






卷积神经网络中的Inception模块是在普通卷积和深度可分卷积操作(深度卷积后逐点卷积)之间的一种中间状态。基于此,深度可分卷积可以理解为最大数量tower的Inception模块。受Inception启发,该观察引发我们提出一种新的深度卷积神经网络结构,用深度可分卷积替代Inception模块。我们展现这种结构,昵称为Xception在ImageNet数据集上表现略优于Inception V3,而在包括3.5亿图片和17000类的更大规模图片分类数据集上优势明显。考虑到Xception结构和Inception V3有相同数量的参数,这种性能的提升是来自于更有效的使用模型参数而不是提高容量。
近年来,卷积神经网络成为了计算机视觉的主要算法,设计基于卷积神经网络的算法获得了很大关注。设计卷积神经网络的历史开始于LeNet风格的模型,该模型只是简单地将卷积提出特征和最大值池化以空间二次取样堆叠起来。2012年,AlexNet结构进一步优化了这种思想,池化操作间的卷积操作被重复多次,使网络在每个空间规模学到更多的特征。受每年的ILSVRC竞赛的推动,随后的风潮是加大这种风格网络的深度,如2013年Zeiler和Fergus,以及2014年的VGG结构。
这时,一种新的网络风格产生,Inception结构,由Szegedy等在2014年引入,被称为GoogLeNet(Inception V1),之后被优化为Inception V2, Inception V3以及最新的Inception-ResNet。Inception自身受早期的网络-网络结构启发。自从首次推出,Inception无论是对于ImageNet的数据集,还是Google内部的数据集,特别是JFT,都是表现最好的模型之一。Inception风格模型最重要的内容是Inception模块,该模块有不同版本存在。
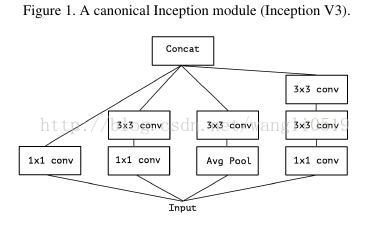
上图是Inception V3结构中传统Inception模块。一个Inception模型是该模块的堆叠。这与早期的VGG风格简单卷积层堆叠的网络不同。
虽然Inception模块概念上与卷积相似(它们是卷积特征提取器),实践中它们能够在更少的参数中学习到更多的表征。
Inception假设
卷积层试图在3D空间学习过滤器,2个空间维度( 宽和高)以及1个通道维度,因此一个卷积核需要同时绘制跨通道相关性和空间相关性。Inception模块背后的思想就是通过将这个过程分解成一系列相互独立的操作以使它更为便捷有效。进一步讲,典型的Inception模块首先处理跨通道相关性,通过一组1×1卷积,将输入数据绘制到3或4个小于原始输入的不同空间,然后通过3×3或者5×5卷积将所有相关性绘制到更小的3D空间。图示如上。实际上Inception背后基本的假设是使跨通道相关性和空间相关性的绘制有效脱钩。
考虑一个Inception模块的简化版本,只使用一种规格的卷积(例如3×3),并且不含平均池化。
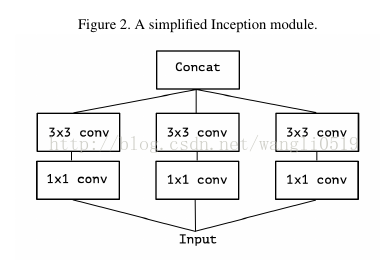
这个Inception模块可以转换成1×1卷积,然后在输出通道不重复的区块进行空间卷积。
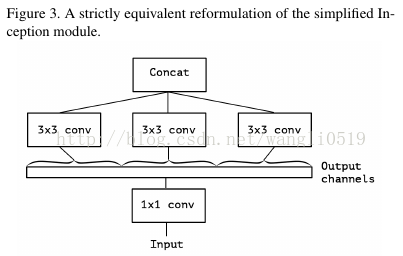
这个观察自然地提出一个问题:在分割中区块数量的效用(以及规模)?如果假设跨区域相关性和空间相关性完全分开绘制,会不会比Inception假设更合理?
一个Inception模块极端的版本就基于上述问题的假设,首先使用1×1卷积绘制跨通道相关性,然后独立的绘制每个输出通道的空间相关性。
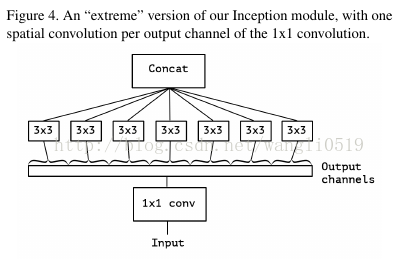
这种Inception模块的极端版本与深度可分卷积几乎相同,该操作早在2014年就被用于神经网络设计,在2016年被纳入TensorFlow框架后变得更为流行。
深度可分卷积,普遍称做“可分卷积”在深度学习框架中例如TensorFlow和Keras,包含深度卷积,即在输入的每个通道独立执行空间卷积,然后进行逐点卷积,即1×1卷积,将深度卷积的通道输出映射到新的通道空间。不要把它与空间可分卷积混淆,后者通常在图像处理社区被称为可分卷积。
Inception模块的极端版本和深度可分卷积的两个不同有:
-操作顺序:深度可分卷积一般(例如在TensorFlow中)先进行通道的空间卷积,然后进行1×1卷积,而Inception首先进行1×1卷积。
-上个操作后是否进行非线性操作:Inception中两个操作后都使用ReLU进行非线性激活,而深度可分卷积不使用。
我们认为第一个区别并不重要,因为这些操作会被堆叠起来,第二个区别在实验中对结果有所影响。
我们也注意到,在普通Inception模块和深度可分卷积之间也可能存在其他组合:实际上通过调整空间卷积不同数量的独立通道-空间区块,存在一个离散的序列。普通卷积(1×1卷积开始)在序列的一端,对应单一区块情况;深度可分卷积对应另一端,每个通道为一个区块;Inception模块居于其间,将数百个通道划分成3或4个区块。这些居间模块的属性还没有被完全审视挖掘。
基于上述观察,我们认为使用深度可分卷积替代Inception模块能够提升Inception结构,即用深度可分卷积堆叠来构建模型。
我们提出一个完全基于深度可分卷积层的卷积神经网络结构。实际上,我们做如此假设:卷积神经网络的特征图中的跨通道相关性和空间相关性的绘制可以完全脱钩。由于这种假设是Inception结构中极端化的假设,我们将它称作Xception,意指极端Inception。
网络的完整描述如下图:
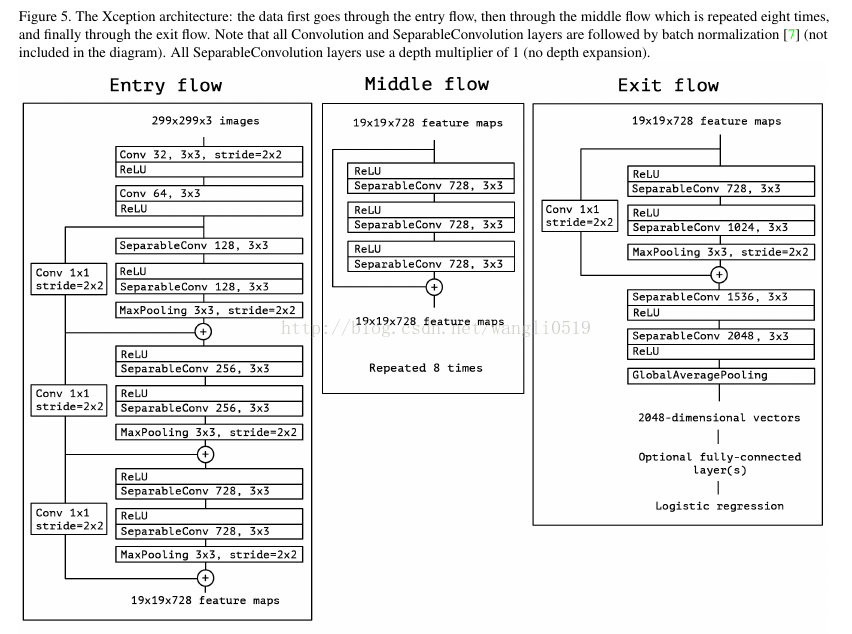
Xception结构由36个卷积层组成网络的特征提取基础。我们的评估实验中只进行图像分类,因此我们在卷积之后使用了逻辑回归层。可选的,也可以在逻辑回归层之前加入完全连接层。36个卷积层被分成14个模块,除最后一个外,模块间有线性残差连接。
简单讲,Xception结构是带有残差连接的深度可分卷积层的线性堆叠。这是该结构非常容易去定义和修改;使用高级库如Keras或者TensorFlow-Slim只需要30-40行代码,与VGG-16类似,但与Inception V2和Inception V3这些复杂难以定义的结构不同。在MIT证书下,Keras提供了一个Xception的开源实现。














 983
983











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









