









1背景介绍
这里主要想测试一些spark的优化方式之一的kryo。场景为通过数1000w的数据,通过日期分组,求一个点击字段的sum。使用了kryo和没使用kryo的时间对比。这里由于环境限制,主要是使用到了kryo在各个机器之间的传输序列化(这里是内网很快),传入内存序列化,磁盘数据RDD的序列化(这个案列没有用到)。
数据格式:
id,addtime,deviceNum,itemid,op_type,op_num,inserttime
这是对一个物品的点击次数,已经通过addtime,deviceNum,itemid分组求和了。
需求为计算每天的点击数:通过日期分组,求和。
“select addtime,sum(op_num) as num from day_epinfo group by addtime”
数据大小:
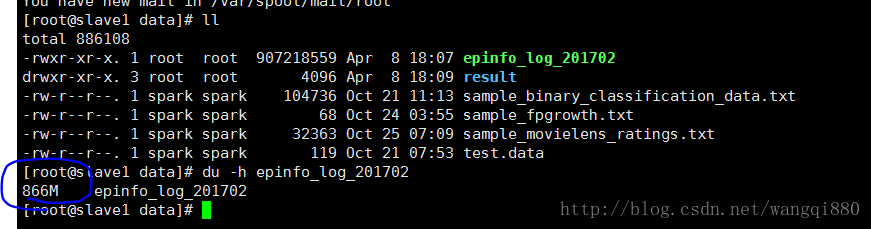
一个月数据,已经通过addtime,deviceNum,itemid分组求和之后,数据量866M,一共1000w多条数据
每个子节点已经的数据目录已经有数据了
数据来源,自己写个java随机生成呗。
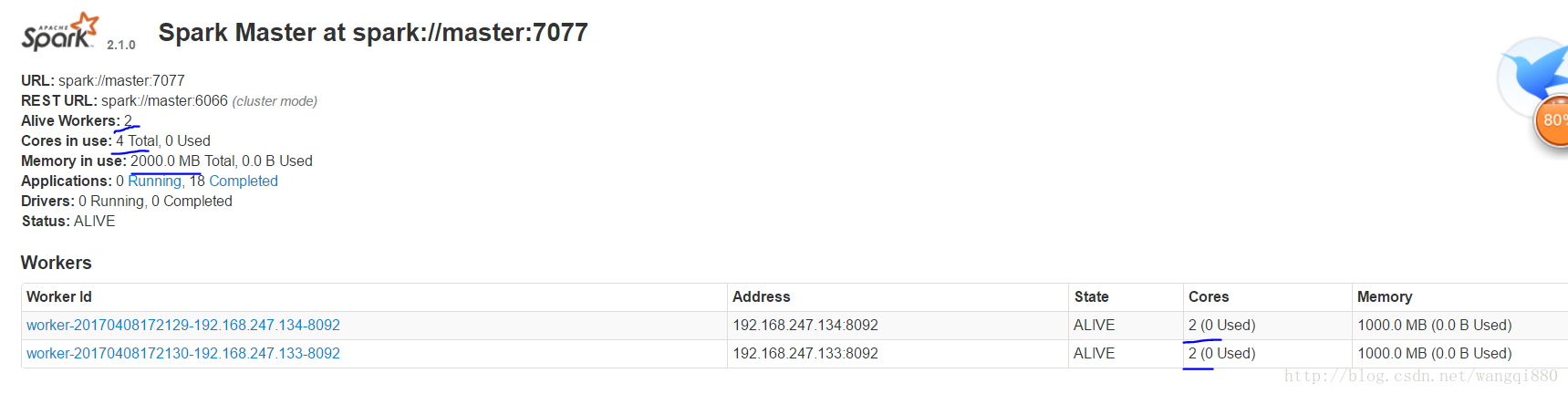
spark集群环境介绍
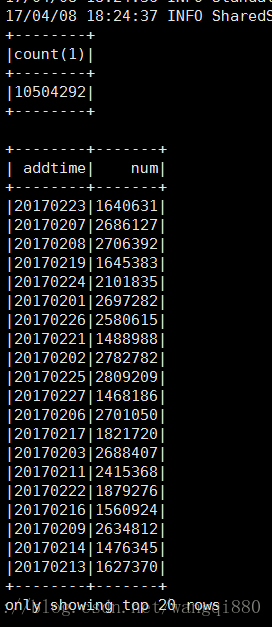
2没有使用kryo
开始时间:2017-04-08 18:24:35
结束时间:2017-04-08 18:25:06
耗时31秒,是比较快的,因为数据本地性,并且使用kryo的话,数据的传输也是在这两个节点上传输,对于这个场景速度提升有限,但是肯定会提升,这里讲原理。
3使用kryo
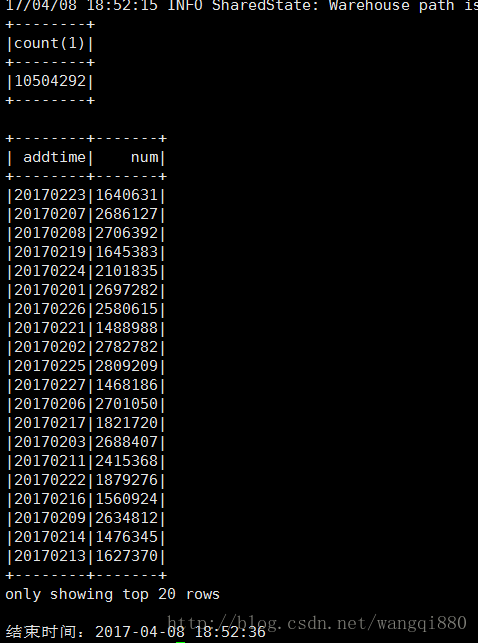
开始时间:2017-04-08 18:52:14
结束时间:2017-04-08 18:52:36
耗时22秒,可以看出kryo还是有效果的。
可以看出使用了kryo的效果会好一点,这里因为只是用到了kryo的在集群之间的传输序列化,而且本身2台机器在同一个vm中,同一个电脑中,所以速度本身就好快,效果只好一点。
如果在网络中使用kryo的话,效果会很明显。
4kryo的优缺点
序列化速度快,但是不能支持所有的Serializable,我所知道的是不能序列化和反序列化map类型,其他不知道。并且对应的数据的类需要注册,如果不注册会比较浪费内存。
ps:
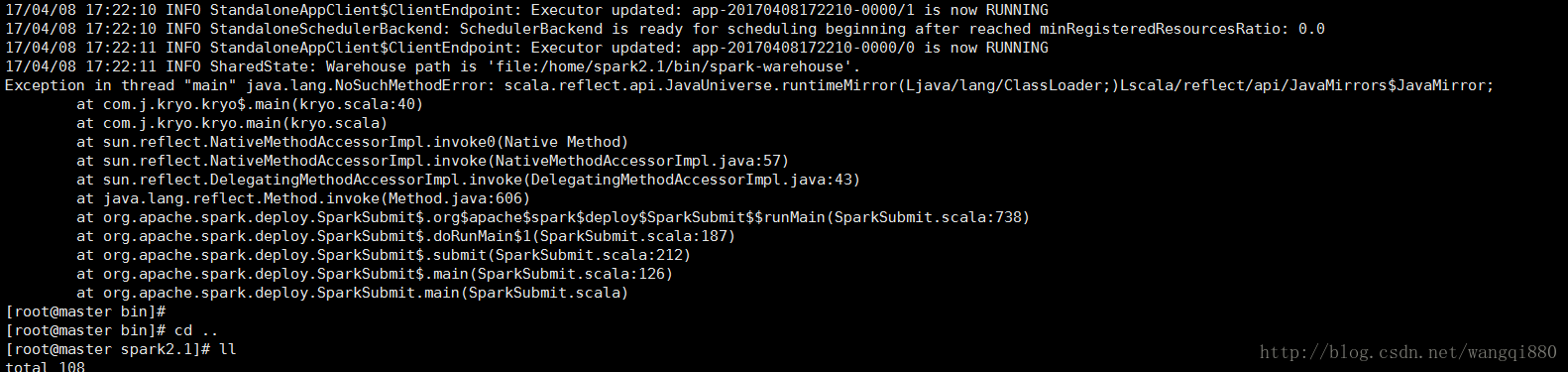
在编译环境和运行环境的各种jar的版本要一直,不然可能会报如下错误
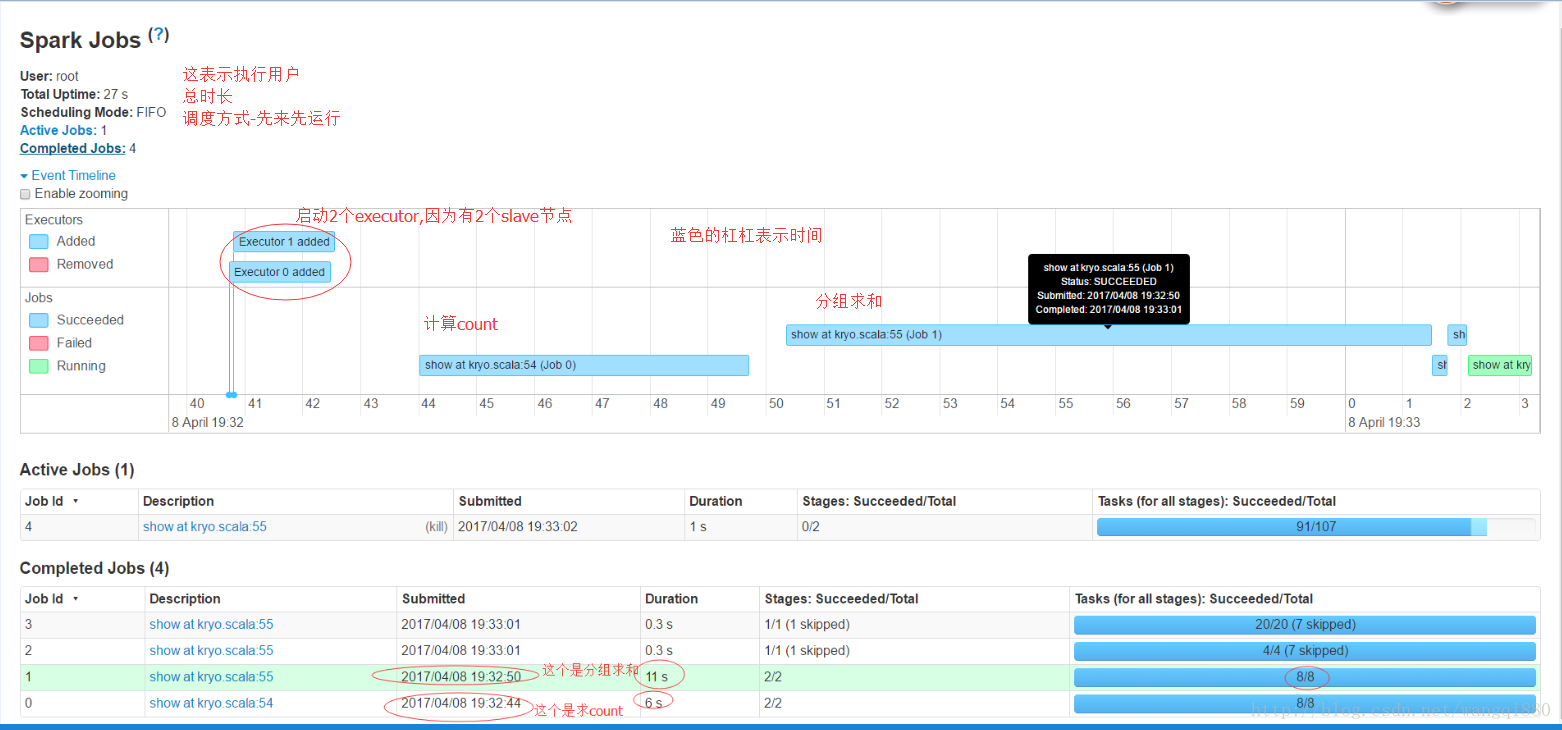
这里是spark的job监控界面:
测试代码如下:
package com.j.kryo
import java.text.SimpleDateFormat
import java.util.Date
import org.apache.spark.sql.SparkSession
/**
* Created by Administrator on 2017/3/21.
* kryo的序列化案列
*/
object kryo {
//日志格式
case class Day_epinfo(id:Int,addtime:String,deviceNum:String,comicId:String,op_type:String,op_num:Int,insertTime:String)
case class Persion(name:String,age:String)
def main(args:Array[String]):Unit={
println("开始时间:"+getNowDate())
val spark = SparkSession.builder()
.appName("kryo")
.config("spark.serializer","org.apache.spark.serializer.KryoSerializer")
.getOrCreate()
spark.sparkContext.setLogLevel("ERROR")
spark.sparkContext.getConf.registerKryoClasses(Array(classOf[Day_epinfo]))
/*System.setProperty("hadoop.home.dir","E:\\bigdata\\hadoop-2.6.4")
val warehouseLocation ="E:\\mllibworksparce2\\mllibworksparce2\\spark-warehouse"
val spark = SparkSession.builder()
.appName("kryo")
.master("local[2]")
.config("spark.sql.warehouse.dir",warehouseLocation)
.config("spark.serializer","org.apache.spark.serializer.KryoSerializer")
.getOrCreate()
spark.sparkContext.setLogLevel("ERROR")
*/
val data_souce_path=args(0)
val data_result_path=args(1)
/*val data_souce_path="data/epinfo_log_201702_tmp"
val data_result_path="data/result"*/
val data = spark.read.textFile(data_souce_path)
import spark.implicits._
val data2 = data.map(line=>{line.split("\t")})
.map(attributes=>Day_epinfo(attributes(0).toInt,attributes(1),attributes(2),attributes(3),attributes(4),attributes(5).toInt,attributes(6)))
data2.createOrReplaceTempView("day_epinfo")
val count = spark.sql("select count(1) from day_epinfo")
val result = spark.sql("select addtime,sum(op_num) as num from day_epinfo group by addtime")
count.show()
result.show()
println("结束时间:"+getNowDate())
/*result.write.save(data_result_path)
spark.read.load(data_result_path).toDF().show()*/
spark.close()
}
def getNowDate():String={
var now:Date = new Date()
var dateFormat:SimpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
var hehe = dateFormat.format( now )
hehe
}
}
maven的pom
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.j</groupId>
<artifactId>j-mllib</artifactId>
<version>1.0-SNAPSHOT</version>
<inceptionYear>2008</inceptionYear>
<properties>
<scala.version>2.11.8</scala.version>
</properties>
<repositories>
<repository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</pluginRepository>
</pluginRepositories>
<dependencies>
<!--<dependency>
<groupId>org.specs</groupId>
<artifactId>specs</artifactId>
<version>1.2.5</version>
<scope>test</scope>
</dependency>-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>1.1.1</version>
<type>jar</type>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.3.2</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.6.4</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.8</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-compiler</artifactId>
<version>2.11.8</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.11</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>com.esotericsoftware</groupId>
<artifactId>kryo</artifactId>
<version>4.0.0</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
<args>
<arg>-target:jvm-1.5</arg>
</args>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-eclipse-plugin</artifactId>
<configuration>
<downloadSources>true</downloadSources>
<buildcommands>
<buildcommand>ch.epfl.lamp.sdt.core.scalabuilder</buildcommand>
</buildcommands>
<additionalProjectnatures>
<projectnature>ch.epfl.lamp.sdt.core.scalanature</projectnature>
</additionalProjectnatures>
<classpathContainers>
<classpathContainer>org.eclipse.jdt.launching.JRE_CONTAINER</classpathContainer>
<classpathContainer>ch.epfl.lamp.sdt.launching.SCALA_CONTAINER</classpathContainer>
</classpathContainers>
</configuration>
</plugin>
</plugins>
</build>
<reporting>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
</configuration>
</plugin>
</plugins>
</reporting>
</project>















 2981
2981











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











