







1.搭建伪分布式集群使用root用户登录
第一步:设置ip,为虚拟机设置一个ip地址:
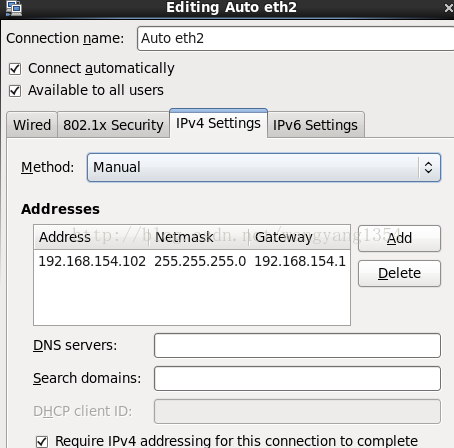
设置完成后要检测:service network restart 重启生效,然后ping命令测试该ip是不是能ping通。
2.更改主机名:
执行命令:vi /etc/sysconfig/network
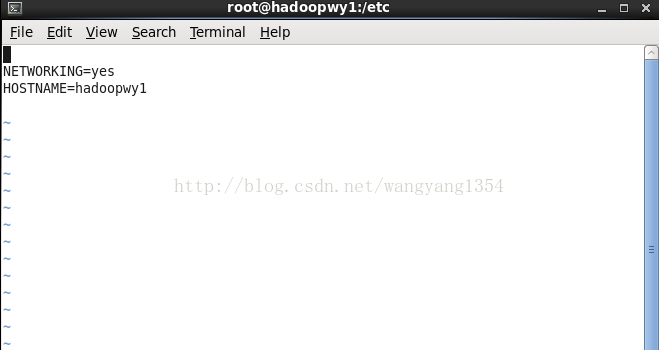
更改之后再重新启动就会更改用户名,通过命令hostname即可查看
3.设置hosts中ip与主机名的绑定
执行命令 vi /etc/hosts
在里面添加选项设置你的主机名与ip的对应关系
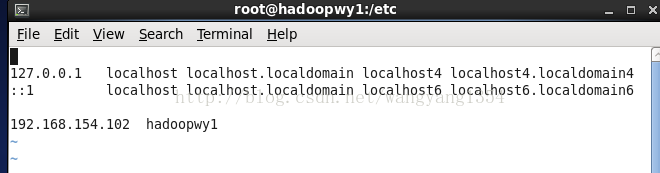
Ping一下这个主机名看是不是能ping通
注意这里在windows 里面由于没有设置应该是ping不通过的,设置c盘下windows文件夹下面system32这个文件夹里面drivers下etc下的hosts文件进行更改,添加对应你的主机名与ip地址


但是更改hosts时可能会因为权限问题被阻止更改,注意一下更改你对这个文件的权限
4.关闭防火墙
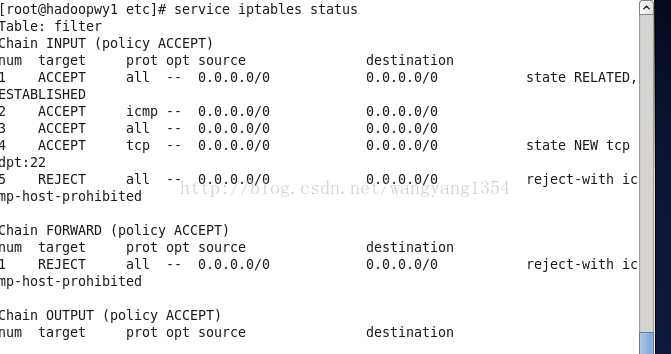
第一行的命令即可查看防火墙的状态,关闭的命令:
Service iptables stop

进行验证:

Chkconfig 这个命令下面是服务的一些配置,查看会不会有重启的可能
执行命令 chkconfig --list
存在on的就是可能在某些条件下重启的
查找防火墙的重启的相关项 :
Chkconfig --list |grep iptables

关闭:chkconfig iptables off

6 ssh-->secure shell
传输的数据是加过密的比较安全.
执行命令产生密钥:ssh-keygen -t rsa 位于当前用户下的~/.ssh这个文件夹中
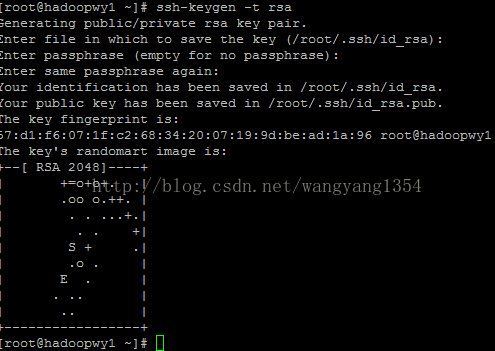
查看目录下面有木有东西:
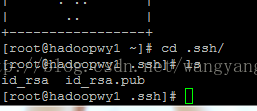
继续执行下面新的命令
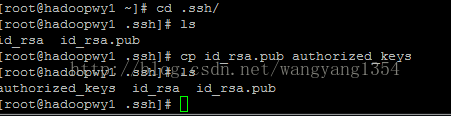
ssh的免密码登录就搞定了

7.安装jdk
使用winSCP传输hadoop和jdk的压缩包放入linux系统,放在root/downloads里面
安装到usr/local里面,删除之前存在的文件
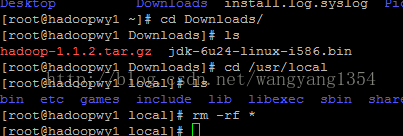
cp /root/Downloads/* .
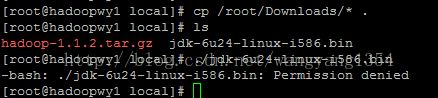
执行jdk但是这里遇到了权限的问题,接下来要更改权限
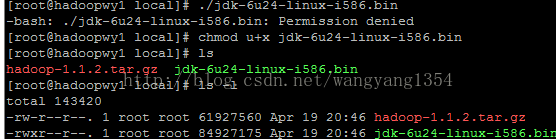
颜色已经变了,原来显示的是白色的,现在是绿色了,应该就能运行了
执行原先的命令./jdk-6u24-linux-i586.bin
等待安装完成即可

安装完了,还得配置环境变量的;
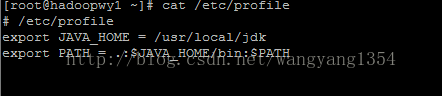

安装完成了。
8.安装hadoop
执行命令 tar -zxvf hadoop-1.1.2.tar.gz

修改hadoop的配置文件
位于$HADOOP_HOME/conf目录下的修改四个配置文件:hadoop-env.sh、core-site.xml
hdfs-site.xml 、mapred-site.xml
1.hadoop-env.sh
export JAVA_HOME=/usr/local/jdk/
2.core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop0:9000</value>
<description>change your own hostname</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration>
这个文件配置的fs.default.name是这些机子的namenode节点,也就是主控节点,value的值需要根据自己虚拟机的名字进行配置。创建集群的时候这个文件一般都是一致的。
3.hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
这个配置文件配置了集群的备份数目,这里的是1,可以根据自己的情况进行配置,下面的配置dfs.permissions是配置的文件操作时的权限检查标识。
4.mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>hadoop0:9001</value>
<description>change your own hostname</description>
</property>
</configuration>
该文件配置的jobtracker,这个文件在集群搭建的过程中也应该是一样的。
我们往往是搭建起来的单机都是全部是这样进行配置,但是搭建集群的话,这样单独的配置是不行的,必须让多台机子公用几个相同的配置文件找到对于他们来说相同的控制节点才行,比如namenode和jobtracker ,集群中必须保证namenode和jobtracker的配置文件是一致的正常工作。
进行格式化:


但是hadoop这里有警告
去掉启动过程中的警告
在/etc/profile里面添加一行

export HADOOP_HOME_WARN_SUPPRESS=1或者其他的什么值只要不是空即可
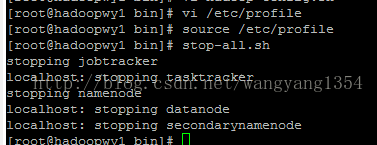
这样配置就完成了一个单机的配置
按照这几个步骤,在建立好的其他的虚拟机里面进行同样的配置。
这样配置完成之后还要进行其他的配置:ssh免密码登录需要重新设置一下
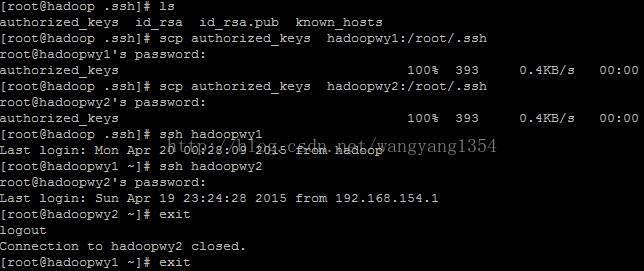
在Hadoop启动以后,Namenode是通过SSH(Secure Shell)来启动和停止各个节点上的各种守护进程的,这就需要在节点之间执行指令的时候是不需要输入密码的方式,故我们需要配置SSH使用无密码公钥认证的方式。
首先要保证每台机器上都装了SSH服务器,且都正常启动。实际中我们用的都是OpenSSH,这是SSH协议的一个免费开源实现。
以本文中的4台机器为例,现在hadoop1是主节点,它需要主动发起SSH连接到hadoop2,对于SSH服务来说,hadoop1就是SSH客户端,而hadoop2, hadoop3,hadoop4则是SSH服务端,因此在hadoop2,hadoop3,hadoop4上需要确定sshd服务已经启动。简单的说,在hadoop1上需要生成一个密钥对,即一个私钥,一个公钥。将公钥拷贝到hadoop2上,这样,比如当hadoop1向hadoop2发起ssh连接的时候,hadoop2上就会生成一个随机数并用hadoop1的公钥对这个随机数进行加密,并发送给hadoop1,hadoop1收到这个加密的数以后用私钥进行解密,并将解密后的数发送回hadoop2,hadoop2确认解密的数无误后就允许hadoop1进行连接了。这就完成了一次公钥认证过程。
搭建集群的时候需要配置各个机子的hosts里面的每个机子的ip地址与主机名都要有
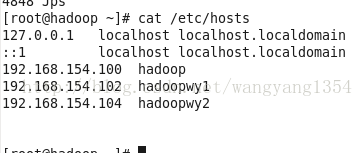
我这里是这样设置的
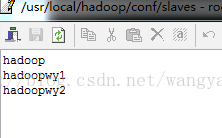
另外还有一点是:配置hadoop文件当中的conf文件夹下面的masters和slaves这两个文件中进行配置主从节点,好像是masters里面的是secondaryNameNode存在哪里,就是备份secondaryNameNode的,在这里我配置的时候在master中配置为hadoop了,在salves文件里面配置了三个机子
在hadoop中进行启动start-all.sh,
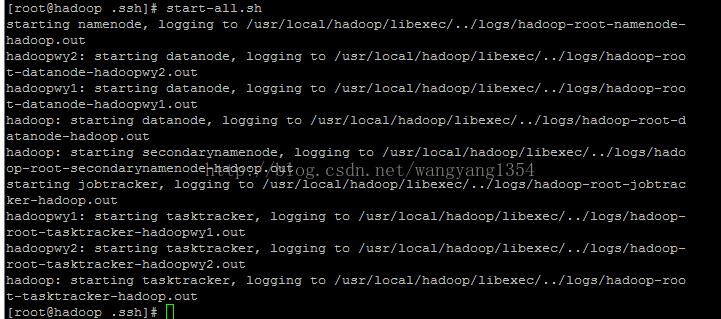
在每个虚拟机中进行确认

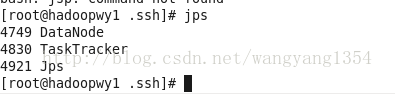

到这里基本上伪分布式集群就已经设置完成了
在这里再补充一下:
搭建集群并不是一帆风顺的,集群搭建起来之后,除了上面的确认方式还要看一下,主机的节点信息,比如我的机子:
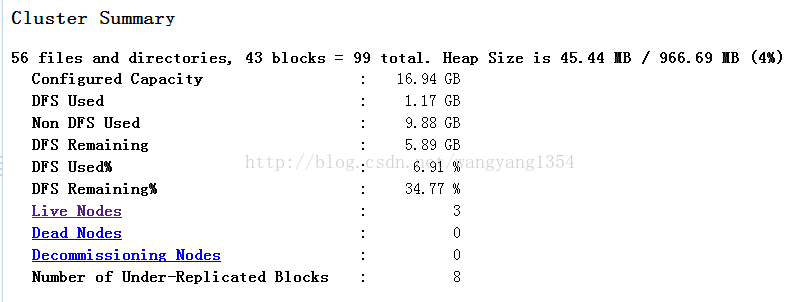
注意看到Live Nodes了么?是三个,如果你的这个信息跟实际想要的不一致,那么可能就是在每台虚拟机中的配置文件是不一样的,namenode和jobtracker都要保持一致,不然没办法正常工作。
如果碰到了这样的情况,我现在单独配置了三台主机,都有自己的namenode和jobtracker,这种情况的话,
1.修改一下配置上面的几个文件,保持一致,配置完了再看看你的机子能不能启动其余的datanode如果不能先关闭这些节点继续向下做。
2.删除子节点的tmp和logs文件,这俩文件都存放在你配置的路径中,hadoop.tmp.dir在你的配置文件中找一下这个文件,去这个文件里面删除那俩文件
3.重新创建tmp和logs文件
4.在主节点namenode的机子上hadoop namenode -format 进行格式化,这样再重新开启start-all.sh
| 主机名 | Hadoop角色 | Hadoop jps命令结果 | Hadoop用户 | Hadoop安装目录 |
| hadoop | Master slaves | NameNode DataNode JobTracker TaskTracker SecondaryNameNode | 创建相同的用户的组名:hadoop。 安装hadoop-1.1.2时使用root用户 Hadoop既是namenode 又是datanode又是jobtracker 文件在/user/root/下 | /usr/local/hadoop |
| hadoopwy1 | slaves | DataNode TaskTracker | ||
| hadoopwy2 | slaves | DataNode TaskTracker |















 2217
2217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









