







设计实现类高级语言的词法分析器,基本功能如下:
(1) 能识别以下几类单词:
标识符(由大小写字母、数字以及下划线组成,但必须以字母或者下划线开头)
关键字(①类型关键字:整型、浮点型、布尔型、记录型;②分支结构中的if和else;③循环结构中的do和while;④过程声明和调用中的关键字)
运算符(①算术运算符;②关系运算符;③逻辑运算)
界符(①用于赋值语句的界符,如“=”;②用于句子结尾的界符,如“;”;③用于数组表示的界符,如“[”和“]”;④用于浮点数表示的界符“.”)
常数(无符号整数和浮点数,包括指数形式)
注释(/*……*/形式)
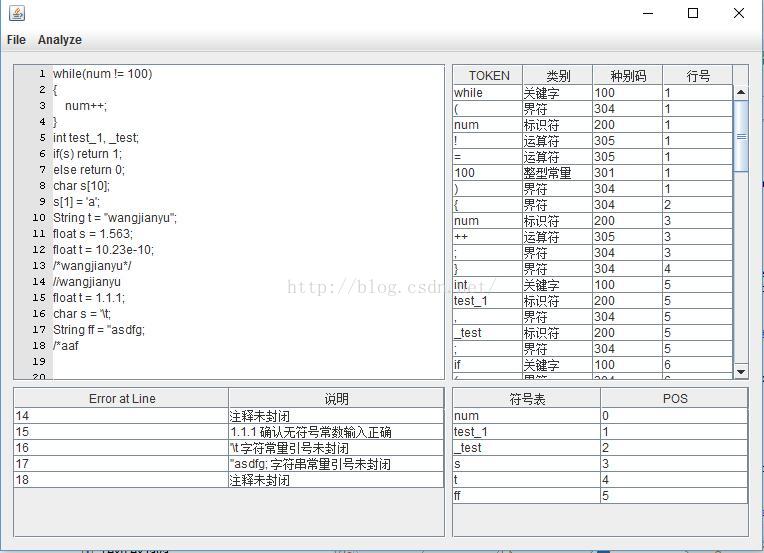
(2)能够进行词法错误处理。识别出输入程序中的词法错误,准确给出错误所在位置,并采用可行的错误恢复策略。输出的错误提示信息格式如下:
Error at Line [行号]:[说明文字]
(3)系统的输入形式:要求能够通过文件导入测试用例。测试用例要涵盖第(1)条中列出的各类单词,并包含各种单词拼写错误。
这里采用的token字符串识别方法是基于DFA状态转移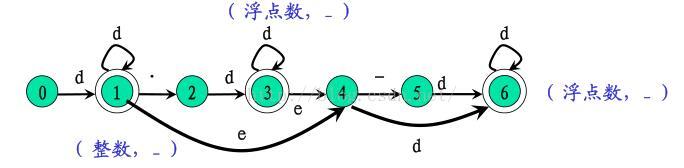
与之对应可以建立一个二维数组进行状态判断
//DFA of digit
public static String digitDFA[] = { "#d#####",
"#d.#e##",
"###d###",
"###de##",
"#####-d",
"######d",
"######d" };//判断输入符号是否符合状态机
public static int in_digitDFA(char ch, char test)
{
if (test == 'd') {
if (isDigit(ch))
return 1;
else
return 0;
}
else
{
if (ch == test)
return 1;
else
return 0;
}
}//初始化进入1状态
int state = 1;
//声明计数变量
int k;
Boolean isfloat = false;
while ( (ch != '\0') && (isDigit(ch) || ch == '.' || ch == 'e' || ch == '-'))
{
if (ch == '.' || ch == 'e')
isfloat = true;
for (k = 0; k <= 6; k++)
{
char tmpstr[] = digitDFA[state].toCharArray();
if (ch != '#' && 1 == in_digitDFA(ch, tmpstr[k]))
{
token += ch;
state = k;
break;
}
}
if (k > 6) break;
//遍历符号先前移动
i++;
if(i>=strline.length) break;
ch = strline[i];
}
全部工程源代码:https://github.com/SalamanderJY/Compiler_Experiment














 1240
1240











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









