执行两遍,第一遍从可分页内存中复制数据到一块“临时的”也锁定内存,然后再从这个页锁定内存中将数据复制给GPU的内存。
固定内存是一把双刃剑,当使用固定内存时,你的电脑将失去虚拟内存的所有功能。特别是,在应用程序中使用每个页锁定内存时都需要分配物理内存,因为这些物理内存不能交换到磁盘上。这就意味着,与使用标准的malloc()调用相比,系统将更快地耗尽物理内存。因此,应用程序在物理内存较少的机器上会运行失败。而且意味着应用程序将影响已在系统上运行的其他应用程序的性能。
可移动的固定内存
固定内存是对于单个CPU线程来说是“固定的”。也就是说,如果某个线程分配固定内存,那么这些内存只是对于分配它们的线程来说是页锁定的。如果在CPU线程之间共享指向固定内存的指针,那么其他的线程都将会认为这块”固定内存”视为标准的、可分页的内存。
可移动的固定内存的含义:主机的多个线程之间移动这块内存(即主机多个线程之间共享这块固定内存),并且每个线程都将其视为固定内存。需要指定一个新的标志:cudaHostAllocPortable。
固定内存《《《零拷贝内存《《《可移动的固定内存固定内存:解决数据位置变化的问题。
零拷贝内存:解决CPU和GPU之间拷贝复制数据的问题。
可移动的固定内存:解决多个GPU之间共享数据的问题。
Streams
Applications manage the concurrent operations described above through streams. A stream is a sequence of commands (possibly issued by different host threads) that execute in order. Different streams, on the other hand, may execute their commands out of order with respect to one another or concurrently; this behavior is not guaranteed and should therefore not be relied upon for correctness (e.g., inter-kernel communication is undefined).
为了使用GPU的流的特性,首先,我们做的第一件事,就是判断我们的电脑显卡设备是否支持设备重叠功能,选择一个支持设备重叠功能的设备。支持设备重叠功能的GPU才能够在执行一个CUDA C核函数的同时,还能够在设备与主机之间执行复制操作。判断显卡是否支持设备重叠的功能代码如下:
bool getOverlapDevice(){
cudaDeviceProp prop;
int deviceID;
int deviceCount = 0;
cudaGetDeviceCount(&deviceCount);
for (int i = 0; i < deviceCount; i++)
{
cudaGetDeviceProperties(&prop, i);
if (prop.deviceOverlap)
{
return i; //indicates device id
}
}
return -1; //indicates there isn't any device supporting overlap
}CUDA流在加速应用程序方面起着重要的作用,CUDA流表示一个GPU操作队列,并且该队列中的操作将以指定的顺序执行。例如核函数启动、内存复制,以及事件的启动和结束等。将这些操作添加到流的顺序也就是他们的执行顺序。你可以将每个流视为GPU上的一个任务。并且这些任务可以并行执行。(即每个流的执行请块将不受其他的流的影响)。
任何传递给cudaMemcpyAsync()的主机内存指针都必须已经通过cudaHostAlloc()分配好内存。也就是说,只能以异步方式对页锁定内存进行复制操作。
如果想要确保GPU执行完了计算和内存复制等操作,那么就需要将GPU与主机进行同步。也就是说,主机在继续执行之前,首先要等待GPU执行完成。可以调用cudaStreamSyncharonize()并指定想要等待的流。异步操作必须判断CUDA设备是否支持重叠操作。判断设备是否支持计算和内存复制操作的重叠,如果设备支持重叠,那么就可以使用流,进行CUDA设备上的多个流的任务并行操作。
硬件在处理内存复制和核函数执行时分别采用了不同的引擎(内存复制引擎和核函数执行引擎),因此我们需要知道,将操作放入流中队列中的顺序,将影响着CUDA驱动程序调度这些操作以及执行方式。调整好放入流中的顺序将很好地提高内存复制操作和核函数执行的重叠的时间效率。
通过使用多个CUDA流,我们可以使GPU在执行核函数的同时,还能在主机和GPU之间执行复制操作。然而,当采用这种方式是,需要注意两个因素。首先,需要通过cudaHostAlloc()来分配主机内存,因为接下来需要通过cudaMemcpyAsync()对内存复制操作进行排队。而异步复制操作需要在固定缓冲区执行。其次,我们要知道,添加这些操作到流中,其中添加到流中操作的顺序将对内存复制操作和核函数执行的重叠情况产生影响。
通常,应该采用宽度优先或者轮询方式将工作分配到每个流中。
- 扯一扯:并发重点在于一个极短时间段内运行多个不同的任务;并行重点在于同时运行一个任务。
- 任务并行性:是指并行执行两个或多个不同的任务,而不是在大量数据上执行同一个任务。
- 概念:CUDA流表示一个GPU操作队列,并且该队列中的操作将以指定的顺序执行。我们可以在流中添加一些操作,如核函数启动,内存复制以及事件的启动和结束等。这些操作的添加到流的顺序也是它们的执行顺序。可以将每个流视为GPU上的一个任务,并且这些任务可以并行执行。
- 硬件前提:必须是支持设备重叠功能的GPU。支持设备重叠功能,即在执行一个核函数的同时,还能在设备与主机之间执行复制操作。
- 声明与创建:声明cudaStream_t stream;,创建cudaSteamCreate(&stream);。
- cudaMemcpyAsync():前面在cudaMemcpy()中提到过,这是一个以异步方式执行的函数。在调用cudaMemcpyAsync()时,只是放置一个请求,表示在流中执行一次内存复制操作,这个流是通过参数stream来指定的。当函数返回时,我们无法确保复制操作是否已经启动,更无法保证它是否已经结束。我们能够得到的保证是,复制操作肯定会当下一个被放入流中的操作之前执行。传递给此函数的主机内存指针必须是通过cudaHostAlloc()分配好的内存。(流中要求固定内存)
- 流同步:通过cudaStreamSynchronize()来协调。
- 流销毁:在退出应用程序之前,需要销毁对GPU操作进行排队的流,调用cudaStreamDestroy()。
针对多个流:
- 记得对流进行同步操作。
- 将操作放入流的队列时,应采用宽度优先方式,而非深度优先的方式,换句话说,不是首先添加第0个流的所有操作,再依次添加后面的第1,2,…个流。而是交替进行添加,比如将a的复制操作添加到第0个流中,接着把a的复制操作添加到第1个流中,再继续其他的类似交替添加的行为。
- 要牢牢记住操作放入流中的队列中的顺序影响到CUDA驱动程序调度这些操作和流以及执行的方式。
设备指针使用限制:
- 可以将cudaMalloc()分配的指针传递给在设备上执行的函数。
- 可以在设备代码中使用cudaMalloc()分配的指针进行内存块读/写操作。
- 可以将cudaMalloc()分配的指针传递给在主机端上执行的函数。
- 不能在主机代码中使用cudaMalloc()分配的指针进行内存读/写操作。
- cudaMemcpyToSymbol()会将数据复制到常量内存中,而cudaMemcpy()会复制到全局内存中。
- cudaMemset()是在GPU内存上执行,而memset()是在主机内存上运行。
总的来说:
主机指针只能访问主机代码中的内存,而设备指针也只能访问设备代码中的内存。
GPU计算的应用前景在很大程度上取决于能否从许多问题中发掘出大规模并行性。
NOTE:
- 当线程块的数量为GPU中处理器数量的2倍时,将达到最优性能。
- 核函数执行的第一个计算就是计算输入数据的偏移。每个线程的起始偏移都是0到线程数量减1之间的某个值。然后,对偏移的增量为已启动线程的总数。
Execution Configuration
Device Memory Accesses
Reference
1. CUDA C Programming Guide
2. CUDA入门博客
3. CUDA U
4. CUDA从入门到精通
5. SISD、MIMD、SIMD、MISD计算机的体系结构的Flynn分类法














 2973
2973











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









