







一、目标函数:
首先明确一下本文的符号使用:向量用粗体表示,标量用普通的字母表示,例如: x 表示一个向量, x 表示一个标量。
梯度下降算法在优化理论中有着很重要的地位,凭借实现简单、解决最优化问题效果较好并且有很好的普适性等优点梯度下降算法在机器学习等领域具有广泛的应用。梯度下降算法通常用来解决无约束最小化问题:
(注意到无约束最大化问题 maxx∈Rnf(x) 可以通过简单的在目标函数前加负号而转变成无约束最小化问题 minx∈Rn−f(x) ,所以只需要讨论最小化问题就行)
梯度下降算法迭代更新变量
x
的值来寻找目标函数的局部极小值,第k+1 轮迭代时变量的更新规则:
其中 xk 是第k轮迭代后变量的值, α 是更新步长, ∇f 是目标函数导数(梯度)。
二、问题列表:
要对梯度下降算法有比较全面的了解首先需要回答以下几个问题:
1、为什么负梯度方向就是目标函数减小最快的方向?
2、迭代过程中步长如何选择?
三、梯度方向:
梯度下降算法看起来很简单,直接对目标函数求导就可以了。但是肯定会有些同学有这样的疑问:为什么负梯度方向就是目标函数减小最快的方向?在此做简单的证明,更严格的证明可以查阅本文最后的参考资料。证明比较简单,不需要用到很高深的数学知识。
先从比较简单的二元函数开始,
z=f(x,y)
,如果
f(x,y)
在
(x0,y0)
点可微,则
其中 Δx 和 Δy 分别是在 x 轴和
我们的目标是在函数空间中移动一定的距离
h
(
因为长度
替换掉
Δx
和
Δy
由于 h 是固定长度的标量,为了使
令
u=[cosα¯,cosβ¯]
,所以
根据向量内积的定义,
即 ∇f 在向量 u 方向上的投影。所以当 ∇f 和 u 方向相同时, |∇f|⋅cos<∇f,u⊤>=|∇f| ,函数增长最快; ∇f 和 u 方向相反时, |∇f|⋅cos<∇f,u⊤>=−|∇f| ,函数减小最快。
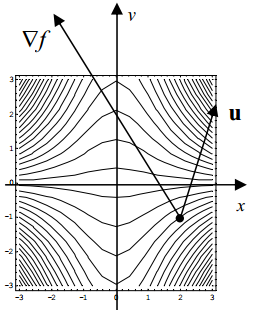
二元函数的情况已经证完了,推广到多元的情况类似,这里就不再赘述了。
四、步长选择:
步长 α 的选择对梯度下降算法来说很重要, α 过小会导致收敛太慢; α 过大容易导致发散。下面介绍几种常用的选择 α 的方法,其中线性搜索方法理论基础较好,但是在实际中使用没有前两种那么广泛,究其原因主要还是因为前面两种方法使用简单并且在大多数情况下都可以得到满意的效果。
固定常数:
最简单的方法就是把 α 固定为一个常数,并且在迭代过程中不改变 α 的值。这种方法要求 α 较小,否则容易导致发散而无法收敛。
线性变化:
另一种简单的方法是在迭代的过程中不断的减小 α 的值。常用的赋值方法是 α=1/k ,其中k是迭代的次数。也可以加入平滑因子 α=τ/(k+τ),τ∈R 。
线性搜索(Linear Search):
线性搜索算法把步长的选择看做一个优化问题:
其中 pk 是当前函数负梯度方向, ϕ(α) 是步长 α 的函数,线性搜索方法利用函数 ϕ(α) 找到一个合适的步长。首先介绍两个条件:Wolfe条件和Goldstein条件,它们是用来判断步长 α 是否足够好的准则。
有了一个合适的步长
αk
之后,就可以通过下面的式子更新变量
x
了:
1、Wolfe 条件:
Wolfe条件主要包括两点:足够下降和曲率条件,在第k+1轮迭代时合适的步长 αk 的值应该同时满足这两个条件。
1、足够下降条件要求
f
的函数值减小足够多
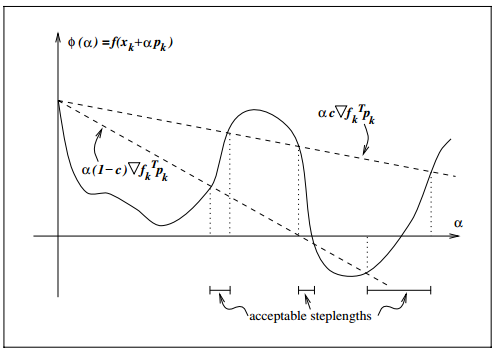
图中的 l(α) 就等于 f(xk)+c1αk∇f⊤kpk 。如果新的变量值 xk+1=xk+αkpk 使得函数值小于等于 l(α) 那么这个变量值是可以接受的(acceptable)。
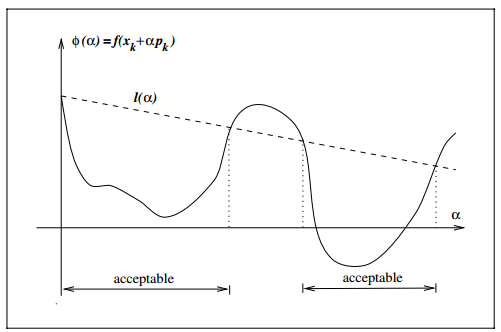
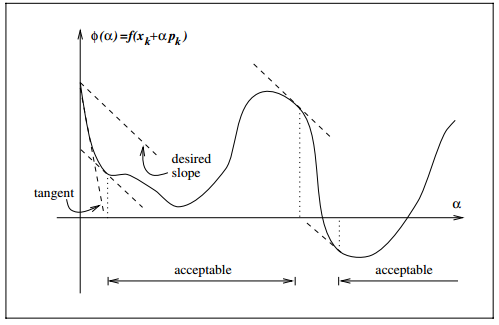
2、曲率条件要求变量变化不能太小,即
xk+αpk
不能与
xk
太接近,否则收敛过慢
图中的tangent虚线对应斜率 ∇fk ,其他几条虚线对应斜率 c2∇fk ,斜率在 ∇fk 和 c2∇fk 之间的 ∇f(xk+αkpk) 与 pk 的内积 ∇f(xk+αkpk)⊤pk 会大于 ∇f⊤kpk (最快下降),小于 c2∇f⊤kpk 。所以满足曲率条件可以保证斜率 ∇f(xk+αkpk) 不在 ∇fk 和 c2∇fk 之间。从而 xk+1 不会在 xk 附近(从图中可以明显观察到),避免收敛过慢。
同时满足Wolfe两个条件的图如下,图中acceptable的区域表示满足Wolfe条件的区域:
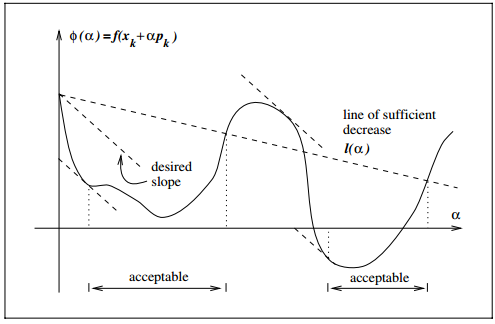
2、Goldstein 条件:
Goldstein条件和Wolfe很类似,Goldstein条件要求函数值有足够的下降,但是不要下降太多
两条虚直线夹角之间的 α 值都满足Goldstein条件。
3、Backtracking Linear Search:
在实际应用中,大多数算法都不会完整使用Wolfe条件和Glodstein条件。Backtracking线性搜索是一种比较实用的步长选择算法,它只利用了Wolfe条件的足够下降条件。具体算法如图所示:
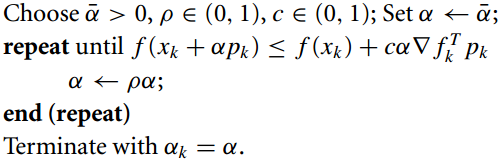
Backtracking算法比较简单,它从一个较大的 α 值开始,不断按比例 ρ 缩小直到满足足够下降条件,最终得到 αk 的值。
五、随机(stochastic)梯度下降和Mini-batch梯度下降算法:
随机梯度下降算法和Mini-batch梯度下降算法都和原始的梯度下降算法类似,只是为了减少计算量,在一次迭代中只使用一个或者几个样本来更新变量 x 。
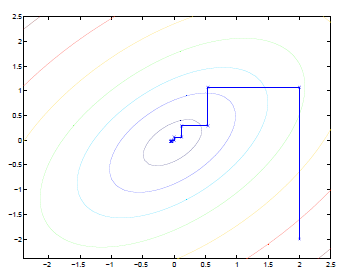
六、坐标下降(coordinate descent)算法:
坐标下降算法和梯度下降算法比较类似:坐标下降算法在每一次迭代中在当前点处沿一个坐标方向进行一维搜索 ,固定其他的坐标方向,找到一个函数的局部极小值。在整个过程中依次循环使用不同的坐标方向进行迭代。
七、参考资料:
Numerical Optimization (Second Edition) by Jorge Nocedal, Stephen J. Wright.














 426
426











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









