







转载请注明源地址:http://blog.csdn.net/weijonathan/article/details/41749151
最近忙于在整一个客户的流式抽取的方案,结果遇到了很多问题;主要还是编码问题;先说下场景
场景:
用户生成每一个小时的开始生成一个日志文件,不停的往日志文件中写入。而我这块则是实时读取客户的日志文件然后解析入库;
这里我们选择的方案还是以前的由flume来读取;然后写入kafka,最后到storm中进行解析到最后入库;
这一个流程方案大家应该都比较熟悉了。也不用我在赘述;不清楚的可以看我的博客文章:http://blog.csdn.net/weijonathan/article/details/18301321
问题1:
如何做到实时抽取文件数据以及文件变更?
分析:
我们知道flume exec是通过tail命令监控一个文件的日志变化。那么现在我们有多个文件,怎么办?每个小时会有一个,而且你要去实时监控;
用Spooling Directory Source么?好像不是很现实,而且还会造成用户目录生成大量的文件;Spooling Directory Source只监控目录文件的变更,而不监控日志文件内容的变更。
最终还是选用exec方式;那么怎么做到让flume通过exec方式实现实时监控客户服务器上生成的文件呢?
解决方案:
通过脚本动态修改flume的配置文件的监控日志名称;
#!/usr/bin/env bash
# replace flume monitor file information
#defines param
curdate=`date +"%Y-%m-%d_%H"`
filePrefix="sqllog"
curFile=$filePrefix"_"$curdate
source ~/.profile
#Stop Agent Server
#kill -9 `ps -ef | grep flume_ztky_streaming.conf | head -1 | awk '{print $2}'`
#replace fileName
cd $FLUME_CONF_DIR
sed -i "s@sqllog_[0-9]\{4\}-\(\(\(0[13578]\|\(10\|12\)\)-\(0[1-9]\|[1-2][0-9]\|3[0-1]\)\)\|\(02-\(0[1-9]\|[1-2][0-9]\)\)\|\(\(0[469]\|11\)-\(0[1-9]\|[1-2][0-9]\|30\)\)\)_[0-9]\{2\}\.log@$curFile\.log@g" $FLUME_CONF_DIR/flume_ztky_streaming.conf
#Start Agent server
#$FLUME_HOME/bin/flume-ng agent --conf $FLUME_CONF_DIR --conf-file $FLUME_CONF_DIR/flume_ztky_streaming.conf --name producer -Dflume.root.logger=INFO,console >> /home/bigdata/1.txt &
这里有一个知识点要跟大家分享下;
当我们通过人为手动修改或者脚本修改flume配置文件的时候,flume监控到配置文件变更会自动重新加载配置文件信息,重新使用新的配置信息进行日志搜集;
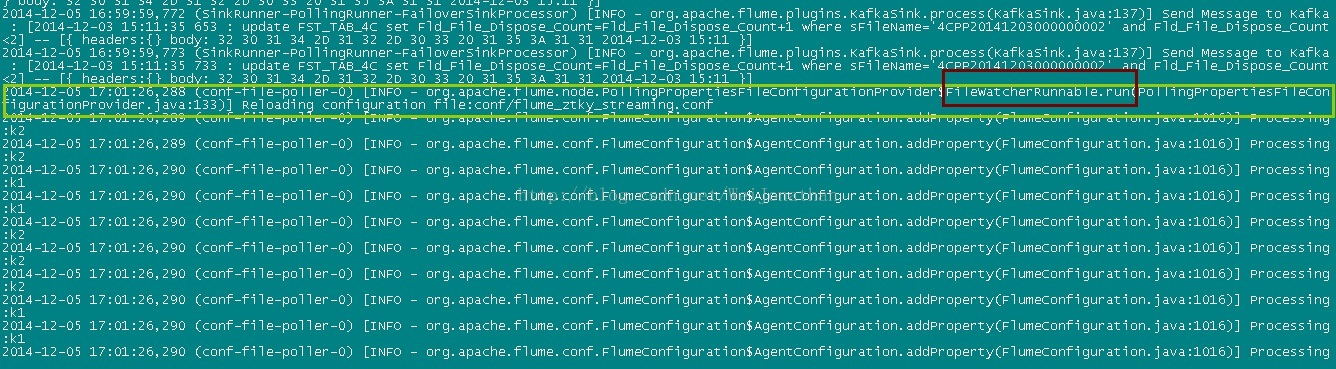
从日志可以看到这个监控代码是在PollingPropertiesFileConfigurationProvider$FileWatcherRunnable.run()方法中
这里通过监控配置文件的最后修改时间来做判断

这里使用到了Google Guava EventBus, 它主要用来简化我们处理生产/消费者编程模型.
上面这个类中,通过eventBus.post()触发实践处理。那么注册的信息和处理类在哪里呢?
看下下面这个类:Application
main方法中
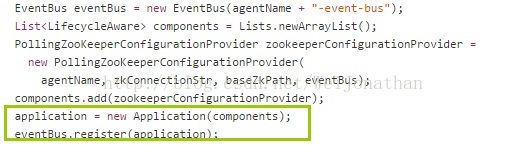
这里eventBus把application处理类注册进去了;
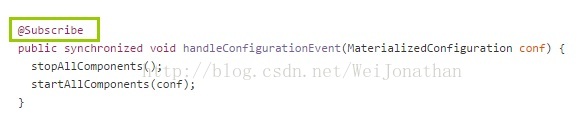
注解@Subscribe是用来标识eventBus的处理方法的;至于一层层的方法调用就不具体解释,想深入了解的可以去看下源码:
https://github.com/apache/flume/blob/f17c7d5022d3e9d112a3843909ad523535fe7e4f/flume-ng-node/src/main/java/org/apache/flume/node/Application.java
解决方案:
那么我们现在只需要编写脚本修改flume的监控配置文件即可;通过crontab -e设置每个小时过一分钟调用脚本修改配置文件,修改写入之后flume会自动停止加载数据并重启;
问题2:
客户提供的日志编码是GBK编码(或者其他编码),整个流程数据跑下来之后,发现storm读取到的数据是乱码。这里我们配置了flume-kafka的日志为UTF-8,按道理是会把GBK编码的日志转换为UTF-8,但是结果出来的却是乱码。
先看看官网的exec文档:
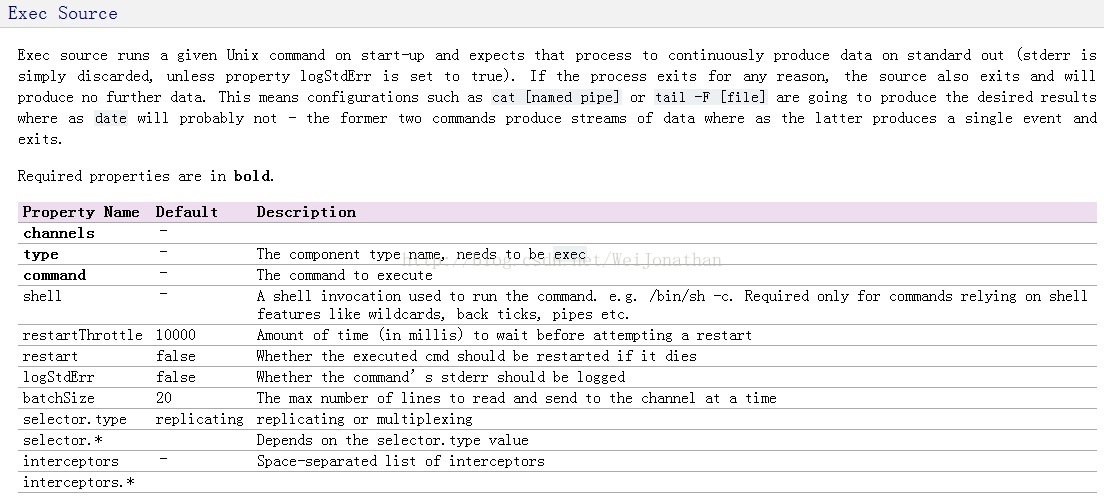
官方文档并没有设置source字符集编码的相关配置;
没办法,看源码吧。
Flume ExecSourceConfigurationConstants--exec的相关配置
https://github.com/apache/flume/blob/8410ad307187b19ca3a4330859815223d1e6b1e2/flume-ng-core/src/main/java/org/apache/flume/source/ExecSourceConfigurationConstants.java
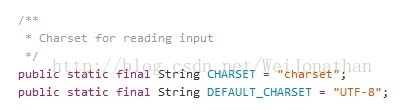
Flume ExecSource
https://github.com/apache/flume/blob/trunk/flume-ng-core/src/main/java/org/apache/flume/source/ExecSource.java

Flume ExecSource的静态内部类ExecRunnable

这里Flume通过process 执行shell命令读取数据流的方式获取数据,且指定相应的charset。
查看源码之后可以了解到。其实我们是可以通过设置source的charset来设置source的编码格式的;但是官方并没有在文档中做配置说明;这样的话。如果你读取的日志不是UTF-8的编码格式的;那么你读取到的数据就只能是乱码的;
flumejg-kafka-plugin插件
KafkaFlumeConstans源码
https://github.com/beyondj2ee/flumeng-kafka-plugin/blob/master/flumeng-kafka-plugin/src/main/java/org/apache/flume/plugins/KafkaFlumeConstans.java
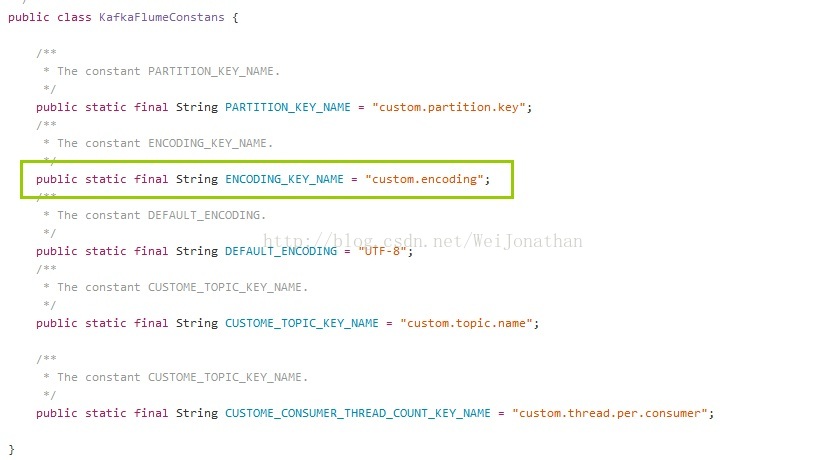
KafkaSink源码
https://github.com/beyondj2ee/flumeng-kafka-plugin/blob/master/flumeng-kafka-plugin/src/main/java/org/apache/flume/plugins/KafkaSink.java
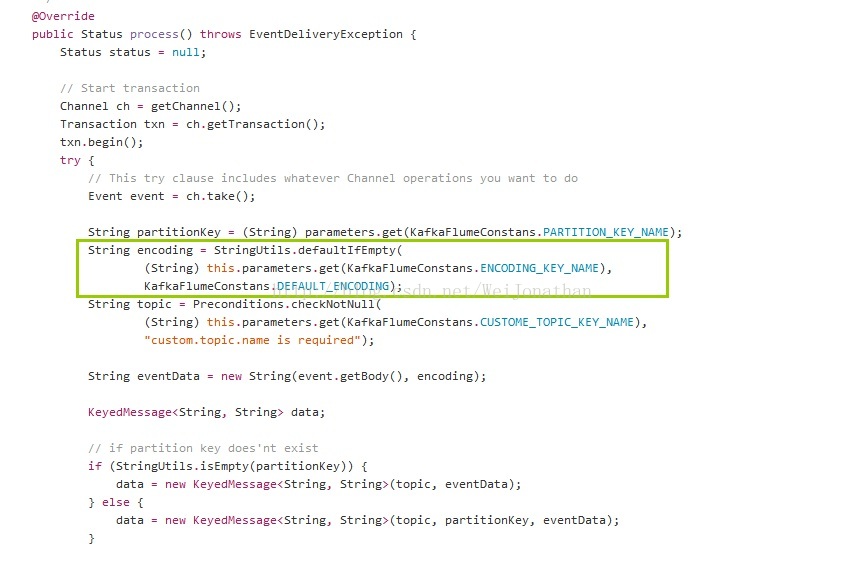
这里插件是读取flume配置文件中的kafkaSink的custom.encoding配置,通过new String(byte[],encoding)的方式做编码转换;
解决方案:
配置Flume exec的charset编码格式以及Flume-kafka的编码格式,最终由storm中获取,统一转码;
这样整个方案就解决了每小时更换日志的问题以及编码问题;














 2065
2065











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









