










-
亲,你们可知淘宝目前每天活跃数据量超过50TB,每天有超过4000万人次的访问,大约要处理几亿次的用户行为。面对如此巨大的数据访问量,淘宝利用oracle RAC系统,构建自己的数据库奇迹。现在淘宝店小二YY有个想法,如何把一段信息最大限度的压缩,例如字符串abababab就可以看成是abab和abab的连接,在库中可以用串abab2来表示,但是你会发现这个压缩串并不是最好的,可以进一步压缩成ab4。需要注意的是优秀的压缩算法,在获取高压缩率的同时,也会耗费大量的cpu资源。淘宝是一个讲究实际效益的公司,在带宽资源能够承受的前提下,也需要权衡cpu的消耗,因此淘宝最终的压缩算法,仅仅只将原始串,压缩为一个由字符串和数字构成的形式,详细见题目Hint。亲,你们能实现店小二想法吗?^_^记得给好评哦。
题目描述:
-
输入:
-
输入有多组测试案例。每个测试案例为1行,全由小写英文字母组成,长度不超过100,000。
-
输出:
-
对应每个测试案例,输出最大压缩串,单独占1行。
-
样例输入:
-
aaaaxyzabababababcabcabdabd
-
样例输出:
-
a4xyz1ab4abcabcabdabd1
-
提示:
案例4中,答案不是abc2abd2,因为描述中提过压缩串仅是将原始串完全恰好的分割为一个字符串和数字的形式,因此只能为abcabcabdabd1
算法分析
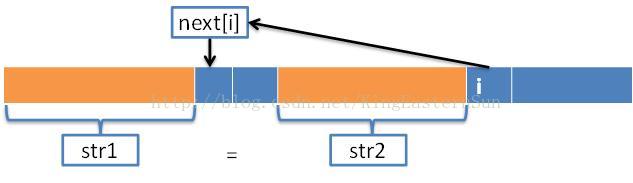
1)首先定义j = next[i], 表示字符串中从0到j-1的子字符串和 i之前的j-1个子字符串相同,如下图所示。
2)如果字符串可以表示为多个重复子字符串,则必定存在i,j满足
0到j为所求子字符串,j+1到i为所求子字符串,并且i,j同时向右移动,s[i]==s[j],直到i = s.size()-1,如下图

3)我们的思路就是寻找i,j,使i、j同时向右移动并比较。
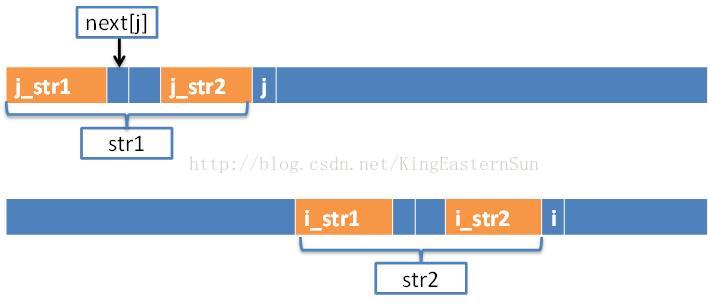
4)如下图,假设i,j移动到某个位置时,s[i] != s[j], 无法得到编码子字符串,需要重新定位 j 的位置。
由于j之前的子字符串 和 i之前的子字符串一定是相同的,所以j重新定位到的位置要保证j之前和i之前有相同的子字符串。
j_str1 == j_str2
str1==str2
i_str1 == i_str2
所以 j_str1 =i_str2
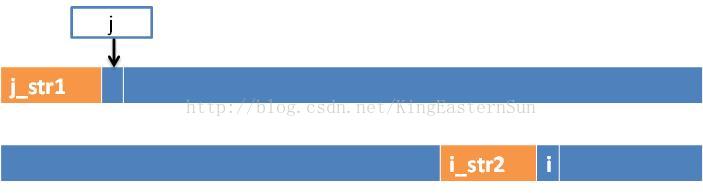
5)判断s.at(j)和s.at(i)是否相同,回到了之前的步骤4)上,当j==-1时,j++,i++
源代码:
需要注意的是分配next时,一定要比字符串长度多1,不然会溢出。
因为如果找到了子字符串,j=len-1 时,s.at(j)==s.at(i) ++i;++j, j==sLen
#include <iostream>
#include <string>
using namespace std;
int next[6];
void getMaxNum(std::string &s){
int i = -1;
int j = 0;
int sLen = s.size();
int *next = new int[sLen+1];// attention must be sLen+1
//bacause if j = len-1 and s.at(i)==s.at(j) j++, j == sLen;
next[0]=-1;
while(j<sLen){
if(i==-1 || s.at(i)==s.at(j)){
++i;
++j;
next[j]=i;
}
else{
i = next[i];
}
}
int subStrLen = j-i;
if(sLen % subStrLen)
std::cout<<s<<"1"<<std::endl;
else
std::cout<<s.substr(0,subStrLen)<<sLen/subStrLen<<std::endl;
}
void test(){
std::string s = "abab";
getMaxNum(s);
}
void judo(){
std::string s;
while(std::cin>>s){
getMaxNum(s);
}
}
int main() {
//cout << "!!!Hello World!!!" << endl; // prints !!!Hello World!!!
judo();
//test();
return 0;
}














 2971
2971











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









