






新年快乐,上班第一天分享一个python源码,功能比较简单,就是实现酷狗音乐的音乐文件(包含付费音乐)和所有评论回复的下载。
以 米津玄師 - Lemon 为例, 以下为效果图:
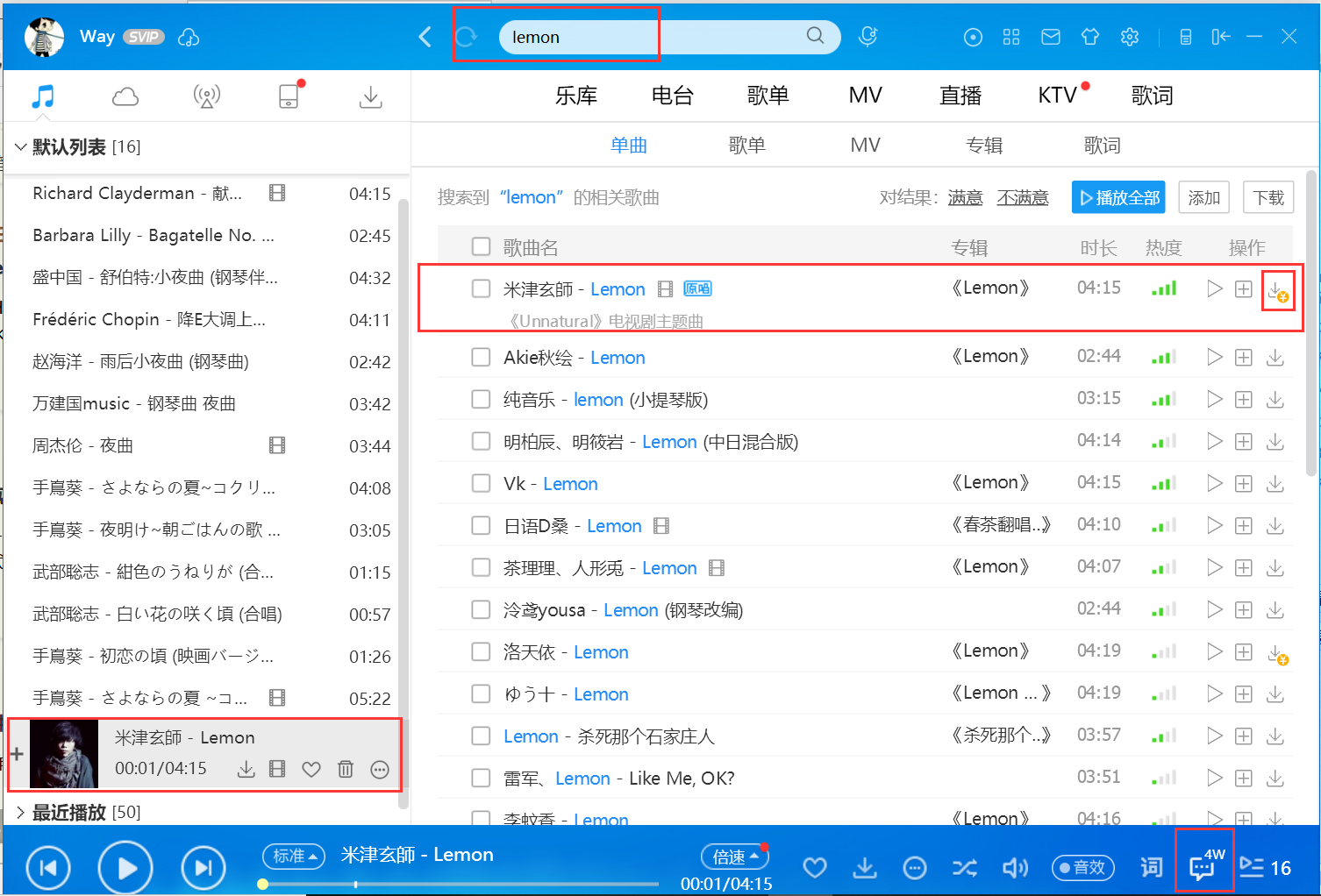
1、根据关键词搜索指定音乐,发现是下载是付费的
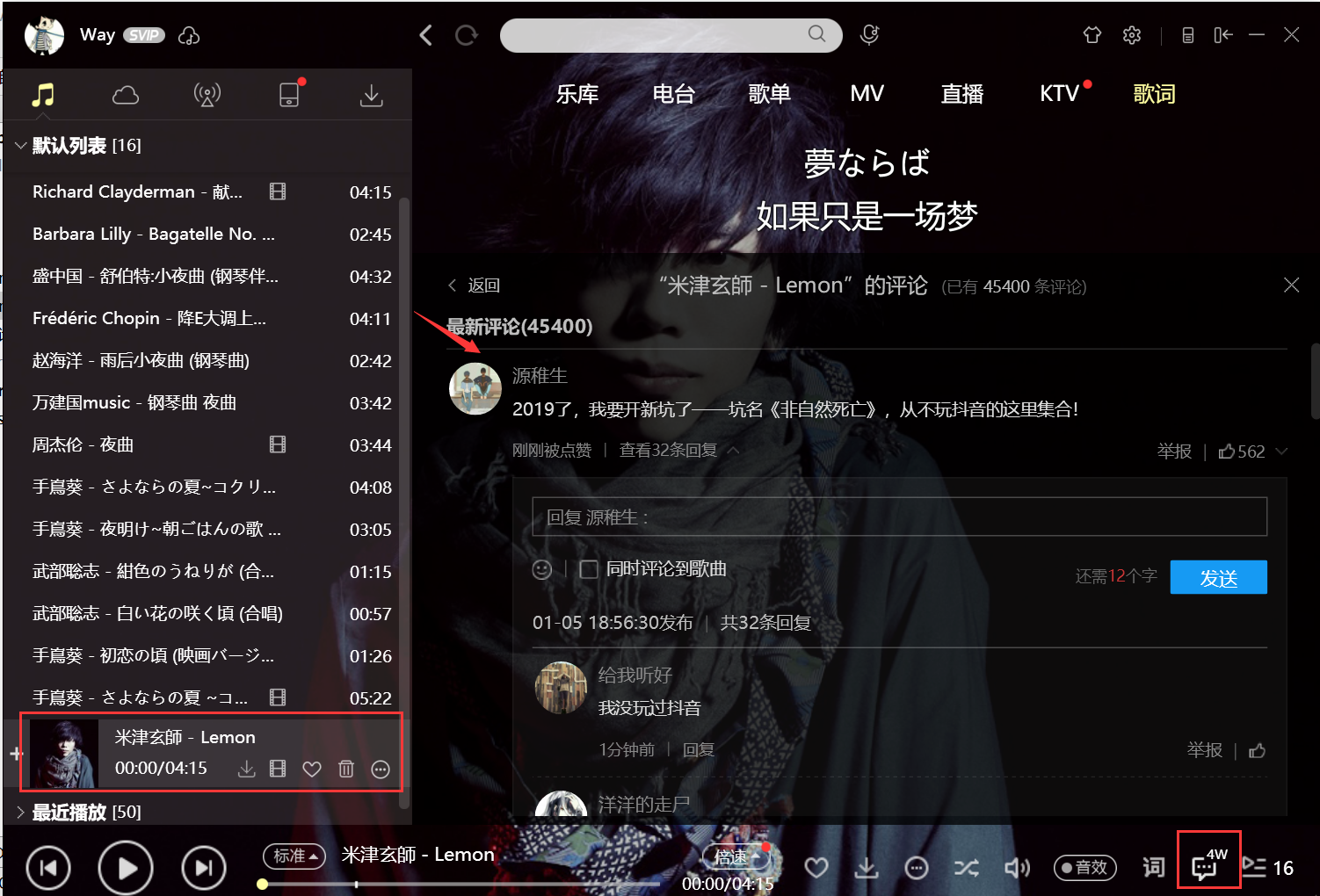
2、点击进入评论,可以看到有很多的评论,评论底下也有很多的回复
3、执行代码下载音乐、评论回复
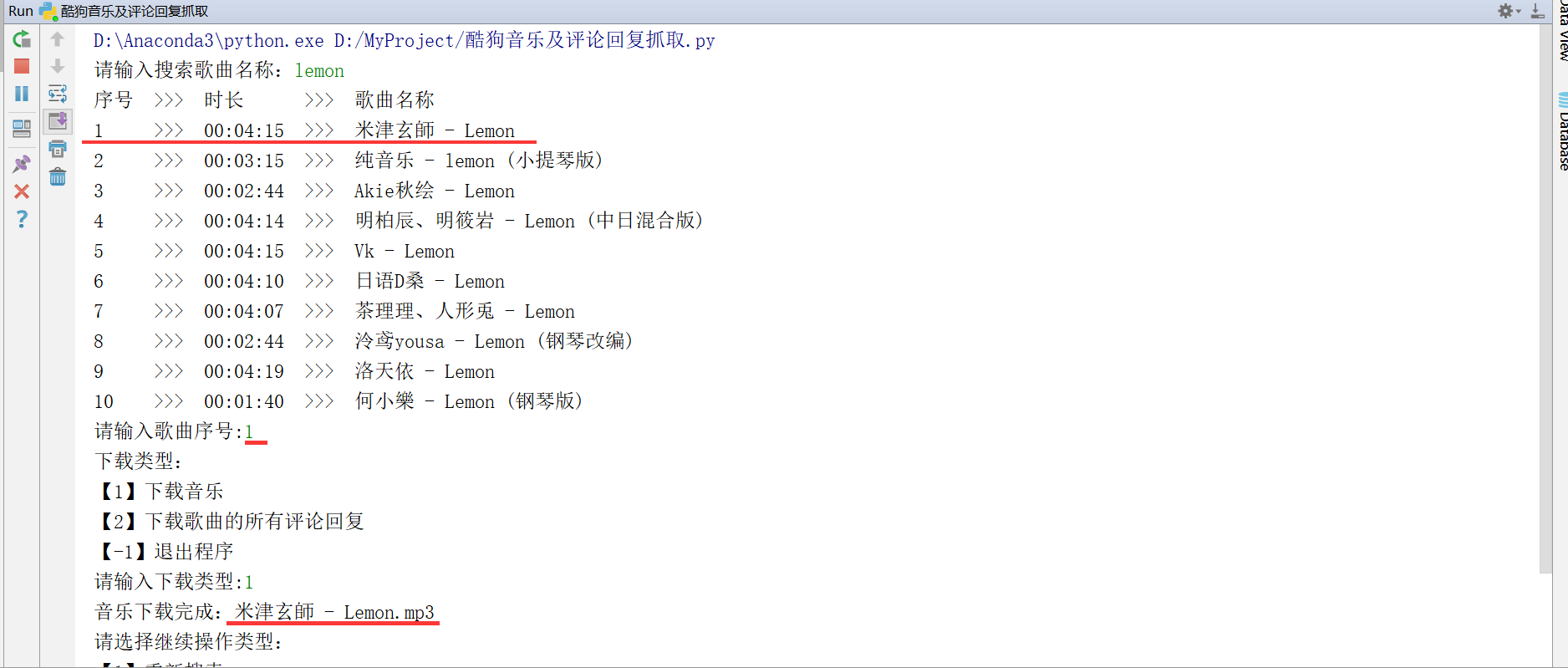
3.1、输入关键词搜索音乐,根据歌曲名称和时长,选择目标歌曲,根据提示下载音乐文件
3.2、下载评论回复
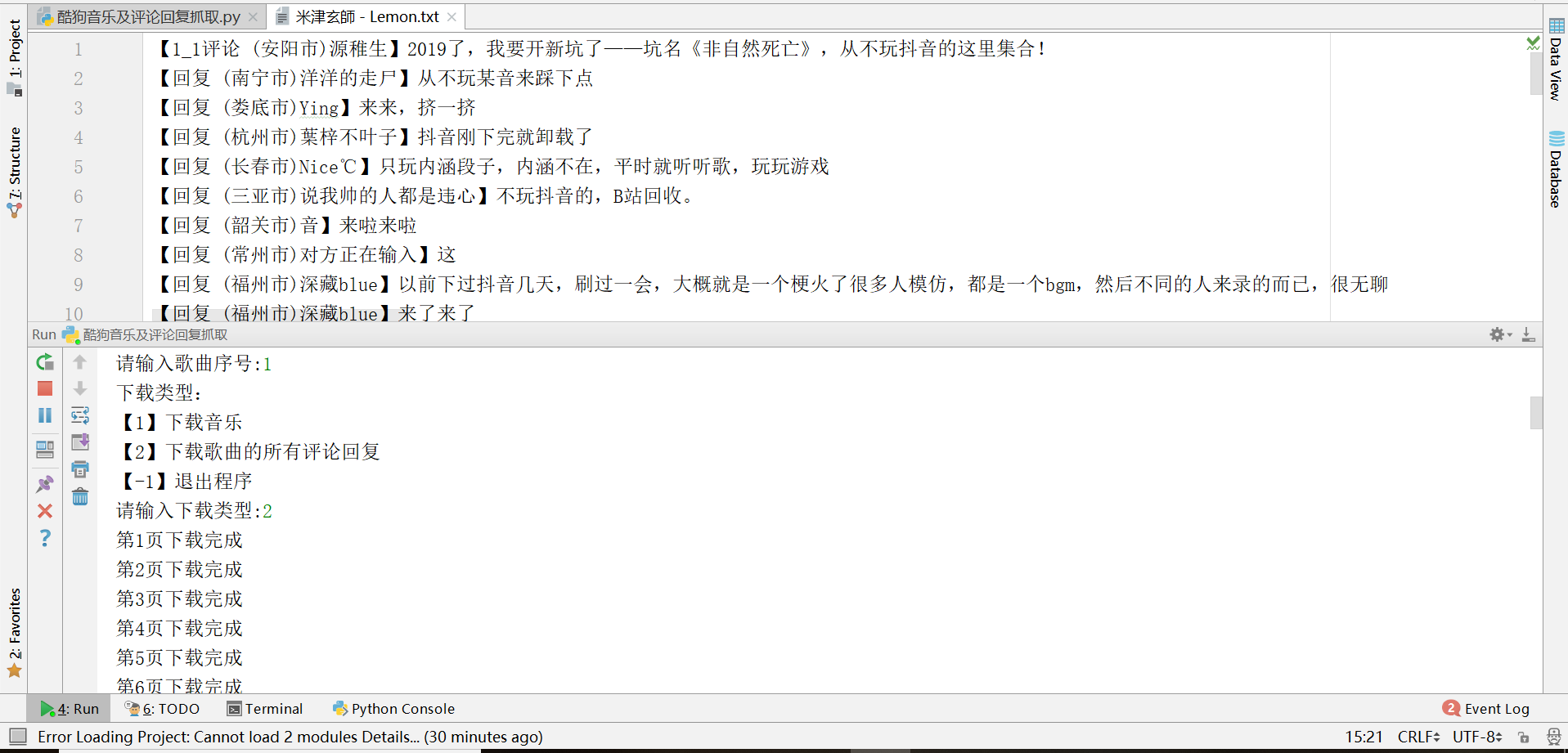
3.3、下载结果,评论回复较多,作为例子只下载了一部分
最后附上源码:
import requests import json # 写到文档 def write(path, text): with open(path, 'a', encoding='utf-8') as f: f.write(text+'\n') # 时间转换 def get_time(duration): second = duration % 60 minuter = int(duration / 60) hour = int(minuter / 60) minuter = int(minuter % 60) if hour > 0 else minuter time = [] for i in [hour, minuter, second]: i = str(i) if i >= 10 else '0'+str(i) time.append(i) return ':'.join(time) # 下载音乐 def down(filehash): hash_url = "http://www.kugou.com/yy/index.php?r=play/getdata&hash={0}".format(filehash) hash_content = requests.get(hash_url).text dt = json.loads(hash_content) audio_name = dt['data']['audio_name'] audio_url = dt['data']['play_url'] with open(audio_name + ".mp3", "wb")as fp: fp.write(requests.get(audio_url).content) print("音乐下载完成:{0}".format(audio_name + ".mp3")) # 下载所有回复 def get_reply(path, special_child_id, tid, pagesize=10, pageindex=1): url = ('http://comment.service.kugou.com/index.php?' 'r=commentsv2/getReplyWithLike' '&code=fc4be23b4e972707f36b8a828a93ba8a' '&p={0}' '&pagesize={1}' '&ver=1.01' '&clientver=8323' '&kugouid=998708111' '&clienttoken=8048d52b7884b9e9e606d0a06a6a5ec7b2ad556931dcedc14d9cd3247bf3ee4d' '&appid=1001' '&childrenid={2}' '&tid={3}'.format(pageindex, pagesize, special_child_id, tid)) response = requests.get(url) response = json.loads(response.text) if response.get('list'): for comment in response['list']: # 回复 content = comment.get('content') user_name = comment.get('user_name') extdata = comment.get('extdata').replace('null', '\'\'') city = eval(extdata).get('city') city = '(' + city + ')' if city else '' content = '【回复 {1}{0}】{2}'.format(user_name, city, content) write(path, content) if response.get('list'): # 列表有值,请求下一页 get_reply(path, special_child_id, tid, pagesize, pageindex + 1) # 下载所有评论、回复 def get_comment(path, filehash, pagesize=10, pageindex=1): url = ('http://comment.service.kugou.com/index.php?' '&r=commentsv2/getCommentWithLike' '&code=fc4be23b4e972707f36b8a828a93ba8a' '&extdata={0}' '&pagesize={1}' '&ver=1.01' '&clientver=8323' '&kugouid=998708111' '&clienttoken=8048d52b7884b9e9e606d0a06a6a5ec7b2ad556931dcedc14d9cd3247bf3ee4d' '&appid=1001' '&p={2}'.format(filehash, pagesize, pageindex) ) response = requests.get(url) response = json.loads(response.text) if response['message'] == 'success': for index, comment in enumerate(response['list'],1): # 评论 content = comment.get('content') user_name = comment.get('user_name') extdata = comment.get('extdata').replace('null','\'\'') city = eval(extdata).get('city') city = '('+ city +')' if city else '' content = '【{0}_{1}评论 {4}{3}】{2}'.format(pageindex, index, content, user_name, city) write(path, content) tid = comment.get('id') special_child_id = comment.get('special_child_id') get_reply(path, special_child_id, tid) #回复 print("第{0}页下载完成".format(pageindex)) if response.get('list'): # 列表有值,请求下一页 get_comment(path, filehash, pagesize, pageindex + 1) # 搜索歌曲 def search(keyword, pagesize=10): search_url = ( 'http://songsearch.kugou.com/song_search_v2?callback=jQuery112407470964083509348_1534929985284&keyword={0}&' 'page=1&pagesize={1}&userid=-1&clientver=&platform=WebFilter&tag=em&filter=2&iscorrection=1&privilege_filte' 'r=0'.format(keyword, pagesize)) response = requests.get(search_url).text js = json.loads(response[response.index('(') + 1:-2]) data = js['data']['lists'] songs = [['序号', '时长' + ' ' * 4, '歌曲名称']] print(' >>> '.join(songs[0])) for index, song in enumerate(data, 1): filename = song.get('FileName') filename = filename.replace('<em>', '').replace('</em>', '') if filename else '' filehash = song.get('FileHash') duration = song.get('Duration', 0) duration = get_time(duration) index = str(index) + (4 - len(str(index))) * ' ' item = [index, duration, filename, filehash] songs.append(item) print(' >>> '.join(item[:-1])) return songs if __name__ == '__main__': keyword = input("请输入搜索歌曲名称:") songs = search(keyword) while True: index = 0 while True: index = input("请输入歌曲序号:") if index.isdigit() and int(index) < len(songs): break else: print("请输入有效的歌曲序号, 再进行下载选择!") type = 0 while True: type = input("下载类型:\n【1】下载音乐\n【2】下载歌曲的所有评论回复\n【-1】退出程序\n请输入下载类型:") if type.isdigit() and type in ['1', '2', '-1']: break else: print("请输入有效的下载类型, 再进行下载选择!") song = songs[int(index)] filename = song[-2] filehash = song[-1] if type == '1': down(filehash) elif type == '2': get_comment(filename+'.txt', filehash) elif type == '-1': exit() next = input("请选择继续操作类型:\n【1】重新搜索\n【2】继续下载\n【-1】退出程序\n请输入:") if next == '1': keyword = input("请输入搜索歌曲名称:") songs = search(keyword) elif next == '2': continue elif next == '-1': exit()














 1821
1821











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









