







Python Basics with Numpy (optional assignment)
Welcome to your first assignment. This exercise gives you a brief introduction to Python. Even if you’ve used Python before, this will help familiarize you with functions we’ll need.
Instructions:
- You will be using Python 3.
- Avoid using for-loops and while-loops, unless you are explicitly told to do so.
- Do not modify the (# GRADED FUNCTION [function name]) comment in some cells. Your work would not be graded if you change this. Each cell containing that comment should only contain one function.
- After coding your function, run the cell right below it to check if your result is correct.
After this assignment you will:
- Be able to use iPython Notebooks
- Be able to use numpy functions and numpy matrix/vector operations
- Understand the concept of “broadcasting”
- Be able to vectorize code
Let’s get started!
About iPython Notebooks
iPython Notebooks are interactive coding environments embedded in a webpage. You will be using iPython notebooks in this class. You only need to write code between the ### START CODE HERE ### and ### END CODE HERE ### comments. After writing your code, you can run the cell by either pressing “SHIFT”+”ENTER” or by clicking on “Run Cell” (denoted by a play symbol) in the upper bar of the notebook.
We will often specify “(≈ X lines of code)” in the comments to tell you about how much code you need to write. It is just a rough estimate, so don’t feel bad if your code is longer or shorter.
Exercise: Set test to "Hello World" in the cell below to print “Hello World” and run the two cells below.
### START CODE HERE ### (≈ 1 line of code)
test = "Hello World"
### END CODE HERE ###print ("test: " + test)test: Hello WorldExpected output:
test: Hello World
What you need to remember:
- Run your cells using SHIFT+ENTER (or “Run cell”)
- Write code in the designated areas using Python 3 only
- Do not modify the code outside of the designated areas
1 - Building basic functions with numpy
Numpy is the main package for scientific computing in Python. It is maintained by a large community (www.numpy.org). In this exercise you will learn several key numpy functions such as np.exp, np.log, and np.reshape. You will need to know how to use these functions for future assignments.
1.1 - sigmoid function, np.exp()
Before using np.exp(), you will use math.exp() to implement the sigmoid function. You will then see why np.exp() is preferable to math.exp().
Exercise: Build a function that returns the sigmoid of a real number x. Use math.exp(x) for the exponential function.
Reminder:
sigmoid(x)=11+e−x
s
i
g
m
o
i
d
(
x
)
=
1
1
+
e
−
x
is sometimes also known as the logistic function. It is a non-linear function used not only in Machine Learning (Logistic Regression), but also in Deep Learning.
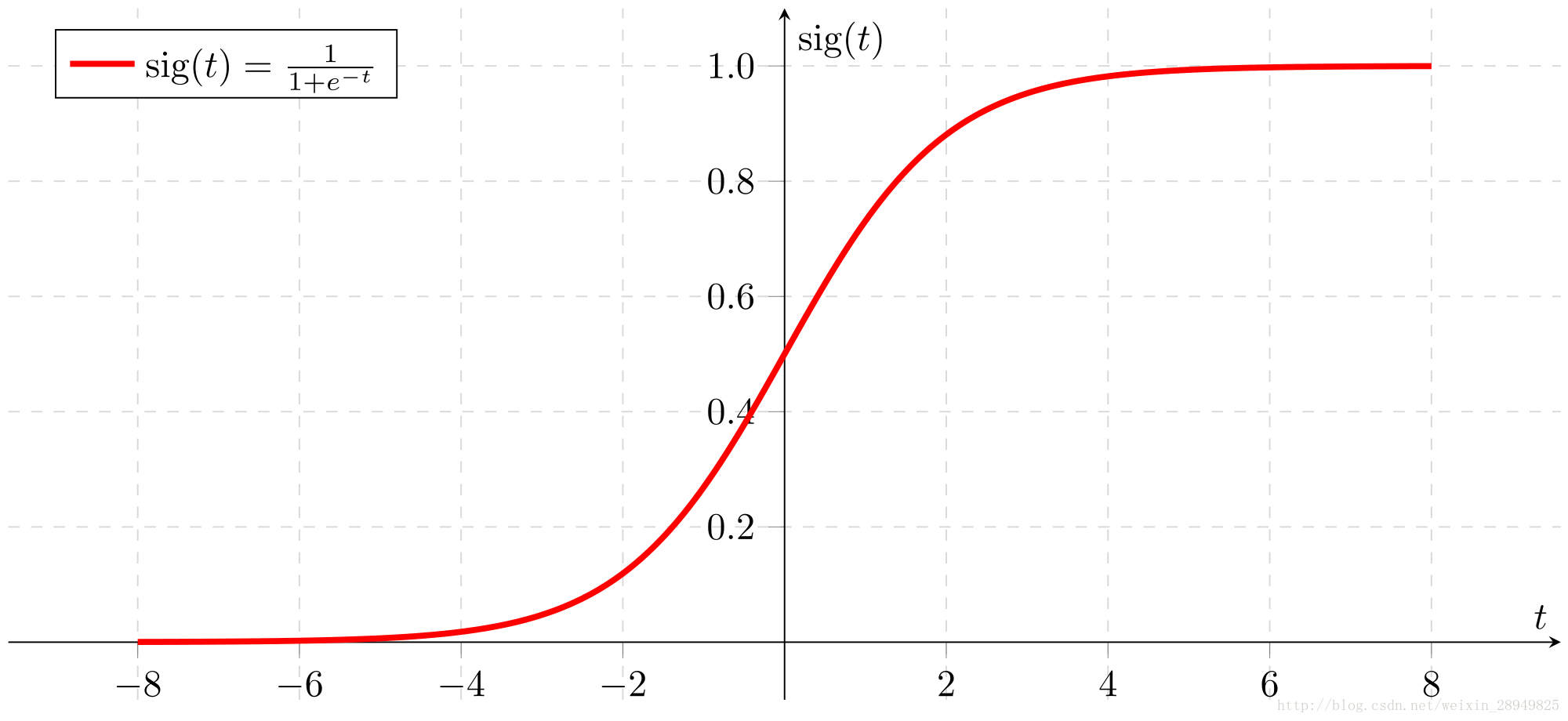
To refer to a function belonging to a specific package you could call it using package_name.function(). Run the code below to see an example with math.exp().
# GRADED FUNCTION: basic_sigmoid
import math
def basic_sigmoid(x):
"""
Compute sigmoid of x.
Arguments:
x -- A scalar
Return:
s -- sigmoid(x)
"""
### START CODE HERE ### (≈ 1 line of code)
s = 1./(1. + math.e ** (-x))
### END CODE HERE ###
return sbasic_sigmoid(3)0.9525741268224331Expected Output:
| basic_sigmoid(3) | 0.9525741268224334 |
Actually, we rarely use the “math” library in deep learning because the inputs of the functions are real numbers. In deep learning we mostly use matrices and vectors. This is why numpy is more useful.
### One reason why we use "numpy" instead of "math" in Deep Learning ###
x = [1, 2, 3]
basic_sigmoid(x) # you will see this give an error when you run it, because x is a vector.
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-5-2e11097d6860> in <module>()
1 ### One reason why we use "numpy" instead of "math" in Deep Learning ###
2 x = [1, 2, 3]
----> 3 basic_sigmoid(x) # you will see this give an error when you run it, because x is a vector.
<ipython-input-3-570b67cbe81c> in basic_sigmoid(x)
15
16 ### START CODE HERE ### (≈ 1 line of code)
---> 17 s = 1./(1. + math.e ** (-x))
18 ### END CODE HERE ###
19
TypeError: bad operand type for unary -: 'list'
In fact, if x=(x1,x2,...,xn) x = ( x 1 , x 2 , . . . , x n ) is a row vector then np.exp(x) n p . e x p ( x ) will apply the exponential function to every element of x. The output will thus be: np.exp(x)=(ex1,ex2,...,exn) n p . e x p ( x ) = ( e x 1 , e x 2 , . . . , e x n )
import numpy as np
# example of np.exp
x = np.array([1, 2, 3])
print(np.exp(x)) # result is (exp(1), exp(2), exp(3))[ 2.71828183 7.3890561 20.08553692]
Furthermore, if x is a vector, then a Python operation such as s=x+3 s = x + 3 or s=1x s = 1 x will output s as a vector of the same size as x.
# example of vector operation
x = np.array([1, 2, 3])
print (x + 3)[4 5 6]Any time you need more info on a numpy function, we encourage you to look at the official documentation.
You can also create a new cell in the notebook and write np.exp? (for example) to get quick access to the documentation.
Exercise: Implement the sigmoid function using numpy.
Instructions: x could now be either a real number, a vector, or a matrix. The data structures we use in numpy to represent these shapes (vectors, matrices…) are called numpy arrays. You don’t need to know more for now.
# GRADED FUNCTION: sigmoid
import numpy as np # this means you can access numpy functions by writing np.function() instead of numpy.function()
def sigmoid(x):
"""
Compute the sigmoid of x
Arguments:
x -- A scalar or numpy array of any size
Return:
s -- sigmoid(x)
"""
### START CODE HERE ### (≈ 1 line of code)
s = 1. / (1. + np.exp(-x))
### END CODE HERE ###
return sx = np.array([1, 2, 3])
sigmoid(x)array([ 0.73105858, 0.88079708, 0.95257413])Expected Output:
| sigmoid([1,2,3]) | array([ 0.73105858, 0.88079708, 0.95257413]) |
1.2 - Sigmoid gradient
As you’ve seen in lecture, you will need to compute gradients to optimize loss functions using backpropagation. Let’s code your first gradient function.
Exercise: Implement the function sigmoid_grad() to compute the gradient of the sigmoid function with respect to its input x. The formula is:
You often code this function in two steps:
1. Set s to be the sigmoid of x. You might find your sigmoid(x) function useful.
2. Compute σ′(x)=s(1−s) σ ′ ( x ) = s ( 1 − s )
# GRADED FUNCTION: sigmoid_derivative
def sigmoid_derivative(x):
"""
Compute the gradient (also called the slope or derivative) of the sigmoid function with respect to its input x.
You can store the output of the sigmoid function into variables and then use it to calculate the gradient.
Arguments:
x -- A scalar or numpy array
Return:
ds -- Your computed gradient.
"""
### START CODE HERE
### (2 lines of code)
s = 1./(1. + np.exp(-x))
ds = s * (1 - s)
### END CODE HERE ###
return dsx = np.array([1, 2, 3])
print ("sigmoid_derivative(x) = " + str(sigmoid_derivative(x)))sigmoid_derivative(x) = [ 0.19661193 0.10499359 0.04517666]Expected Output:
| sigmoid_derivative([1,2,3]) | [ 0.19661193 0.10499359 0.04517666] |
1.3 - Reshaping arrays
Two common numpy functions used in deep learning are np.shape and np.reshape().
- X.shape is used to get the shape (dimension) of a matrix/vector X.
- X.reshape(…) is used to reshape X into some other dimension.
For example, in computer science, an image is represented by a 3D array of shape (length,height,depth=3) ( l e n g t h , h e i g h t , d e p t h = 3 ) . However, when you read an image as the input of an algorithm you convert it to a vector of shape (length∗height∗3,1) ( l e n g t h ∗ h e i g h t ∗ 3 , 1 ) . In other words, you “unroll”, or reshape, the 3D array into a 1D vector.
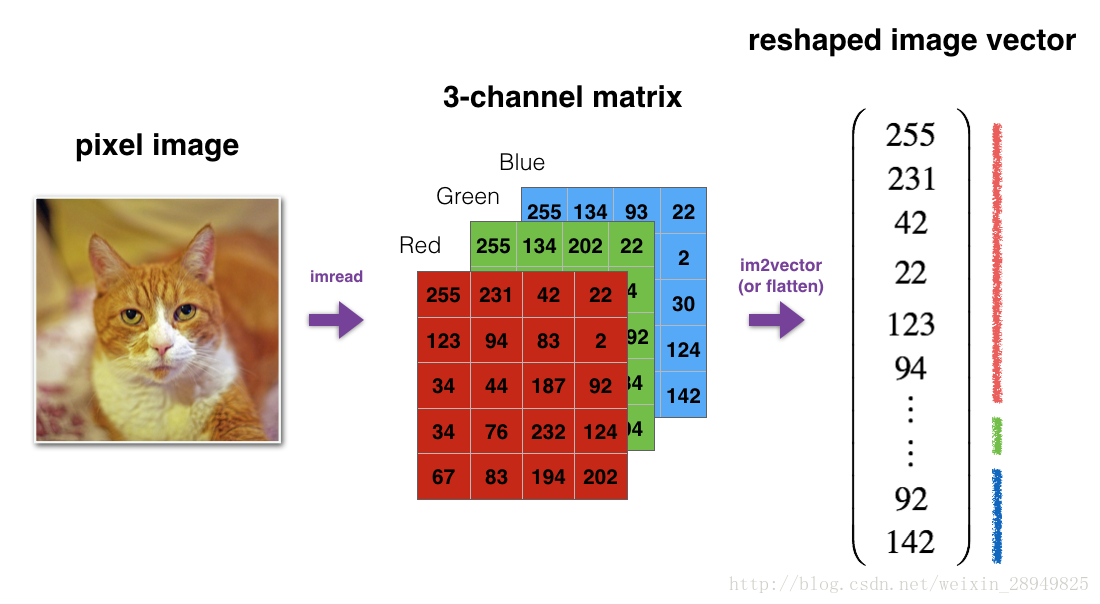
Exercise: Implement image2vector() that takes an input of shape (length, height, 3) and returns a vector of shape (length*height*3, 1). For example, if you would like to reshape an array v of shape (a, b, c) into a vector of shape (a*b,c) you would do:
v = v.reshape((v.shape[0]*v.shape[1], v.shape[2])) # v.shape[0] = a ; v.shape[1] = b ; v.shape[2] = c- Please don’t hardcode the dimensions of image as a constant. Instead look up the quantities you need with
image.shape[0], etc.
# GRADED FUNCTION: image2vector
def image2vector(image):
"""
Argument:
image -- a numpy array of shape (length, height, depth)
Returns:
v -- a vector of shape (length*height*depth, 1)
"""
### START CODE HERE ### (≈ 1 line of code)
v = image.reshape((image.shape[0]*image.shape[1]*image.shape[2], 1));
### END CODE HERE ###
return v# This is a 3 by 3 by 2 array, typically images will be (num_px_x, num_px_y,3) where 3 represents the RGB values
image = np.array([[[ 0.67826139, 0.29380381],
[ 0.90714982, 0.52835647],
[ 0.4215251 , 0.45017551]],
[[ 0.92814219, 0.96677647],
[ 0.85304703, 0.52351845],
[ 0.19981397, 0.27417313]],
[[ 0.60659855, 0.00533165],
[ 0.10820313, 0.49978937],
[ 0.34144279, 0.94630077]]])
print ("image2vector(image) = " + str(image2vector(image)))image2vector(image) = [[ 0.67826139]
[ 0.29380381]
[ 0.90714982]
[ 0.52835647]
[ 0.4215251 ]
[ 0.45017551]
[ 0.92814219]
[ 0.96677647]
[ 0.85304703]
[ 0.52351845]
[ 0.19981397]
[ 0.27417313]
[ 0.60659855]
[ 0.00533165]
[ 0.10820313]
[ 0.49978937]
[ 0.34144279]
[ 0.94630077]]Expected Output:
| image2vector(image) | [[ 0.67826139] [ 0.29380381] [ 0.90714982] [ 0.52835647] [ 0.4215251 ] [ 0.45017551] [ 0.92814219] [ 0.96677647] [ 0.85304703] [ 0.52351845] [ 0.19981397] [ 0.27417313] [ 0.60659855] [ 0.00533165] [ 0.10820313] [ 0.49978937] [ 0.34144279] [ 0.94630077]] |
1.4 - Normalizing rows
Another common technique we use in Machine Learning and Deep Learning is to normalize our data. It often leads to a better performance because gradient descent converges faster after normalization. Here, by normalization we mean changing x to x‖x‖ x ‖ x ‖ (dividing each row vector of x by its norm).
For example, if
Exercise: Implement normalizeRows() to normalize the rows of a matrix. After applying this function to an input matrix x, each row of x should be a vector of unit length (meaning length 1).
# GRADED FUNCTION: normalizeRows
def normalizeRows(x):
"""
Implement a function that normalizes each row of the matrix x (to have unit length).
Argument:
x -- A numpy matrix of shape (n, m)
Returns:
x -- The normalized (by row) numpy matrix. You are allowed to modify x.
"""
### START CODE HERE ### (≈ 2 lines of code)
# Compute x_norm as the norm 2 of x. Use np.linalg.norm(..., ord = 2, axis = ..., keepdims = True)
x_norm = np.linalg.norm(x, ord = 2, axis = 1, keepdims = True)
# Divide x by its norm.
x = x / x_norm
### END CODE HERE ###
return xx = np.array([
[0, 3, 4],
[1, 6, 4]])
print("normalizeRows(x) = " + str(normalizeRows(x)))normalizeRows(x) = [[ 0. 0.6 0.8 ]
[ 0.13736056 0.82416338 0.54944226]]Expected Output:
| normalizeRows(x) | [[ 0. 0.6 0.8 ] [ 0.13736056 0.82416338 0.54944226]] |
Note:
In normalizeRows(), you can try to print the shapes of x_norm and x, and then rerun the assessment. You’ll find out that they have different shapes. This is normal given that x_norm takes the norm of each row of x. So x_norm has the same number of rows but only 1 column. So how did it work when you divided x by x_norm? This is called broadcasting and we’ll talk about it now!
1.5 - Broadcasting and the softmax function
A very important concept to understand in numpy is “broadcasting”. It is very useful for performing mathematical operations between arrays of different shapes. For the full details on broadcasting, you can read the official broadcasting documentation.
Exercise: Implement a softmax function using numpy. You can think of softmax as a normalizing function used when your algorithm needs to classify two or more classes. You will learn more about softmax in the second course of this specialization.
Instructions:
-
for x∈ℝ1×n, softmax(x)=softmax([x1x2…xn])=[ex1∑jexjex2∑jexj...exn∑jexj]
for
x
∈
R
1
×
n
,
s
o
f
t
m
a
x
(
x
)
=
s
o
f
t
m
a
x
(
[
x
1
x
2
…
x
n
]
)
=
[
e
x
1
∑
j
e
x
j
e
x
2
∑
j
e
x
j
.
.
.
e
x
n
∑
j
e
x
j
]
-
for a matrix x∈ℝm×n, xij maps to the element in the ith row and jth column of x, thus we have:
for a matrix
x
∈
R
m
×
n
,
x
i
j
maps to the element in the
i
t
h
row and
j
t
h
column of
x
, thus we have:
softmax(x)=softmax⎡⎣⎢⎢⎢⎢x11x21⋮xm1x12x22⋮xm2x13x23⋮xm3……⋱…x1nx2n⋮xmn⎤⎦⎥⎥⎥⎥=⎡⎣⎢⎢⎢⎢⎢⎢ex11∑jex1jex21∑jex2j⋮exm1∑jexmjex12∑jex1jex22∑jex2j⋮exm2∑jexmjex13∑jex1jex23∑jex2j⋮exm3∑jexmj……⋱…ex1n∑jex1jex2n∑jex2j⋮exmn∑jexmj⎤⎦⎥⎥⎥⎥⎥⎥=⎛⎝⎜⎜⎜⎜softmax(first row of x)softmax(second row of x)...softmax(last row of x)⎞⎠⎟⎟⎟⎟ s o f t m a x ( x ) = s o f t m a x [ x 11 x 12 x 13 … x 1 n x 21 x 22 x 23 … x 2 n ⋮ ⋮ ⋮ ⋱ ⋮ x m 1 x m 2 x m 3 … x m n ] = [ e x 11 ∑ j e x 1 j e x 12 ∑ j e x 1 j e x 13 ∑ j e x 1 j … e x 1 n ∑ j e x 1 j e x 21 ∑ j e x 2 j e x 22 ∑ j e x 2 j e x 23 ∑ j e x 2 j … e x 2 n ∑ j e x 2 j ⋮ ⋮ ⋮ ⋱ ⋮ e x m 1 ∑ j e x m j e x m 2 ∑ j e x m j e x m 3 ∑ j e x m j … e x m n ∑ j e x m j ] = ( s o f t m a x (first row of x) s o f t m a x (second row of x) . . . s o f t m a x (last row of x) )
# GRADED FUNCTION: softmax
def softmax(x):
"""Calculates the softmax for each row of the input x.
Your code should work for a row vector and also for matrices of shape (n, m).
Argument:
x -- A numpy matrix of shape (n,m)
Returns:
s -- A numpy matrix equal to the softmax of x, of shape (n,m)
"""
### START CODE HERE ### (≈ 3 lines of code)
# Apply exp() element-wise to x. Use np.exp(...).
x_exp = np.exp(x)
# Create a vector x_sum that sums each row of x_exp. Use np.sum(..., axis = 1, keepdims = True).
x_sum = np.sum(x_exp, axis = 1, keepdims = True)
# Compute softmax(x) by dividing x_exp by x_sum. It should automatically use numpy broadcasting.
s = x_exp / x_sum
### END CODE HERE ###
return sx = np.array([
[9, 2, 5, 0, 0],
[7, 5, 0, 0 ,0]])
print("softmax(x) = " + str(softmax(x)))softmax(x) = [[ 9.80897665e-01 8.94462891e-04 1.79657674e-02 1.21052389e-04
1.21052389e-04]
[ 8.78679856e-01 1.18916387e-01 8.01252314e-04 8.01252314e-04
8.01252314e-04]]Expected Output:
| softmax(x) | [[ 9.80897665e-01 8.94462891e-04 1.79657674e-02 1.21052389e-04 1.21052389e-04] [ 8.78679856e-01 1.18916387e-01 8.01252314e-04 8.01252314e-04 8.01252314e-04]] |
Note:
- If you print the shapes of x_exp, x_sum and s above and rerun the assessment cell, you will see that x_sum is of shape (2,1) while x_exp and s are of shape (2,5). x_exp/x_sum works due to python broadcasting.
Congratulations! You now have a pretty good understanding of python numpy and have implemented a few useful functions that you will be using in deep learning.
What you need to remember:
- np.exp(x) works for any np.array x and applies the exponential function to every coordinate
- the sigmoid function and its gradient
- image2vector is commonly used in deep learning
- np.reshape is widely used. In the future, you’ll see that keeping your matrix/vector dimensions straight will go toward eliminating a lot of bugs.
- numpy has efficient built-in functions
- broadcasting is extremely useful
2) Vectorization
In deep learning, you deal with very large datasets. Hence, a non-computationally-optimal function can become a huge bottleneck in your algorithm and can result in a model that takes ages to run. To make sure that your code is computationally efficient, you will use vectorization. For example, try to tell the difference between the following implementations of the dot/outer/elementwise product.
import time
x1 = [9, 2, 5, 0, 0, 7, 5, 0, 0, 0, 9, 2, 5, 0, 0]
x2 = [9, 2, 2, 9, 0, 9, 2, 5, 0, 0, 9, 2, 5, 0, 0]
### CLASSIC DOT PRODUCT OF VECTORS IMPLEMENTATION ###
tic = time.process_time()
dot = 0
for i in range(len(x1)):
dot+= x1[i]*x2[i]
toc = time.process_time()
print ("dot = " + str(dot) + "\n ----- Computation time = " + str(1000*(toc - tic)) + "ms")
### CLASSIC OUTER PRODUCT IMPLEMENTATION ###
tic = time.process_time()
outer = np.zeros((len(x1),len(x2))) # we create a len(x1)*len(x2) matrix with only zeros
for i in range(len(x1)):
for j in range(len(x2)):
outer[i,j] = x1[i]*x2[j]
toc = time.process_time()
print ("outer = " + str(outer) + "\n ----- Computation time = " + str(1000*(toc - tic)) + "ms")
### CLASSIC ELEMENTWISE IMPLEMENTATION ###
tic = time.process_time()
mul = np.zeros(len(x1))
for i in range(len(x1)):
mul[i] = x1[i]*x2[i]
toc = time.process_time()
print ("elementwise multiplication = " + str(mul) + "\n ----- Computation time = " + str(1000*(toc - tic)) + "ms")
### CLASSIC GENERAL DOT PRODUCT IMPLEMENTATION ###
W = np.random.rand(3,len(x1)) # Random 3*len(x1) numpy array
tic = time.process_time()
gdot = np.zeros(W.shape[0])
for i in range(W.shape[0]):
for j in range(len(x1)):
gdot[i] += W[i,j]*x1[j]
toc = time.process_time()
print ("gdot = " + str(gdot) + "\n ----- Computation time = " + str(1000*(toc - tic)) + "ms")dot = 278
----- Computation time = 0.15155600000005265ms
outer = [[ 81. 18. 18. 81. 0. 81. 18. 45. 0. 0. 81. 18. 45. 0.
0.]
[ 18. 4. 4. 18. 0. 18. 4. 10. 0. 0. 18. 4. 10. 0.
0.]
[ 45. 10. 10. 45. 0. 45. 10. 25. 0. 0. 45. 10. 25. 0.
0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0.]
[ 63. 14. 14. 63. 0. 63. 14. 35. 0. 0. 63. 14. 35. 0.
0.]
[ 45. 10. 10. 45. 0. 45. 10. 25. 0. 0. 45. 10. 25. 0.
0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0.]
[ 81. 18. 18. 81. 0. 81. 18. 45. 0. 0. 81. 18. 45. 0.
0.]
[ 18. 4. 4. 18. 0. 18. 4. 10. 0. 0. 18. 4. 10. 0.
0.]
[ 45. 10. 10. 45. 0. 45. 10. 25. 0. 0. 45. 10. 25. 0.
0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0.]]
----- Computation time = 0.3951739999998871ms
elementwise multiplication = [ 81. 4. 10. 0. 0. 63. 10. 0. 0. 0. 81. 4. 25. 0. 0.]
----- Computation time = 0.17718799999988377ms
gdot = [ 21.80957178 18.50028153 23.6213424 ]
----- Computation time = 0.23951899999996584msx1 = [9, 2, 5, 0, 0, 7, 5, 0, 0, 0, 9, 2, 5, 0, 0]
x2 = [9, 2, 2, 9, 0, 9, 2, 5, 0, 0, 9, 2, 5, 0, 0]
### VECTORIZED DOT PRODUCT OF VECTORS ###
tic = time.process_time()
dot = np.dot(x1,x2)
toc = time.process_time()
print ("dot = " + str(dot) + "\n ----- Computation time = " + str(1000*(toc - tic)) + "ms")
### VECTORIZED OUTER PRODUCT ###
tic = time.process_time()
outer = np.outer(x1,x2)
toc = time.process_time()
print ("outer = " + str(outer) + "\n ----- Computation time = " + str(1000*(toc - tic)) + "ms")
### VECTORIZED ELEMENTWISE MULTIPLICATION ###
tic = time.process_time()
mul = np.multiply(x1,x2)
toc = time.process_time()
print ("elementwise multiplication = " + str(mul) + "\n ----- Computation time = " + str(1000*(toc - tic)) + "ms")
### VECTORIZED GENERAL DOT PRODUCT ###
tic = time.process_time()
dot = np.dot(W,x1)
toc = time.process_time()
print ("gdot = " + str(dot) + "\n ----- Computation time = " + str(1000*(toc - tic)) + "ms")dot = 278
----- Computation time = 0.1674839999998845ms
outer = [[81 18 18 81 0 81 18 45 0 0 81 18 45 0 0]
[18 4 4 18 0 18 4 10 0 0 18 4 10 0 0]
[45 10 10 45 0 45 10 25 0 0 45 10 25 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[63 14 14 63 0 63 14 35 0 0 63 14 35 0 0]
[45 10 10 45 0 45 10 25 0 0 45 10 25 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[81 18 18 81 0 81 18 45 0 0 81 18 45 0 0]
[18 4 4 18 0 18 4 10 0 0 18 4 10 0 0]
[45 10 10 45 0 45 10 25 0 0 45 10 25 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]]
----- Computation time = 0.14500399999994862ms
elementwise multiplication = [81 4 10 0 0 63 10 0 0 0 81 4 25 0 0]
----- Computation time = 0.13185199999998787ms
gdot = [ 21.80957178 18.50028153 23.6213424 ]
----- Computation time = 0.363171000000051msAs you may have noticed, the vectorized implementation is much cleaner and more efficient. For bigger vectors/matrices, the differences in running time become even bigger.
Note that np.dot() performs a matrix-matrix or matrix-vector multiplication. This is different from np.multiply() and the * operator (which is equivalent to .* in Matlab/Octave), which performs an element-wise multiplication.
2.1 Implement the L1 and L2 loss functions
Exercise: Implement the numpy vectorized version of the L1 loss. You may find the function abs(x) (absolute value of x) useful.
Reminder:
- The loss is used to evaluate the performance of your model. The bigger your loss is, the more different your predictions (
ŷ
y
^
) are from the true values (
y
y
). In deep learning, you use optimization algorithms like Gradient Descent to train your model and to minimize the cost.
- L1 loss is defined as:
# GRADED FUNCTION: L1
def L1(yhat, y):
"""
Arguments:
yhat -- vector of size m (predicted labels)
y -- vector of size m (true labels)
Returns:
loss -- the value of the L1 loss function defined above
"""
### START CODE HERE ### (≈ 1 line of code)
loss = np.sum(np.abs(yhat - y))
### END CODE HERE ###
return lossyhat = np.array([.9, 0.2, 0.1, .4, .9])
y = np.array([1, 0, 0, 1, 1])
print("L1 = " + str(L1(yhat,y)))L1 = 1.1Expected Output:
| L1 | 1.1 |
Exercise: Implement the numpy vectorized version of the L2 loss. There are several way of implementing the L2 loss but you may find the function np.dot() useful. As a reminder, if
x=[x1,x2,...,xn]
x
=
[
x
1
,
x
2
,
.
.
.
,
x
n
]
, then np.dot(x,x) =
∑nj=0x2j
∑
j
=
0
n
x
j
2
.
- L2 loss is defined as
L2(ŷ,y)=∑i=0m(y(i)−ŷ(i))2(7) (7) L 2 ( y ^ , y ) = ∑ i = 0 m ( y ( i ) − y ^ ( i ) ) 2
# GRADED FUNCTION: L2
def L2(yhat, y):
"""
Arguments:
yhat -- vector of size m (predicted labels)
y -- vector of size m (true labels)
Returns:
loss -- the value of the L2 loss function defined above
"""
### START CODE HERE ### (≈ 1 line of code)
loss = np.dot(yhat - y, yhat - y)
### END CODE HERE ###
return lossyhat = np.array([.9, 0.2, 0.1, .4, .9])
y = np.array([1, 0, 0, 1, 1])
print("L2 = " + str(L2(yhat,y)))L2 = 0.43**Expected Output**:
<table style="width:20%">
<tr>
<td> L2 </td>
<td> 0.43 </td>
</tr>
</table>Congratulations on completing this assignment. We hope that this little warm-up exercise helps you in the future assignments, which will be more exciting and interesting!
What to remember:
- Vectorization is very important in deep learning. It provides computational efficiency and clarity.
- You have reviewed the L1 and L2 loss.
- You are familiar with many numpy functions such as np.sum, np.dot, np.multiply, np.maximum, etc…














 455
455











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









