







Spark Streaming简介
Spark Streaming是Spark Core API的一种扩展,它可以用于进行大规模、高吞吐量、容错的实时数据流的处理。它支持从很多种数据源中读取数据,比如Kafka、Flume、Twitter、ZeroMQ、Kinesis或者是TCP Socket。并且能够使用类似高阶函数的复杂算法来进行数据处理,比如map、reduce、join和window。处理后的数据可以被保存到文件系统、数据库、Dashboard等存储中。

Spark Streaming基本工作原理
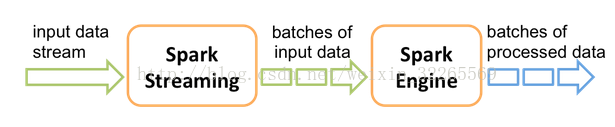
Spark Streaming内部的基本工作原理如下:接收实时输入数据流,然后将数据拆分成多个batch,比如每收集1秒的数据封装为一个batch,然后将每个batch交给Spark的计算引擎进行处理,最后会生产出一个结果数据流,其中的数据,也是由一个一个的batch所组成的。
DStream(一)
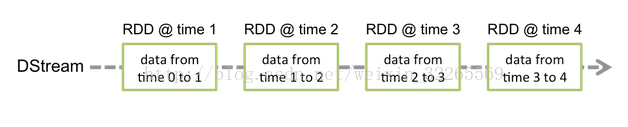
Spark Streaming提供了一种高级的抽象,叫做DStream,英文全称为Discretized Stream,中文翻译为“离散流”,它代表了一个持续不断的数据流。DStream可以通过输入数据源来创建,比如Kafka、Flume和Kinesis;也可以通过对其他DStream应用高阶函数来创建,比如map、reduce、join、window。
DStream的内部,其实一系列持续不断产生的RDD。RDD是Spark Core的核心抽象,即,不可变的,分布式的数据集。DStream中的每个RDD都包含了一个时间段内的数据。
DStream(二)
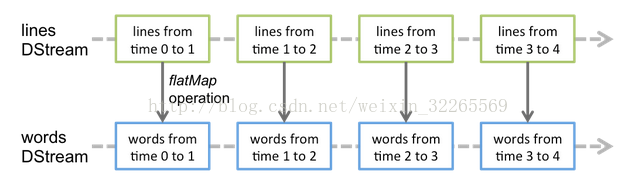
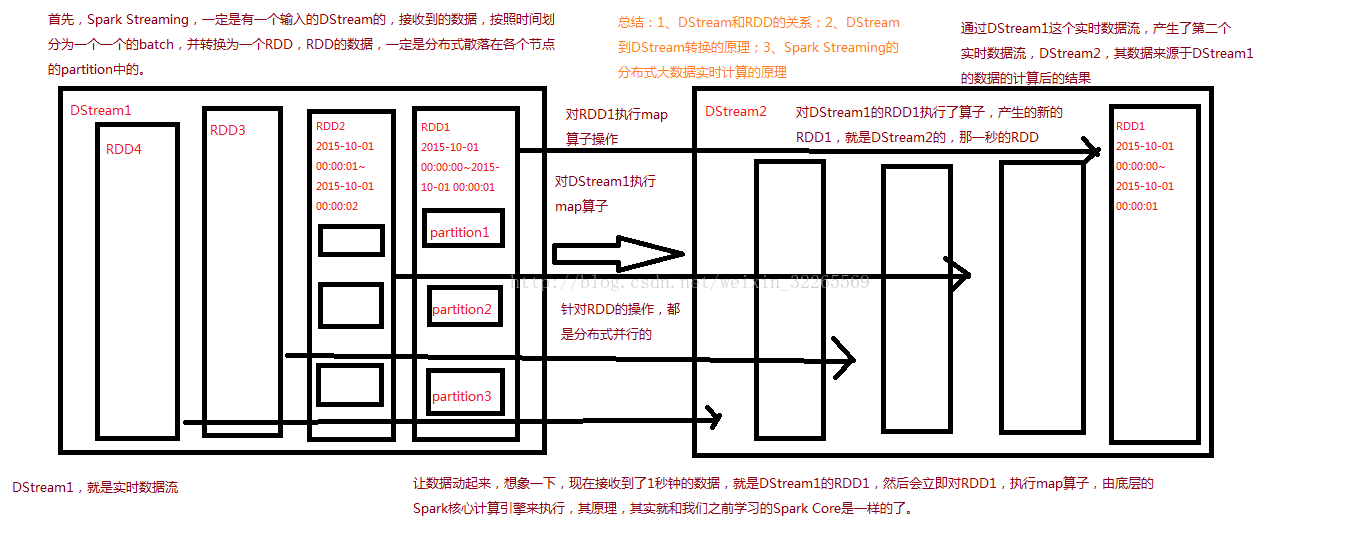
对DStream应用的算子,比如map,其实在底层会被翻译为对DStream中每个RDD的操作。比如对一个DStream执行一个map操作,会产生一个新的DStream。但是,在底层,其实其原理为,对输入DStream中每个时间段的RDD,都应用一遍map操作,然后生成的新的RDD,即作为新的DStream中的那个时间段的一个RDD。底层的RDD的transformation操作,其实,还是由Spark Core的计算引擎来实现的。Spark Streaming对Spark Core进行了一层封装,隐藏了细节,然后对开发人员提供了方便易用的高层次的API。
文章最后,给大家推荐一些受欢迎的技术博客链接:
- Hadoop相关技术博客链接
- Spark 核心技术链接
- JAVA相关的深度技术博客链接
- 超全干货--Flink思维导图,花了3周左右编写、校对
- 深入JAVA 的JVM核心原理解决线上各种故障【附案例】
- 请谈谈你对volatile的理解?--最近小李子与面试官的一场“硬核较量”
- 聊聊RPC通信,经常被问到的一道面试题。源码+笔记,包懂
欢迎扫描下方的二维码或 搜索 公众号“10点进修”,我们会有更多、且及时的资料推送给您,欢迎多多交流!
![]()
















 1946
1946











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











