







一种面向电信行业基站数据的数据采集系统的设计与实现
1,项目简介
本论文来源于上海电信应急指挥平台。上海电信应急指挥平台主要是采集上海所有基站的一些与应急相关的实时数据,将这些数据做统计分析工作之后,在web浏览器上展示出来,便于电信上级的部门做决策。由于本人主要负责数据采集模块的架构、设计和开发工作。对这个领域有点体会,本篇文章主要总结这个领域的一些实践工作。
由于在数据采集的领域主要以使用WebService的方式(Apache CXF)和使用ftp两种方式来采集电信的基站数据,本篇文章就以这两种方式展开。
2,使用CXF的数据采集模块的架构设计与性能优化
2.1 系统开发的相关技术
2.1.1 SOAP协议简介:
1, SOAP协议产生
http协议重点是在定义和传输浏览器需要的渲染数据,为了提供更好的服务,比如传输用户需要自己控制的一些数据,SOAP协议和REST协议就比较好的满足了这种要求。由于本次项目重点使用的是SOAP协议,所以重点介绍SOAP协议。
2, SOAP协议概述
SOAP协议全称是简单对象访问协议,是一种标准化的通信协议,主要用于WebService服务。对于Web服务来说,SOAP主要通过xml文档来传递参数。SOAP可以把客户端的数据,远程传递到服务器端,服务器端运行远程方法,然后将结果返回到客户端。
SOAP协议结构由以下四部分组成:
SOAP信封:构造一个整体的SOAP消息表示框,主要用来表示消息的内容,标价消息的发送者和接受者等。
SOAP编码规则:定义一个数据的序列化规则,主要是在应用程序交换信息时的数据类型的确认。
SOAP绑定:它定义了一种约束,用于在实际应用中应用底层协议来完成实际的数据交换。
3, SOAP协议主要内容
<soapenv:Envelope xmlns:soapenv=http://schemas.xmlsoap.org/soap/envelope/xmlns:q0="http://controller.ctsecp.fritt.com/"xmlns:xsd="http://www.w3.org/2001/XMLSchema"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<soap:Header>
</soap:Header>
<soapenv:Body>
</soapenv:Body>
</soapenv:Envelope>
2.1.2 ApacheCXF简介
Apache CXF =Celtix + XFire,Apache CXF 的前身叫 Apache CeltiXfire,现在已经正式更名为 Apache CXF 了,以下简称为 CXF。CXF 继承了 Celtix 和 XFire 两大开源项目的精华,提供了对 JAX-WS 全面的支持,并且提供了多种 Binding 、DataBinding、Transport 以及各种 Format 的支持,并且可以根据实际项目的需要,采用代码优先(Code First)或者 WSDL 优先(WSDL First)来轻松地实现 Web Services 的发布和使用。目前它仍只是 Apache 的一个孵化项目。
Apache CXF 是一个开源的Services 框架,CXF 帮助您利用 Frontend 编程 API 来构建和开发 Services,像 JAX-WS 。这些 Services 可以支持多种协议,比如:SOAP、XML/HTTP、RESTful HTTP 或者 CORBA ,并且可以在多种传输协议上运行,比如:HTTP、JMS 或者 JBI,CXF 大大简化了 Services 的创建,同时它继承了 XFire 传统,一样可以天然地和 Spring 进行无缝集成。
CXF 包含了大量的功能特性,但是主要集中在以下几个方面:
支持 Web Services 标准:CXF 支持多种 WebServices 标准,包含 SOAP、Basic Profile、WS-Addressing、WS-Policy、WS-ReliableMessaging 和 WS-Security。
Frontends:CXF 支持多种“Frontend”编程模型,CXF 实现了 JAX-WSAPI (遵循 JAX-WS 2.0 TCK 版本),它也包含一个“simple frontend”允许客户端和 EndPoint 的创建,而不需要 Annotation 注解。CXF 既支持 WSDL 优先开发,也支持从 Java 的代码优先开发模式。
容易使用: CXF 设计得更加直观与容易使用。有大量简单的 API 用来快速地构建代码优先的 Services,各种 Maven 的插件也使集成更加容易,支持 JAX-WS API ,支持 Spring 2.0 更加简化的 XML 配置方式,等等。
支持二进制和遗留协议:CXF 的设计是一种可插拨的架构,既可以支持 XML ,也可以支持非 XML 的类型绑定,比如:JSON 和 CORBA。
2.1.3 JDBC简介
JDBC是一种可执行SQL语句的JavaAPI(ApplicationProgrammingInterface,应用程序设计接口)。它由一些java语言写的类组成。JDBC给数据库应用开发人员、前台工具开发人员提供了一种标准的应用程序设计接口,使开发人员可以用纯java语言编写完整的数据库应用程序。
通过JDBC,开发人员可以很方便的将SQL语句传送给任何一种数据库。也就是说开发人员不必写一个程序访问Oracle,再写一个程序访问SQLServer。用JDBC写的程序能自动的将SQL语句传送给相应的数据库管理系统(DBMS)。不但如此,使用java编写的应用程序可以在任何支持java的平台上运行,不必在不同的平台上编写不同的应用。Java和JDBC的结合可以让开发人员在开发数据库应用程序时真正实现“WriteOnce、RunEverywhere!”。
2.2 系统的整体架构设计
2.2.1 架构简介
此项目的系统架构图如下:
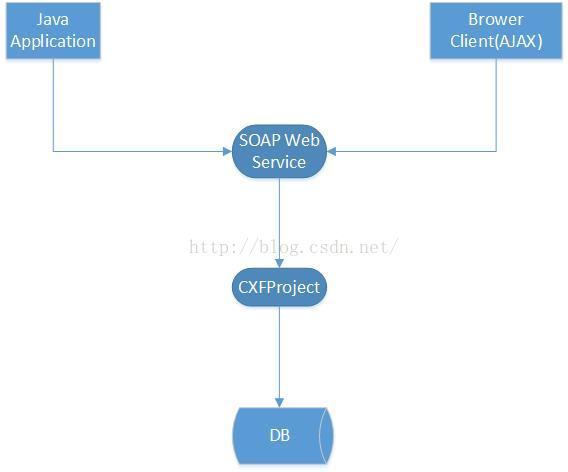
此系统提供对外访问的WebService接口,使用java应用程序或者,浏览器的ajax调用,将数据通过CXFproject将数据保存到数据库中。
2.2.2 详细架构设计
CXFProject部分的数据流程图如下:
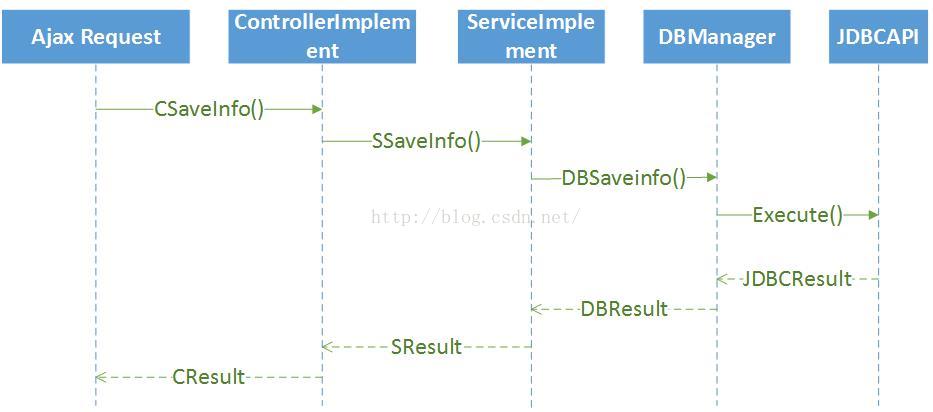
当请求保存的数据通过Ajax发送过来时,分别经过Controller层,Service层,DBManager层和JDBCAPI层。
ControllerImplement层的主要作用是:在http协议传输数据的时候,使URL连接映射的具体的ControllerImplent层对应的对象上,当一旦接受到通过http协议传输过来的数据,服务器会在内存中会创建ControllerImplement相对应的对象,同时根据xml配置会找到相应的function,在函数的参数中,函数会根据xml配置件映射成相应的配置对象,在函数体里面既可以实现对接受到的需要上传的数据的处理。在本系统的设计中Controller层的主要目的是接收数据,并初步对数据格式进行相关的验证。
ServiceImplement层的主要作用是:接收ControllerImplement层传过来的经过验证的数据,和为下层提供针对当前传来的做存储或者更新时需要的sql语句。
DBManager层的主要作用是:(1)对上层调用者而言:接收ServiceImplement层传来的数据和sql语句。(2)对下层服务提供者而言是封装JDBCAPI接口提供,提供数据存储相关的服务。
JDBCAPI层的主要作用是:封装对数据库进行操作的各种类,这些类由java语言提供,本系统主要用到了数据的保存、更新、查询、事务处理、批量处理等功能。
2.2.3 异常处理
本系统的一项重要的功能是对外提供WebService接口,为了便于调用接口的人能够及时了解数据存储过程中出现的问题,本系统需要设计比较完善的异常处理的机制和协议。
首先要有一套协议便于服务调用者理解当前上传的数据是否是成功存储到数据库中,协议的标记如下图:
| 返回值代码 | 表示意义 |
| 0 | 表示数据成功上传到服务器 |
| 1 | 传入的参数不全 |
| 2 | 表示上传数据失败 |
数据上传失败很大一部分原因是在调用JDBCAPI的时候,某些与数据库交互的过程出现的异常。我们在处理这些问题时使用java的异常处理机制,使用java的throw机制,将错误不断上传给调用它的函数,最后在ControllerImplement层的catch的代码段中将错误信息返回给服务调用者。
2.3 性能测试
2.3.1 测试环境
系统配置如下:
应用服务器:
1,cpu Intel(R) Xeon(R)CPU
2,内存 4G
3,使用的是Tomcat服务器
数据库服务器:
1,cpu Intel(R) Xeon(R)CPU
2,内存 4G
3,使用的是mysql数据库
2.3.2 单线程上传数据的性能总结
性能测试是在优化jdbc接口之后,使用大批量数据调用CXF框架的单次请求的性能。测试时单次存储11条数据(对应数据库中一张表的11列)。使用的是批量接口。
进行批量测试的性能指标如下:
| 插入条数 | 使用时间(ms) | 服务器内存消耗 | 数据库服务器内存消耗 | 碰到问题 |
| 1000 | 234 | 15.2% |
| |
| 10000 | 1552 | 15.2% | 10.6% |
|
| 20000 | 2988 | 15.2% | 10.6% |
|
| 30000 | 4462 | 15.2% | 10.6% |
|
| 40000 | 6353 | 15.2% | 10.6% |
|
| 50000 |
|
|
| 超出最大范围 |
| 60000 |
|
|
|
|
由于ApacheCXF的框架设计时单次上传节点的最大个数是50000,批量上传的最大条数超过50000时,会报系统越界错误。
我们使用单次固定条数的批量插入方法,单次插入30000条,在收到成功的返回值时,继续发送,性能测试如下:
| 插入条数 | 使用时间(ms) | 服务器内存消耗 | 数据库服务器内存消耗 | 碰到问题 |
| 30000 | 4745 | 15.1% | 10.6% |
|
| 60000 | 9619 | 15.2% | 10.6% |
|
| 90000 | 13996 | 15.1% | 11.1% |
|
| 120000 | 19955 | 15.3% | 9.7% |
|
| 150000 | 24116 | 15.3% | 9.7% |
|
| 180000 | 28803 | 16.2% | 9.6% |
|
| 210000 | 34582 | 16.2% | 9.7% |
|
| 240000 | 39197 | 16.2% | 9.7% |
|
| 270000 | 43431 | 15.9% | 9.7% |
|
| 300000 | 49849 | 15.9% | 9.7% |
|
| 600000 | 104182(1.73min) | 16.0% | 9.7% |
|
| 900000 | 229348(3.82min) | 16.2% | 9.7% |
|
| 1200000 | 514626(8.5771min) | 16.1% | 9.7% |
|
| 1500000 | 894118(14.9min) | 16.3% | 9.6% |
|
|
|
|
|
|
|
通过以上指标我们可以得出的规律是:
1, 在实际的采集数据时,单个接口15分钟上传数据的上线是150万条。
2, 在mysql数据库中,在数据量增大的情况下,插入的速度会越来越慢,在数据库管理的过程中最好要考虑到这种情况。
2.3.3 多线程上传数据的性能总结
测试时两台机器一共启动四个线程单次存储12条、12条、5条、4条数据(分别对应数据库中的4张表)。使用的是批量接口。
发送方式3万条内实时发送,满3万条每隔3万条发送一次,性能测试如下:
| 插入条数 | 总时间(ms) | 实际时间(ms) | 线程1 | 线程2 | 线程3 | 线程4 | 服务器内存消耗 | 数据库服务器内存消耗 | 出现问题 |
| 10000 | 7020 (0.12min) | 1907 (0.03min) | 1907 (0.03min) | 1696 (0.03min) | 1817 (0.03min) | 1601 (0.03min) | 13.6% | 10.4% |
|
| 20000 | 14477 (0.24min) | 3956 (0.07min) | 3305 (0.06min) | 4123 (0.07min) | 3956 (0.07min) | 3093 (0.05min) | 14.1% | 10.4% |
|
| 30000 | 18033 (0.30min) | 4763 (0.08min) | 4317 (0.07min) | 4716 (0.08min) | 4763 (0.08min) | 4237 (0.07min) | 14.6% | 10.3% |
|
| 60000 | 38889 (0.65min) | 10974 (0.18min) | 8779 (0.15min) | 10974 (0.18min) | 10144 (0.17min) | 8992 (0.15min) | 15.0% | 10.3% |
|
| 90000 | 59639 (0.99min) | 16632 (0.28min) | 13632 (0.23min) | 16632 (0.28min) | 16107 (0.27min) | 13268 (0.22min) | 15.1% | 10.3% |
|
| 120000 | 89813 (1.50min) | 25607 (0.43min) | 19336 (0.32min) | 25702 (0.43min) | 25607 (0.43min) | 19168 (0.32min) | 16.7% | 10.3% |
|
| 150000 | 109672 (1.83min) | 32030 (0.53min) | 23901 (0.40min) | 32030 (0.53min) | 30007 (0.50min) | 23734 (0.40min) | 18.4% | 15.4% |
|
| 180000 | 2.28min | 0.65 min | 0.50min | 0.65 min | 0.65min | 0.46 min | 28.9% | 11.0% |
|
| 210000 | 2.60 min | 0.74 min | 0.55 min | 0.74 min | 0.74 min | 0.55min | 27.2% | 11.9% |
|
| 270000 | 3.42min | 0.98min | 0.73min | 0.98min | 0.96min | 0.73min | 27.2% | 10.9% |
|
| 330000 | 4.44min | 1.32min | 0.91min | 1.32min | 1.32min | 0.88min | 27.2% | 10.8% |
|
| 390000 | 6.12min | 1.99min | 1.10min | 1.95min | 1.99min | 1.07min | 27.9% | 10.7% |
|
| 450000 | 9.90min | 3.66min | 1.32min | 3.59min | 3.66min | 1.34min | 28.5% | 10.5% |
|
| 510000 | 13.06min | 5.17min | 1.45min | 5.00min | 5.17min | 1.43min | 28.6% | 10.3% |
|
| 540000 | 15.25min | 6.17min | 1.57min | 5.95min | 6.17min | 1.54min | 28.6% | 10.2% |
|
|
|
|
|
|
|
|
|
|
|
|
通过以上指标我们可以得出如下规律
1,通过cxf采集数据时模拟多线程采集效率大概是216万每6分钟,远远高于非多线程插入的效率,由于利用的mysql线程插入的特点,可以提高系统的插入效率。
3,使用FTP的数据采集模块的架构设计与性能优化
3.1 系统开发的相关技术
3.1.1 ftp协议简介
FTP(FileTransfer Protocol,文件传输协议)是 TCP/IP 协议组中的协议之一。FTP协议包括两个组成部分,其一为FTP服务器,其二为FTP客户端。其中FTP服务器用来存储文件,用户可以使用FTP客户端通过FTP协议访问位于FTP服务器上的资源。在开发网站的时候,通常利用FTP协议把网页或程序传到Web服务器上。此外,由于FTP传输效率非常高,在网络上传输大的文件时,一般也采用该协议。
默认情况下FTP协议使用TCP端口中的 20和21这两个端口,其中20用于传输数据,21用于传输控制信息。但是,是否使用20作为传输数据的端口与FTP使用的传输模式有关,如果采用主动模式,那么数据传输端口就是20;如果采用被动模式,则具体最终使用哪个端口要服务器端和客户端协商决定。
本系统为了安全考虑,使用的是主动模式。
3.1.2 CSV协议简介
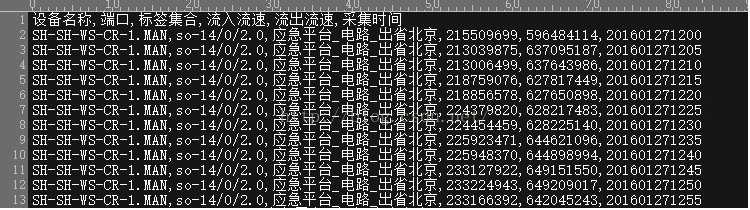
逗号分隔值(Comma-SeparatedValues,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。纯文本意味着该文件是一个字符序列,不含必须像二进制数字那样被解读的数据。CSV文件由任意数目的记录组成,记录间以某种换行符分隔;每条记录由字段组成,字段间的分隔符是其它字符或字符串,最常见的是逗号或制表符。通常,所有记录都有完全相同的字段序列。
在本系统中我们将使用逗号隔开的CSV文件。如下图:
3.1.3 OpenCSV简介
OpenCSV是国外比较流行的一种CSV文件解析的库文件,主要是这个库的开发作者发现没有一种开源、免费的库,自己便提供了一种开源库。在进行CSV解析时,提供了一种比较友好的接口。
3.1.4 Java流机制简介
1. Java中IO简介
IO(Input AndOutput)在编程中是一个很常见的需求,IO即意味着我们的java程序需要和"外部"进行通信,这个"外部"可以是很多介质
(1) 本地磁盘文件、远程磁盘文件
(2) 数据库连接
(3) TCP、UDP、HTTP网络通信
4) 进程间通信
5) 硬件设备(键盘、串口等)
...
2. Java中的流
IO是我们的目的,而要达到这一目的,我们需要一种机制来帮助我们完全,这种机制就是"流"、或者叫"数据流"。
数据流是一串连续不断的数据的集合,就象水管里的水流,在水管的一端一点一点地供水,而在水管的另一端看到的是一股连续不断的水流。数据写入程序可以是一段、一段地向数据流管道中写入数据,这些数据段会按先后顺序形成一个长的数据流。对数据读取程序来说,看不到数据流在写入时的分段情况,每次可以读取其中的任意长度的数据,但只能先读取前面的数据后,再读取后面的数据。不管写入时是将数据分多次写入,还是作为一个整体一次写入,读取时的效果都是完全一样的。
3.2 系统的整体架构设计
3.2.1 架构简介
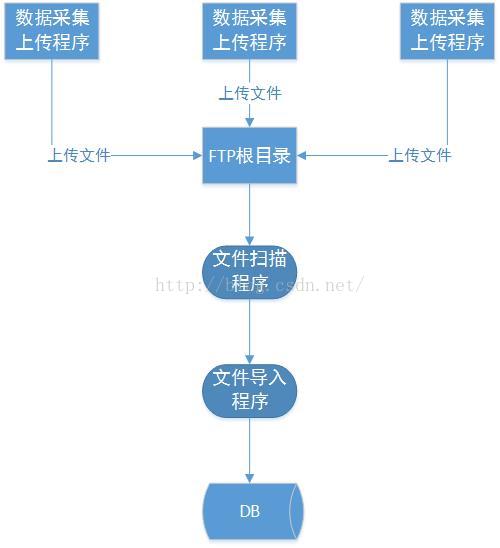
ftp的文件采集系统的大概的数据流程是:用户会通过数据采集程序将CSV格式的数据文件上传到ftp服务器的根目录上面。我们会启动一个定时器也就是java的Timer类定期扫描ftp的根目录,然后通过OpenCSV或者Java的流机制将文件数据导入到数据库中。
3.2.2 详细架构设计
文件扫描和文件导入模块的数据流程图如下:
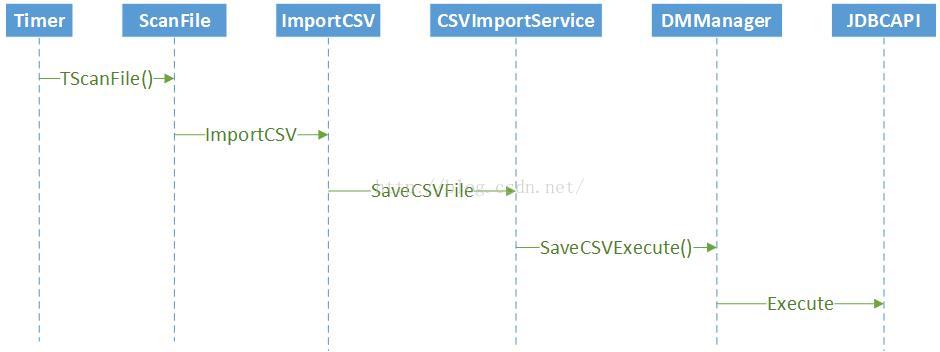
Timer是java的jdk中的一个类,Timer可以在指定的时间内启动一个线程,做一些事情。本系统主要使用Timer类,定期执行文件扫描和导入程序,完成数据的采集工作。
ScanFile主要做的事情是扫描文件系统,可以根据java的File类拿到文件列表,通过文件列表可以将文件导入到内存,然后可以对文件做一些处理。
ImportCSV主要是通过java的流机制,拿到每一行的CSV文件数据,对数据做一些处理之后,将数通过Service层将数据导入到数据库中。
CSVImportService层的主要作用是:接收ImportCSV层传过来的经过验证的数据,和对下层服务提供需要调用的sql语句。
DBManager层的主要作用是:(1)对上层调用者而言:接收ServiceImplement层传来的数据和sql语句。(2)对下层服务提供者而言是封装JDBCAPI接口提供,提供数据存储相关的服务。
JDBCAPI层的主要作用是:封装对数据库进行操作的各种类,这些类由java语言提供,本系统主要用到了数据的保存、更新、查询、事务处理、批量处理等功能。
3.3 性能测试
3.3.1 简介
本系统在数据采集时,使用csv的格式将数据上传到服务器上,再通过Java的文件操作和流操作,获取上传文件的信息,最后通过CSVReader读或者java的流机制获取上传的文件信息,最后通过jdbc接口将文件信息存储到数据库中。
3.3.2 测试环境
系统配置如下:
应用服务器:
1, cpu inteli3
2, 内存 8G
数据库服务器:
1,cpu Intel(R)Xeon(R) CPU
2,内存 4G
3, 使用的是mysql数据库
3.3.3 批量接口单批次上传性能总结
性能测试是在优化jdbc接口之后,使用大批量数据测试扫描存储文件的性能。测试时单次存储5条数据。使用的是批量接口。
进行批量测试的性能指标如下:
| 插入条数 | 使用时间(ms) | 服务器内存消耗 | 数据库服务器内存消耗 | 碰到问题 |
| 100 | 833 | 35.5M | 15.7% |
|
| 1000 | 3971 | 54.5M | 15.7% |
|
| 10000 | 13399 | 111.5M | 15.7% |
|
| 20000 | 19639 | 154M | 15.7% |
|
| 30000 | 27308 | 188M | 14.7% |
|
| 100000 | 90039 (1.5min) | 453M | 15.7% |
|
| 200000 | 204598(3.4min) | 847M | 15.7% |
|
| 300000 | 295438(4.9min) | 1014M | 15.7% |
|
| 400000 | 1093927(18.2min) | 1292M | 15.7% |
|
| 500000 | 1570964(26.2min) | 1433M | 15.7% |
|
| 600000 | 1668328(27.8min) | 1780M | 15.7% |
|
| 700000 | 2372982(39.5min) | 1855M | 15.7% |
|
| 800000 | 2865081(47.8min) | 2015M | 15.7% |
|
| 900000 | 3584745(59.7min) | 2129M | 15.7% | 单笔90万条消耗时间比较长 |
| 1000000 |
| 2095M |
| java.lang.OutOfMemoryError: GC overhead limit exceeded |
3.3.3 批量接口分批上传的性能总结
将数组获取到的数据,在插入数据库时,单次批量插入10000。测试结果如下。
| 插入条数 | 使用时间(ms) | 服务器内存消耗 | 数据库服务器内存消耗 | 碰到问题 |
| 100 | 833 | 35.5M | 15.7% |
|
| 1000 | 3971 | 54.5M | 15.7% |
|
| 10000 | 13399 | 111.5M | 15.7% |
|
| 20000 | 22684 | 157M | 15.7% |
|
| 30000 | 30716 | 208M | 15.7% |
|
| 100000 | 95958(1.5min) | 463M | 15.7% |
|
| 200000 | 180388 (3.0min) | 384M | 15.7% |
|
| 300000 | 275388 (4.5min) | 420M | 15.7% |
|
| 400000 | 377242 (6.28min) | 505M | 15.7% |
|
| 500000 | 527830(8.8min) | 552M | 15.7% |
|
| 600000 | 588103(9.8min) | 726M | 15.7% |
|
| 700000 | 723151(12.1min) | 880M | 15.7% |
|
| 800000 | 901322(15.0min) | 850M | 15.7% |
|
| 900000 | 1113462(18.6min) | 928M | 15.7% |
|
| 1000000 | 1325419(22.0min) | 806M | 15.7% |
|
| 1500000 | 2179144(36.3min) | 1097M | 15.7% |
|
| 2000000 | 3569986(59.5min) | 1562M | 15.7% |
|
| 3000000 |
|
|
|
|
3.3.4 使用java的流机制的性能总结
采用Java流机制,在插入数据库时,单次批量插入10000。测试结果如下。
| 插入条数 | 使用时间(ms) | 服务器内存消耗 | 数据库服务器内存消耗 | 碰到问题 |
| 100 | 273 | 40.4M | 15.8% |
|
| 1000 | 1236 | 51.4M | 15.8% |
|
| 10000 | 9645 | 91.5M | 15.8% |
|
| 20000 | 21685 | 134M | 15.8% |
|
| 30000 | 27509 | 201M | 15.8% |
|
| 100000 | 89067(1.5min) | 198M | 15.8% |
|
| 200000 | 175856(2.9min) | 186M | 15.8% |
|
| 300000 | 265390(4.4min) | 196M | 15.8% |
|
| 400000 | 356549(5.9min) | 202M | 15.8% |
|
| 500000 | 453659(7.6min) | 202M | 15.8% |
|
| 600000 | 576562(9.6min) | 199M | 15.8% |
|
| 700000 | 730090(12.2min) | 200M | 15.8% |
|
| 800000 | 769520(12.8min) | 200M | 15.8% |
|
| 900000 | 1124001(18.7min) | 209M | 15.8% |
|
| 1000000 | 1341186(22.4min) | 202M | 15.8% |
|
| 1500000 | 2566401(42.8min) | 204M | 15.8% |
|
| 2000000 |
|
|
|
|
3.3.5 性能比较
三种性能优化的方案总结如下:
|
| 上传时间 | web服务器内存消耗 |
| 批量接口单批次上传性能 | 时间比较长 | 内存消耗比较大,过早的出现内存溢出 |
| 批量接口分批上传性能 | 时间比较合理 | 内存消耗一般 |
| Java流机制上传性能 | 时间比较合理 | 内存消耗比较小 |
通过ftp机制采集数据,在数据量比较大的情况下,有两条优化思路,一条是使用批量插入时控制好单次批量插入的条数。第二条是最好使用java底层的机制,开源软件有时在设计时考虑的东西太多,会增加系统的资源消耗。
4,总结
本篇文章围绕电信行业的基站数据采集系统展开,总体讲述了通过cxf和ftp两种方式来采集基站数据的架构设计和性能总结。为解决类似需求提供一种比较通用的解决方案。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









