







这是双调排序的并行算法,当我试着在纸上一步步理解时,还是有点吃力的,发现还是要先去了解何谓Bitonic Sort,我去查了一下,这种双调排序:http://blog.csdn.net/jiange_zh/article/details/49533477 其实看这位大神的这个图就知道了:
(图 1)
我将它理解并补全了一下:
(图 2)
非常清楚。
也就是类似这样:

(图 3)
这样就理解了双调排序,再去看这个例子就会好懂了:
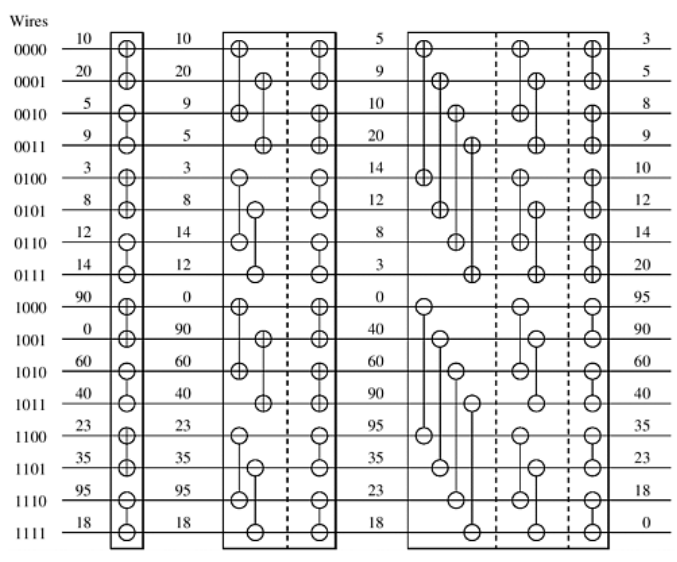
(图 4)
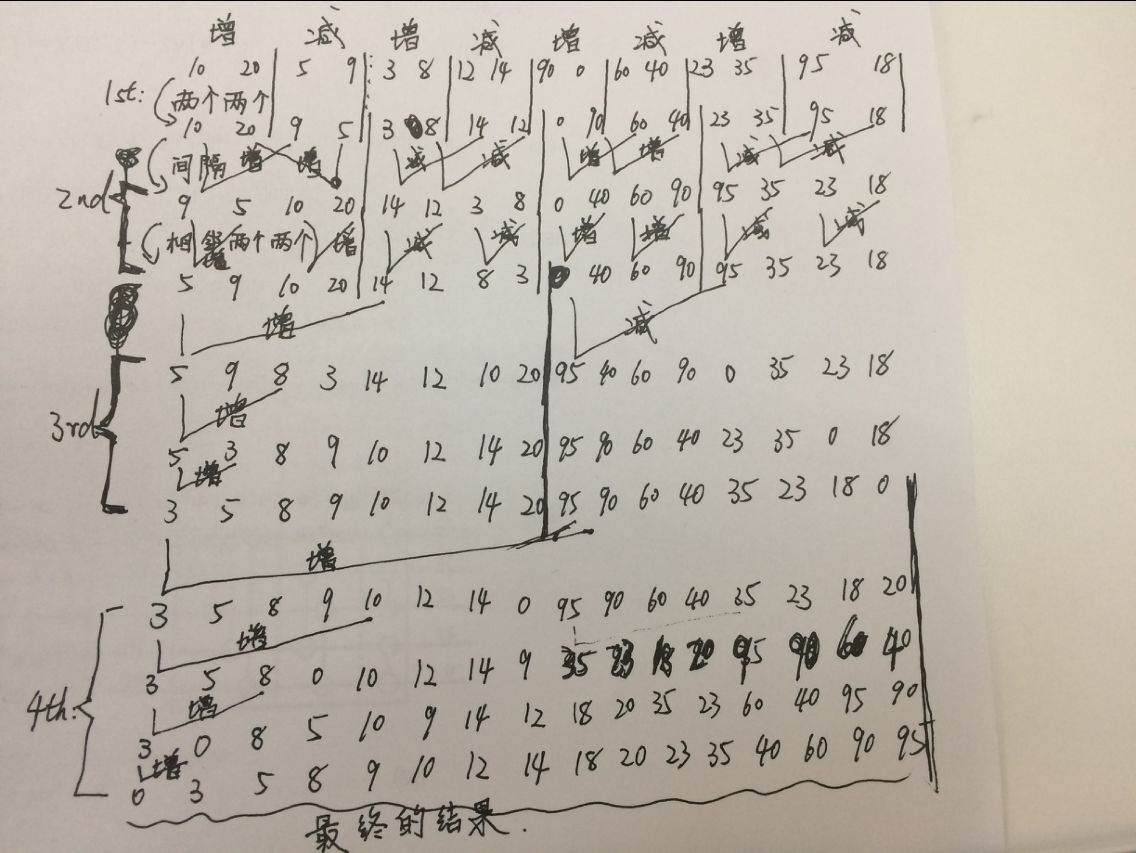
将图4对照图2 理解就非常好理解。(假如这个例子中input就是这16个数)那么每一大步有几小步就由host端的两个for()循环控制;那么kernel内部的pairDistance就是:每间隔pairDistance个数进行比较(图3中的意义);blockWidth就是:每blockWidth个增减交替(图3中的含义)。每个item负责两个位置上的数的比较,由leftId和rightId找到这两个位置,那么theArray的leftId和rightId位置分别就是每个item所要的数据:leftElement、rightElement,根据blockWidth会得到增、减命令即sortIncreasing,每个item参考sortIncreasing将那两个数进行比较,即对theArray中自己负责的两个位置进行了重新排列。 这个例子就是这个意思!
由图2和图3可知,每一大步的每一小步时,数据的比较不是相互依赖的,而是独立的,故可以将双调排序改成并行形式!!!
依旧是我习惯看的样子:
#include <CL/cl.h>
#include <CL/cl_ext.h>
#include <stdlib.h>
#include <string.h>
#include <malloc.h>
#include <stdio.h>
#include "n_needed_headers/oclUtils.h"
#include "a_needed_headers/SDKCommon.hpp"
using namespace std;
#define GROUP_SIZE 8
void swapIfFirstIsGreater(cl_uint *a, cl_uint *b)
{
if(*a > *b)
{
cl_uint temp = *a;
*a = *b;
*b = temp;
}
}
int main()
{
//set up OpenCL...
cl_uint platformNum;
cl_int status;
status=clGetPlatformIDs(0,NULL,&platformNum);
if(status!=CL_SUCCESS){
printf("cannot get platforms number.\n");
return -1;
}
cl_platform_id* platforms;
platforms=(cl_platform_id*)alloca(sizeof(cl_platform_id)*platformNum);
status=clGetPlatformIDs(platformNum,platforms,NULL);
if(status!=CL_SUCCESS){
printf("cannot get platforms addresses.\n");
return -1;
}
cl_platform_id platformInUse=platforms[0];
cl_device_id device;
status=clGetDeviceIDs(platformInUse,CL_DEVICE_TYPE_DEFAULT,1,&device,NULL);
cl_context context=clCreateContext(NULL,1,&device,NULL,NULL,&status);
cl_command_queue_properties prop=0; //CL_QUEUE_PROFILING_ENABLE;
cl_command_queue_properties *propers;
propers=∝
cl_command_queue commandQueue=clCreateCommandQueueWithProperties(context,device,propers, &status);
std::ifstream srcFile("/home/jumper/OpenCL_projects/AMD-Sample-BitonicSort/BitonicSort_Kernels.cl");
std::string srcProg(std::istreambuf_iterator<char>(srcFile),(std::istreambuf_iterator<char>()));
const char * src = srcProg.c_str();
size_t srclength = srcProg.length();
cl_program program=clCreateProgramWithSource(context,1,&src,&srclength,&status);
status=clBuildProgram(program,1,&device,NULL,NULL,&status);
if (status != CL_SUCCESS)
{
cout<<"error:Build BasicDebug_Kernel()..."<<endl;
shrLogEx(LOGBOTH | ERRORMSG, status, STDERROR);
oclLogBuildInfo(program, oclGetFirstDev(context));
oclLogPtx(program, oclGetFirstDev(context), "oclproblem.ptx");
return(EXIT_FAILURE);
}
//prepare data
cl_int length=16,sortFlag=1;
cl_kernel kernel = clCreateKernel(program, "bitonicSort", &status);
CHECK_OPENCL_ERROR(status, "clCreateKernel failed.");
cl_mem inputBuffer = clCreateBuffer(context,CL_MEM_READ_WRITE ,sizeof(cl_uint) * length,NULL, &status);
CHECK_OPENCL_ERROR(status, "clCreateBuffer failed. (inputBuffer)");
cl_uint inputSizeBytes=length*sizeof(cl_uint);
cl_uint *input=(cl_uint*)clEnqueueMapBuffer(commandQueue,inputBuffer,CL_TRUE,CL_MAP_WRITE_INVALIDATE_REGION,0,inputSizeBytes,0,NULL,NULL,&status);
CHECK_OPENCL_ERROR(status, "clEnqueueMapBuffer failed. (input)");
input[0]=10;input[1]=20;input[2]=5;input[3]=9;input[4]=3;input[5]=8;input[6]=12;
input[7]=14;input[8]=90;input[9]=0;input[10]=60;input[11]=40;input[12]=23;input[13]=35;input[14]=95;input[15]=18;
cl_uint *verificationInput = (cl_uint *) malloc(length * sizeof(cl_int));
memcpy(verificationInput, input, length * sizeof(cl_int));
status = clEnqueueUnmapMemObject(commandQueue, inputBuffer, input, 0,NULL,NULL);
status = clSetKernelArg(kernel, 0,sizeof(cl_mem),(void *)&inputBuffer);
CHECK_OPENCL_ERROR(status, "clSetKernelArg failed. (inputBuffer)");
status = clSetKernelArg(kernel,3,sizeof(cl_uint),(void *)&sortFlag);
CHECK_OPENCL_ERROR(status, "clSetKernelArg failed. (increasing)");
size_t globalThreads[1] = {length/2};
size_t localThreads[1] = {GROUP_SIZE};
cl_uint numStages = 0, temp, stage, passOfStage;
for(temp = length; temp > 1; temp >>= 1)
{
++numStages;
}
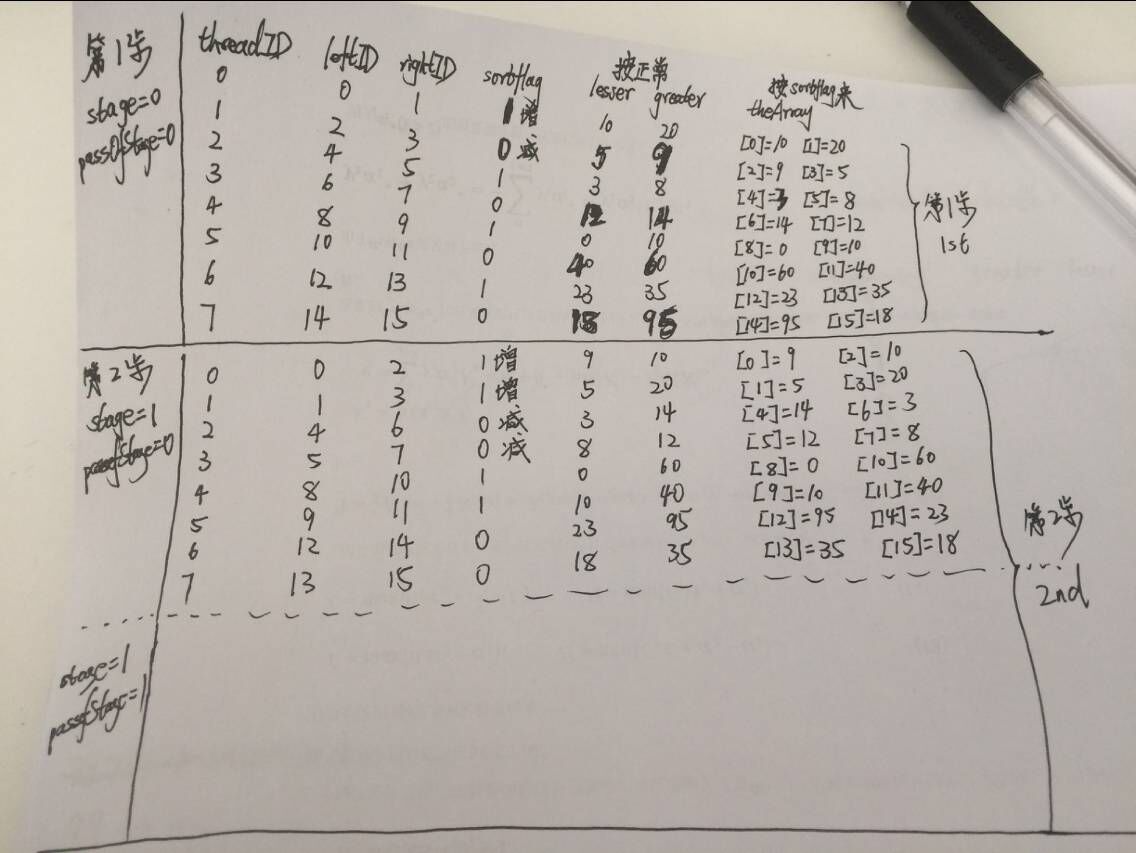
for(stage = 0; stage < numStages; ++stage)
{
printf("step: %d ...\n",stage);
status = clSetKernelArg(kernel, 1, sizeof(cl_uint),(void *)&stage);
CHECK_OPENCL_ERROR(status, "clSetKernelArg failed. (stage)");
// Every stage has stage + 1 passes
for(passOfStage = 0; passOfStage < stage + 1; ++passOfStage)
{
// pass of the current stage
status = clSetKernelArg(kernel,2,sizeof(cl_uint),(void *)&passOfStage);
CHECK_OPENCL_ERROR(status, "clSetKernelArg failed. (passOfStage)");
cl_event ndrEvt;
status = clEnqueueNDRangeKernel(commandQueue,kernel,1,NULL,globalThreads,localThreads, 0,NULL,&ndrEvt);
CHECK_OPENCL_ERROR(status, "clEnqueueNDRangeKernel failed.");
status = clFlush(commandQueue);
CHECK_OPENCL_ERROR(status, "clFlush failed.");
status = clWaitForEvents(1,&ndrEvt);
status = clReleaseEvent(ndrEvt);
CHECK_ERROR(status, 0, "WaitForEventAndRelease(ndrEvt) Failed");
}
}
cl_uint *input2 = (cl_uint*)clEnqueueMapBuffer(commandQueue,inputBuffer,CL_TRUE,CL_MAP_READ,0,inputSizeBytes,0,NULL,NULL,&status);
CHECK_ERROR(status, SDK_SUCCESS,"Failed to map device buffer.(inputBuffer in run())");
status = clEnqueueUnmapMemObject(commandQueue, inputBuffer, input2, 0,NULL,NULL);
CHECK_ERROR(status, SDK_SUCCESS, "Failed to unmap device buffer.(inputBuffer in run())");
/CPU results
const cl_uint halfLength = length/2;
cl_uint i;
for(i = 2; i <= length; i *= 2)
{
cl_uint j;
for(j = i; j > 1; j /= 2)
{
cl_bool increasing = sortFlag;
const cl_uint half_j = j/2;
cl_uint k;
for(k = 0; k < length; k += j)
{
const cl_uint k_plus_half_j = k + half_j;
cl_uint l;
if(i < length)
{
if((k == i) || round(((k % i) == 0) && (k != halfLength)))
{
increasing = !increasing;
}
}
for(l = k; l < k_plus_half_j; ++l)
{
if(increasing)
{
swapIfFirstIsGreater(&verificationInput[l], &verificationInput[l + half_j]);
}
else
{
swapIfFirstIsGreater(&verificationInput[l + half_j], &verificationInput[l]);
}
}
}
}
}
for(int index=0;index<16;index++)
{
printf(" CPU-result:%d GPU-result:%d \n",verificationInput[index],input2[index]);
}
if(memcmp(input2, verificationInput, length*sizeof(cl_uint)) == 0)
{
std::cout<<"Passed!\n" << std::endl;
return SDK_SUCCESS;
}
else
{
std::cout<<"Failed\n" << std::endl;
return SDK_FAILURE;
}
status = clReleaseKernel(kernel);
CHECK_OPENCL_ERROR(status, "clReleaseKernel failed.");
status = clReleaseProgram(program);
CHECK_OPENCL_ERROR(status, "clReleaseProgram failed.");
status = clReleaseMemObject(inputBuffer);
CHECK_OPENCL_ERROR(status, "clReleaseMemObject failed.");
status = clReleaseCommandQueue(commandQueue);
CHECK_OPENCL_ERROR(status, "clReleaseCommandQueue failed.");
status = clReleaseContext(context);
CHECK_OPENCL_ERROR(status, "clReleaseContext failed.");
status=clReleaseDevice(device);
FREE(verificationInput);
return 0;
}__kernel
void bitonicSort(__global uint * theArray,
const uint stage,
const uint passOfStage,
const uint direction)
{
uint sortIncreasing = direction;
uint threadId = get_global_id(0);
uint pairDistance = 1 << (stage - passOfStage);//every pairDistance data compare 2
uint blockWidth = 2 * pairDistance; //every blockWidth up and down 4
uint leftId = (threadId % pairDistance) + (threadId / pairDistance) * blockWidth;
uint rightId = leftId + pairDistance;
uint leftElement = theArray[leftId];
uint rightElement = theArray[rightId];
uint sameDirectionBlockWidth = 1 << stage;
if((threadId/sameDirectionBlockWidth) % 2 == 1)
sortIncreasing = 1 - sortIncreasing;
uint greater;
uint lesser;
if(leftElement > rightElement)
{
greater = leftElement;
lesser = rightElement;
}
else
{
greater = rightElement;
lesser = leftElement;
}
if(sortIncreasing)
{
theArray[leftId] = lesser;
theArray[rightId] = greater;
}
else
{
theArray[leftId] = greater;
theArray[rightId] = lesser;
}
/* for debug...
barrier(CLK_LOCAL_MEM_FENCE);
if(get_local_id(0)==0)
{
for(uint t=0;t!=16;t++)
{
printf("index:%d data:%d \n",t,theArray[t]);
}
}
*/
}
注意:
1、我以前没见过CL_MAP_WRITE_INVALIDATE_REGION 这种标志的?!
大神说:此标志是为了优化可能的传输(回向, 从GPU的显存到CPU的内存)而提出的. 此标志暗示事先不需要读取旧内容的, 因为host很可能下步进行全面覆盖的写入. 但是否遵循此标志是可选的, 也就是说, 带有INVALIDATE_REGION的可能没有效果. 但对于AMD的特有的显存映射过来的内存, 建议在逻辑允许的情况下(即你不需要在host上读的时候), 总是使用它.
今天终于明白了这个标志的意思:画出来就是这样。
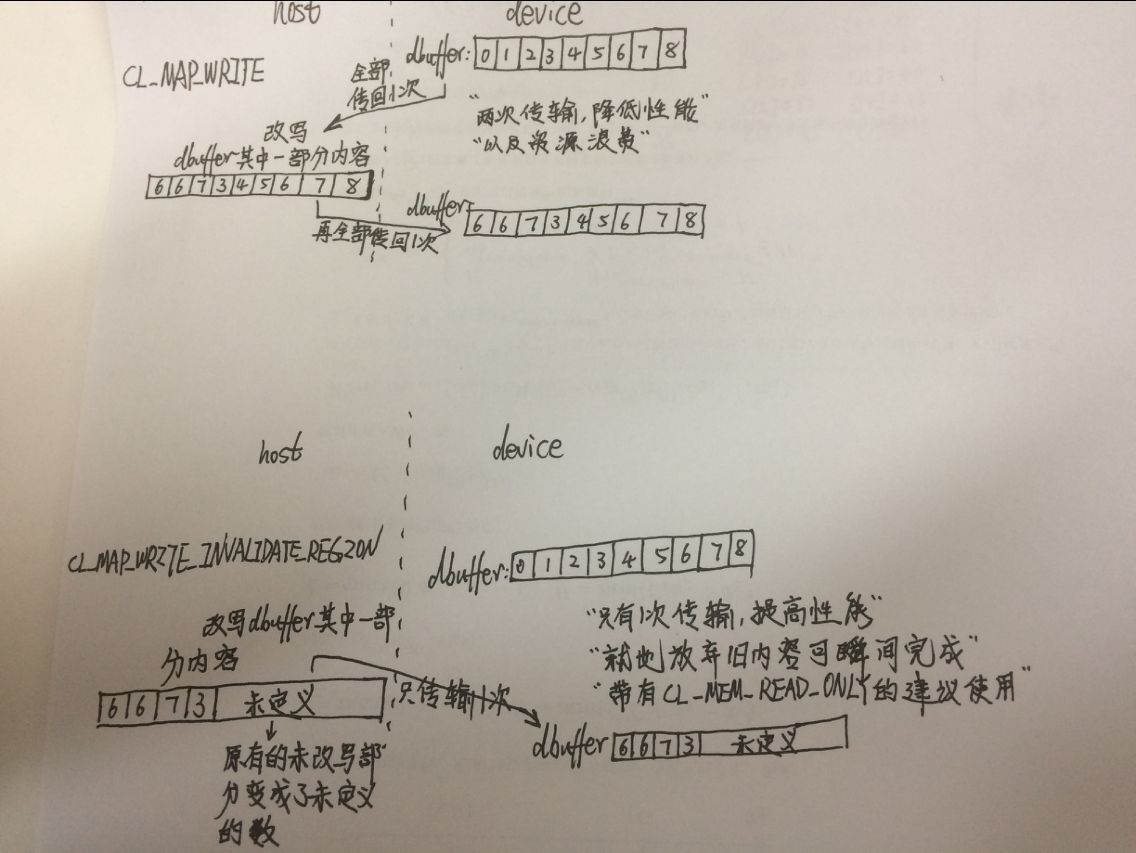
2、CL_MEM_READ_WRITE类型的buffer竟然可以map的哦?!
大神说:这个可以map的. 不一定必须是CPU内部后备的才可以map. 但如果是普通显存的, 实现可能会引入自动的隐式传输.此时将等于一次甚至多次你手工的传输过程, 而不是0成本的.
3、这种循环调用cl文件的,多次给kernel传不同的实参并调用!(你以前告诉我map最好是用在kernel中只使用一次的变量,因为使用完这次就自动回host了,在这个例子里我看到这个buffer只是CL_MEM_READ_WRITE类型的buffer,在host端给这个kernel传不同的实参并执行NDRange,也就是启动了N次kernel,CPU端是阻塞的,循环执行完毕后,将那个buffer的最终结果map回host,这样不会违反你说的,看来的确是不会。是host端用阻塞没有让执行第一次循环时就自动map回来,对吧?)
大神说:之前说的是, kernel只输出结果, 然后host上只读的, 这种kernel只保存1次, 以后用不到了, 应当考虑CPU上的内存后备的zero-copy的buffer, 因为回传将和你的指令执行互相掩盖.
4、这个实例运行成功了,但我在CodeXL下调试时竟然没有NDRange这句的?!
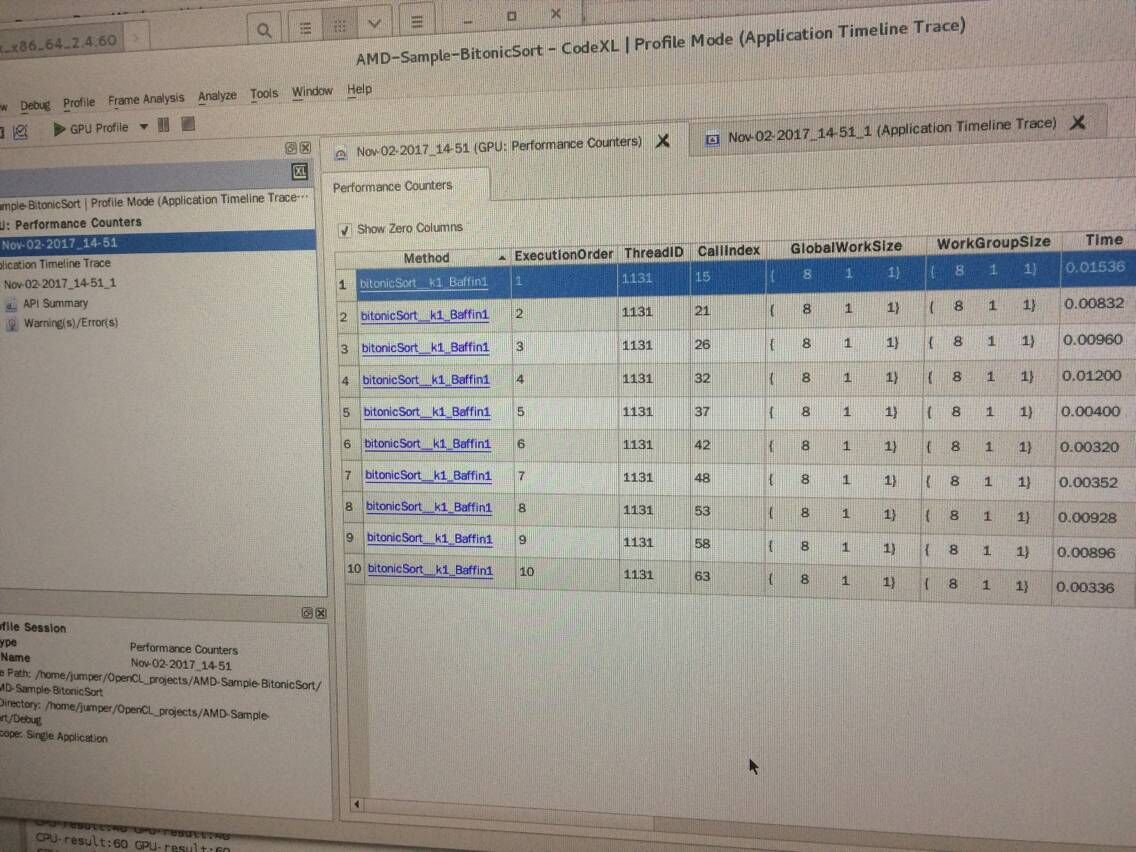
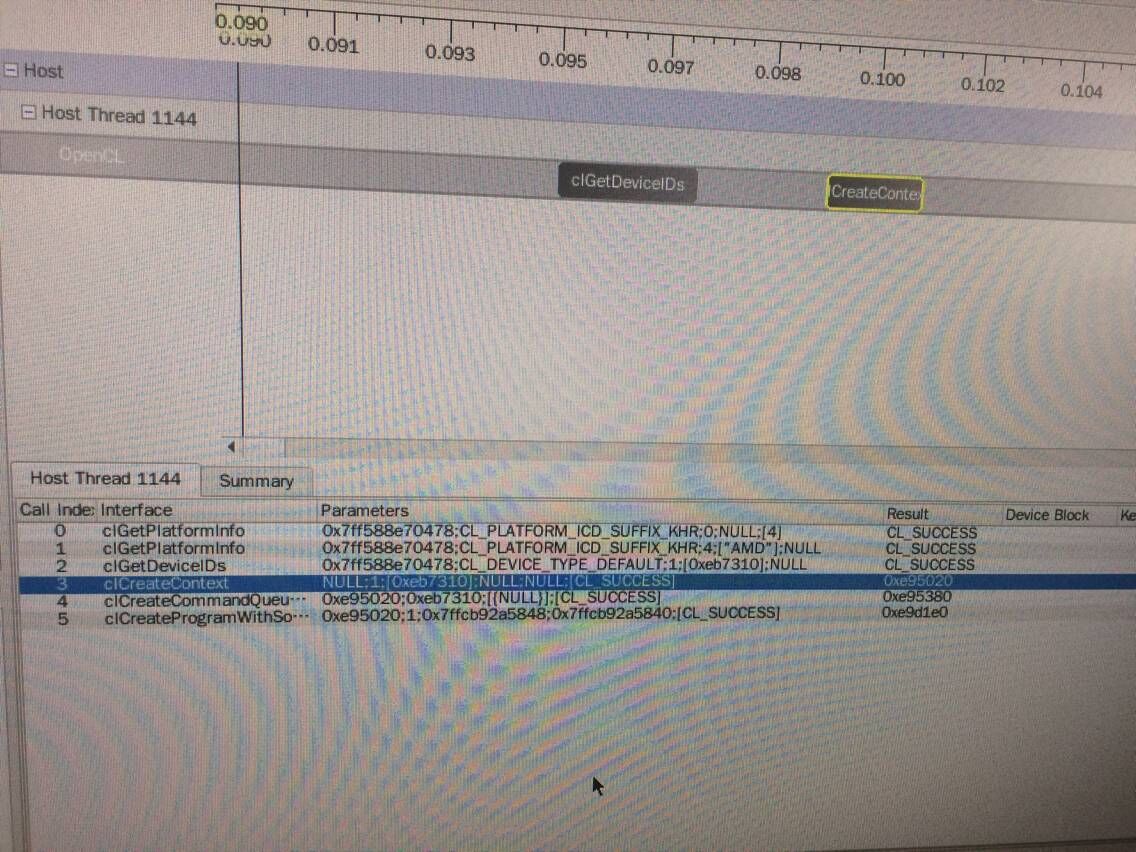
应该是我自己操作的问题:我启动的items太少,总共都只有8个!是我举例时没举好导致的。
5、矢量比标量快?
大神说:但是矢量是否必须比标量快, 这个是否定的.如果你的代码必须依靠矢量化才有性能的话, 往往代表你kernel的其他方面的问题.例如过小的一次启动的线程数.















 1016
1016











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











