







第一步.kafka 集群安装环境准备
第二步.安装zoookeeper集群
注意kafka有自己自带的zookeeper,我这里没用kafka自带的zookeeper集群,而是自己安装的zookeeper集群,因为zookeeper在其他地方用到比如hadoop集群中
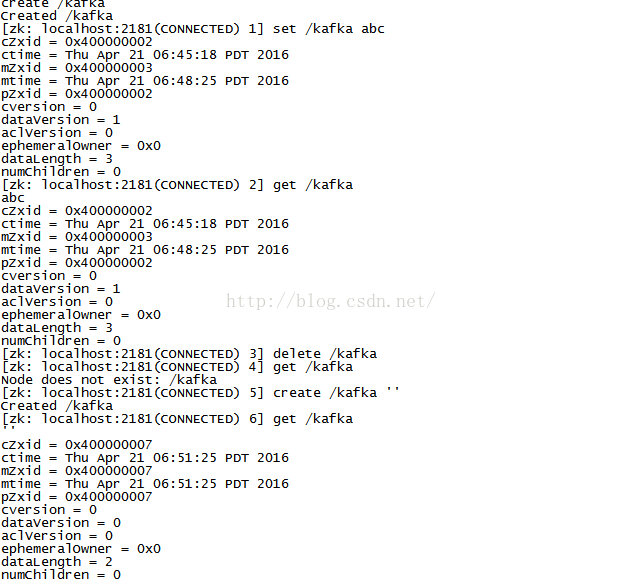
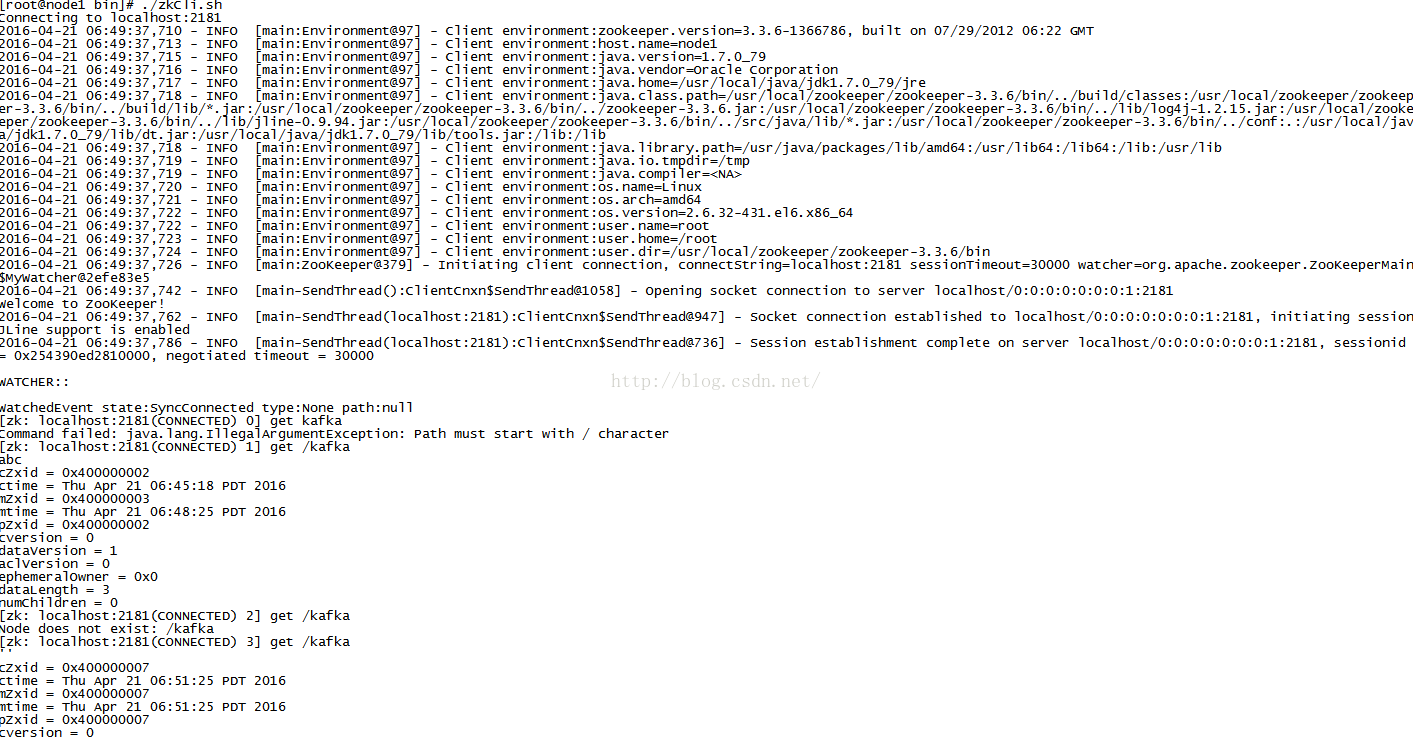
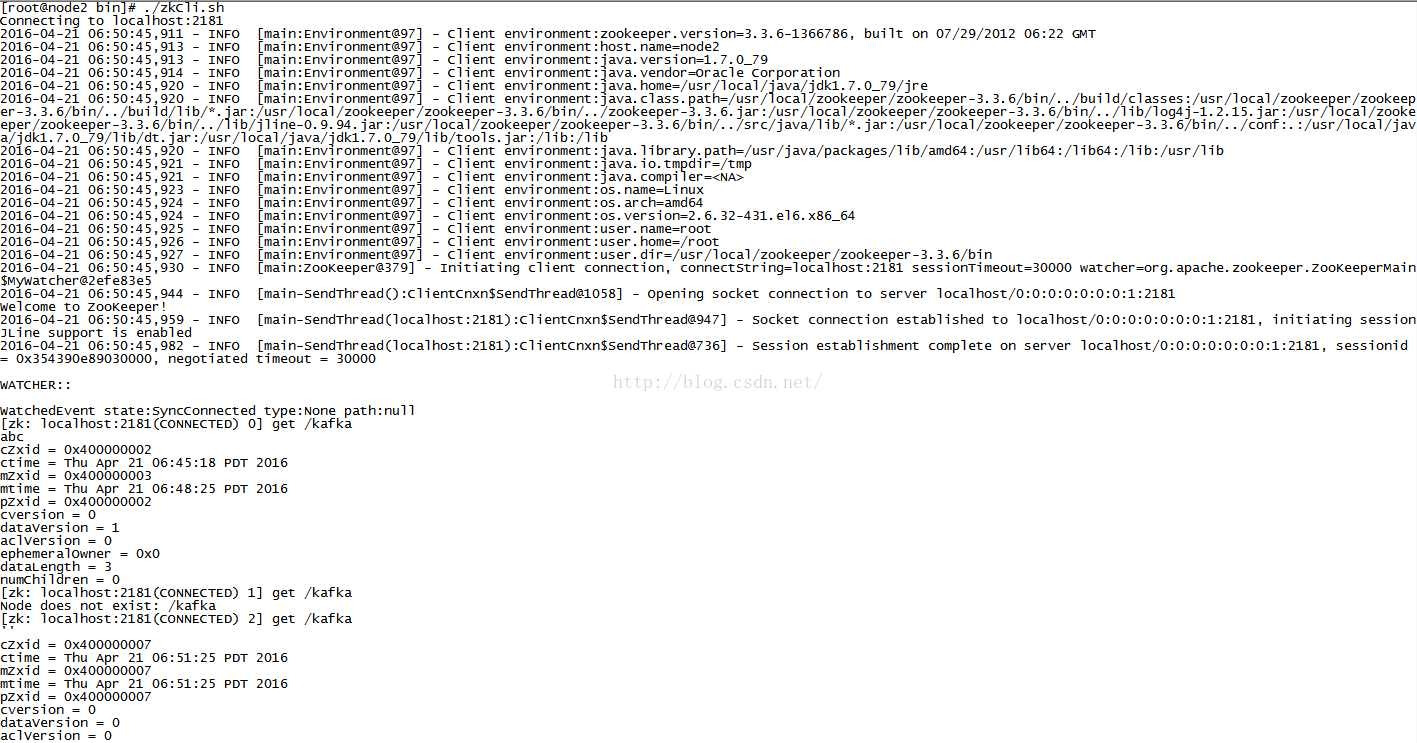
因为是集群所以在每个节点都能查看到刚创建节点kafka的结果:这样证明zookeeper集群安装成功并且可以使用
第三步:kafka集群安装
broker.id=1
#port=9092
# Hostname the broker will bind to. If not set, the server will bind to all interfaces
#host.name=localhost
num.network.threads=3
# The number of threads doing disk I/O
num.io.threads=8
# The send buffer (SO_SNDBUF) used by the socket server
socket.send.buffer.bytes=102400
# The receive buffer (SO_RCVBUF) used by the socket server
socket.receive.buffer.bytes=102400
# The maximum size of a request that the socket server will accept (protection against OOM)
socket.request.max.bytes=104857600
# A comma seperated list of directories under which to store log files
log.dirs=/tmp/kafka-logs
# The default number of log partitions per topic. More partitions allow greater
# parallelism for consumption, but this will also result in more files across
# the brokers.
num.partitions=1
# The number of threads per data directory to be used for log recovery at startup and flushing at shutdown.
# This value is recommended to be increased for installations with data dirs located in RAID array.
num.recovery.threads.per.data.dir=1
# The minimum age of a log file to be eligible for deletion
log.retention.hours=168
# A size-based retention policy for logs. Segments are pruned from the log as long as the remaining
# segments don't drop below log.retention.bytes.
#log.retention.bytes=1073741824
# The maximum size of a log segment file. When this size is reached a new log segment will be created.
log.segment.bytes=1073741824
# The interval at which log segments are checked to see if they can be deleted according
# to the retention policies
log.retention.check.interval.ms=300000
# By default the log cleaner is disabled and the log retention policy will default to just delete segments after their retention expires.
# If log.cleaner.enable=true is set the cleaner will be enabled and individual logs can then be marked for log compaction.
log.cleaner.enable=false
zookeeper.connect=192.168.139.130:2181,192.168.139.131:2181,192.168.139.132:2181/kafka
# Timeout in ms for connecting to zookeeper
#连接zookeeper超时
zookeeper.connection.timeout.ms=6000
注意:红色代表必须配置的项,集群其他节点的配置更这个配置一样,只是下面的四项不相同
4.配置成功以后按顺序启动kafka,master->node1->node2
bin/kafka-server-start.sh config/server.properties &
注意&符号是为了能够继续输入命令没有特殊含义
5.启动成功后就是验证kafka集群安装是否成功
创建一个名称为my-replicated-topic5的Topic,5个分区,并且复制因子为3
bin/kafka-topics.sh --create --zookeeper 192.168.139.130:2181,192.168.139.131:2181,192.168.139.132:2181/kafka
--replication-factor 3 --partitions 5 --topic my-replicated-topic5
查看创建的Topic,执行如下命令
bin/kafka-topics.sh --describe --zookeeper 192.168.139.130:2181,192.168.139.131:2181,192.168.139.132:2181/kafka
--topic my-replicated-topic5
查看结果

解释
bin/kafka-topics.sh –list –zookeeper 192.168.172.98:2181/kafka
1 Partition: 分区
2 Leader : 负责读写指定分区的节点
3 Replicas : 复制该分区log的节点列表
4 Isr : “in-sync” replicas,当前活跃的副本列表(是一个子集),并且可能成为Leader
我们可以通过Kafka自带的bin/kafka-console-producer.sh和bin/kafka-console-consumer.sh脚本,来验证演示如果发布消息、消费消息。
6.在node2终端,启动Producer,并向我们上面创建的名称为my-replicated-topic5的Topic中生产消息
bin/kafka-console-producer.sh --broker-list 192.168.139.130:9091,192.168.139.133:9092,192.168.139.132:9092 --topic my-replicated-topic5

7.在master上启动Consumer,并订阅我们上面创建的名称为my-replicated-topic5的Topic中生产的消息
bin/kafka-console-consumer.sh --zookeeper 192.168.139.130:2181,192.168.139.131:2181,192.168.139.132:2181/kafka --from-beginning --topic my-replicated-topic5
现在就可以在Producer输入你的消息,然后你就可以在consumer端看到你输入的消息内容,说明你的集群安装成功

8.启停kafka集群
启动:bin/kafka-server-start.sh config/server.properties &
停止:bin/kafka-server-stop.sh
第四步:kafka集群安装成功后怎样创建topic
[root@node1 kafka_2.11-0.9.0.0]# bin/kafka-topics.sh --list --zookeeper 192.168.139.130:2181/kafka
[2016-04-22 04:27:20,928] WARN Connected to an old server; r-o mode will be unavailable (org.apache.zookeeper.ClientCnxnSocket)
my-replicated-topic5
test_topic5
删除:
bin/kafka-topics.sh --delete --zookeeper 192.168.139.130:2181/kafka test_topic5
(1)配置文件中必须delete.topic.enable=true,否则只会标记为删除,而不是真正删除。
(2)执行此脚本的时候,topic的数据会同时被删除。如果由于某些原因导致topic的数据不能完全删除(如其中一个broker down了),此时topic只会被marked for deletion,
而不会真正删除。此时创建同名的topic会有冲突
集群安装结束 希望安装本博客安装成功的同学 给予好评 谢谢
配置文件下载路径:http://download.csdn.net/detail/wangguanyin98/9499185














 155
155











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









