







1、集群部署的基本流程
集群部署的流程:下载安装包、解压安装包、修改配置文件、分发安装包、启动集群
注意:
所有的集群上都需要配置hosts
vi /etc/hosts
192.168.239.128 storm01 zk01 hadoop01
192.168.239.129 storm02 zk02 hadoop02
192.168.239.130 storm03 zk03 hadoop03
2、集群部署的基础环境准备
安装前的准备工作(zk集群已经部署完毕)
l 关闭防火墙
chkconfig iptables off && setenforce 0
l 创建用户
groupadd realtime && useradd realtime &&usermod -a -G realtime realtime
l 创建工作目录并赋权
mkdir /export/servers
chmod 755 -R /export
l 切换到realtime用户下
su realtime
3、Storm集群部署
3.1、下载安装包
3.2、解压安装包
tar -zxvfapache-storm-0.9.5.tar.gz -C /export/servers/
cd /export/servers/
ln -sapache-storm-0.9.5 storm
3.3、修改配置文件
mv/export/servers/storm/conf/storm.yaml /export/servers/storm/conf/storm.yaml.bak
vi/export/servers/storm/conf/storm.yaml
输入以下内容:

分发安装包
scp -r/export/servers/apache-storm-0.9.5 storm02:/export/servers
然后分别在各机器上创建软连接
cd/export/servers/
ln -sapache-storm-0.9.5 storm
3.5、启动集群
l 在nimbus.host所属的机器上启动 nimbus服务
cd /export/servers/storm/bin/
nohup ./storm nimbus &
l 在nimbus.host所属的机器上启动ui服务
cd /export/servers/storm/bin/
nohup ./storm ui &
l 在其它个点击上启动supervisor服务
cd /export/servers/storm/bin/
nohup ./storm supervisor &
3.6、查看集群
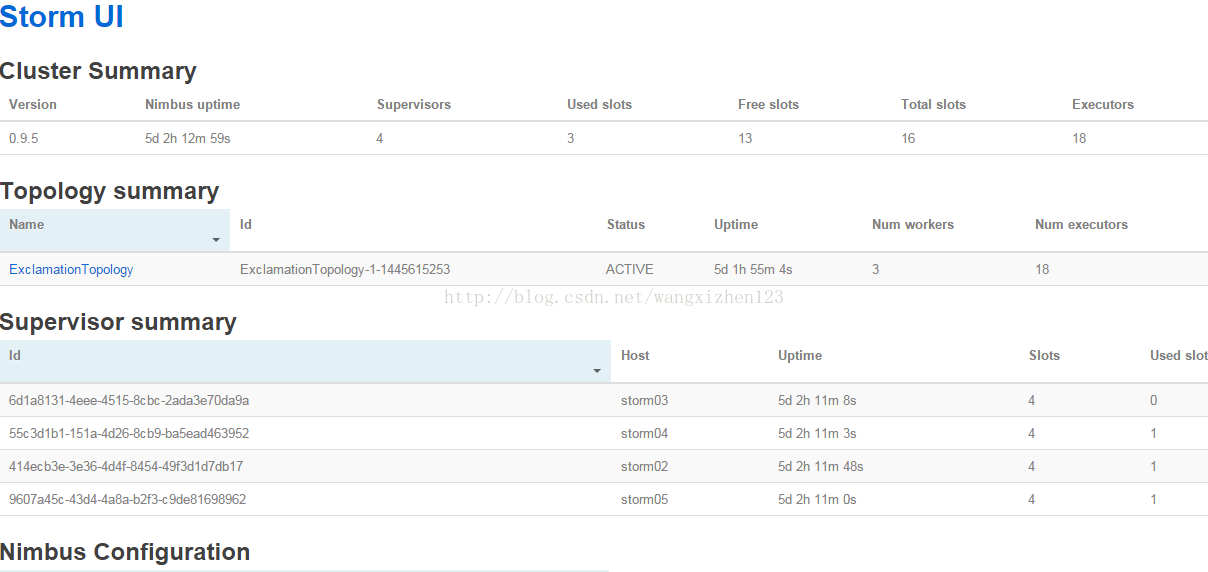
访问nimbus.host:/8080,即可看到storm的ui界面。即成功














 1571
1571











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









