






一.前言
伴随着深度学习的大红大紫,只要是在自己的成果里打上 deep learning 字样,总会有
人去看。 深度学习可以称为当今机器学习领域的当之无愧的巨星, 也特别得到工业界的青睐。
在各种大举深度学习大旗的公司中,Google 公司无疑是旗举得最高的,口号喊得最响
亮的那一个。Google 正好也是互联网界璀璨巨星,与深度学习的联姻,就像影视巨星刘德
华和林志玲的结合那么光彩夺目。
巨星联姻产生的成果自然是天生的宠儿。2013 年末,Google 发布的 word2vec 工具引起
了一帮人的热捧,互联网界大量 google 公司的粉丝们兴奋了,从而 google 公司的股票开始
大涨,如今直逼苹果公司。
在大量赞叹 word2vec 的微博或者短文中,几乎都认为它是深度学习在自然语言领域的
一项了不起的应用,各种欢呼“深度学习在自然语言领域开始发力了” 。
互联网界很多公司也开始跟进, 使用 word2vec 产出了不少成果。 身为一个互联网民工,
有必要对这种炙手可热的技术进行一定程度的理解。
好在 word2vec 也算是比较简单的,只是一个简单三层神经网络。在浏览了多位大牛的博客,随笔和笔记后,整理成自己的博文,或者说抄出来自己的博文。
二.背景知识
2.1 词向量
自然语言处理(NLP)相关任务中,要将自然语言交给机器学习中的算法来处理,通常需要首先将语言数学化,因为机器不是人,机器只认数学符号。向量是人把自然界的东西抽象出来交给机器处理的东西,基本上可以说向量是人对机器输入的主要方式了。 词向量就是用来将语言中的词进行数学化的一种方式, 顾名思义, 词向量就是把一个词表示成一个向量。
2.1.1 One-Hot Representation
一种最简单的词向量方式是 one-hot representation, 就是用一个很长的向量来表示一个
词,向量的长度为词典的大小,向量的分量只有一个 1,其他全为 0, 1 的位置对应该词在词典中的位置。举个例子,
“话筒”表示为 [0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 …]
“麦克”表示为 [0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 …]
每个词都是茫茫 0 海中的一个 1。这种 One-hot Representation 如果采用稀疏方式存储,会是非常的简洁:也就是给每个词分配一个数字 ID。比如刚才的例子中,话筒记为 3,麦克记为 8(假设从 0 开始记) 。
如果要编程实现的话, 用 Hash 表给每个词分配一个编号就可以了。 这么简洁的表示方法配合上最大熵、SVM、CRF 等等算法已经很好地完成了 NLP 领域的各种主流任务。 但这种词表示有两个缺点: (1) 容易受维数灾难的困扰, 尤其是将其用于 Deep Learning 的一些算法时; (2)不能很好地刻画词与词之间的相似性(术语好像叫做“词汇鸿沟”) :任意两个词之间都是孤立的。 光从这两个向量中看不出两个词是否有关系, 哪怕是话筒和麦克这样的同义词也不能幸免于难。 所以会寻求发展,用另外的方式表示,就是下面这种。
2.1.2 Distributed Representation
另一种就是 Distributed Representation 这种表示, 它最早是 Hinton 于 1986 年提出的,可以克服 one-hot representation 的缺点。 其基本想法是直接用一个普通的向量表示一个词,这种向量一般长成这个样子:[0.792, −0.177, −0.107, 0.109, −0.542, …],也就是普通的向量表示形式。维度以 50 维和 100 维比较常见。
当然一个词怎么表示成这么样的一个向量是要经过一番训练的,训练方法较多,
word2vec 是其中一种,在后面会提到,这里先说它的意义。还要注意的是每个词在不同的语料库和不同的训练方法下,得到的词向量可能是不一样的。
词向量一般维数不高, 很少有人闲着没事训练的时候定义一个 10000 维以上的维数, 所以用起来维数灾难的机会现对于 one-hot representation 表示就大大减少了。
一个比较爽的应用方法是,得到词向量后,假如对于某个词 A,想找出这个词最相似的词,这个场景对人来说都不轻松,毕竟比较主观,但是对于建立好词向量后的情况,对计算机来说,只要拿这个词的词向量跟其他词的词向量一一计算欧式距离或者 cos 距离,得到距离最小的那个词,就是它最相似的。
2.2 语言模型
2.2.1 基本概念
语言模型其实就是看一句话是不是正常人说出来的。这玩意很有用,比如机器翻译、语音识别得到若干候选之后,可以利用语言模型挑一个尽量靠谱的结果。在 NLP 的其它任务里也都能用到。
语言模型形式化的描述就是给定一个 T 个词的字符串 s,看它是自然语言的概率
P(w1,w2,…,wt)。w1 到 wT 依次表示这句话中的各个词。有个很简单的推论是:
p(t) = p(x1,x2,⋯xT) = p(x1)p(x2|x1)p(x3|x1,x2)⋯p(xu|x1,x2,⋯xT−1) (1)
上面那个概率表示的意义是: 第一个词确定后, 看后面的词在前面的词出现的情况下出现的概率。如一句话“大家喜欢吃苹果” ,总共四个词“大家” , “喜欢” , “吃” , “苹果” ,怎么分词现在不讨论,总之词已经分好,就这四个。那么这句话是一个自然语言的概率是:
P(大家,喜欢,吃,苹果)=p(大家)p(喜欢|大家)p(吃|大家,喜欢)p(苹果|大家,喜欢,吃)
p(大家)表示“大家”这个词在语料库里面出现的概率;
考虑词的数量, 成千上万个, 再考虑组合数, p(吃|大家,喜欢)这个有 “大家” 、 “喜欢” 和 “吃”的组合,总共会上亿种情况吧;再考虑 p(苹果|大家,喜欢,吃)这个概率,总共也会超过万亿种。
为了表示简单,上面的公式(1)用下面的方式表示
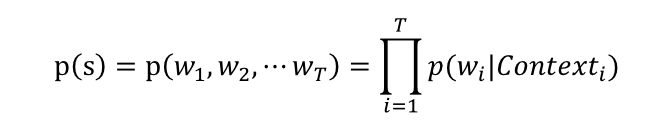
其中,如果 Contexti 是空的话,就是它自己 p(w),另外如“吃”的 Context 就是“大家” 、“喜欢” ,其余的对号入座。
符号搞清楚了,就看怎么偷懒了。
2.2.2 N-gram 模型
接下来说怎么计算q(xj|contextj),上面看的是跟据这句话前面的所有词来计算,那么q(xj|contextj)就得计算很多了, 比如就得把语料库里面 p(苹果|大家,喜欢,吃)这种情况全部统计一遍,那么为了计算这句话的概率,就上面那个例子,都得扫描四次语料库。这样一句话有多少个词就得扫描多少趟,语料库一般都比较大,越大的语料库越能提供准确的判断。这样的计算速度在真正使用的时候是万万不可接受的, 线上扫描一篇文章是不是一推乱七八糟的没有序列的文字都得扫描很久,这样的应用根本没人考虑。
最好的办法就是直接把所有的q(xj|contextj)提前算好了,那么根据排列组上面的来算,对于一个只有四个词的语料库,总共就有 4!+3!+2!+1!个情况要计算,那就是 24 个情况要计算;换成 1000 个词的语料库,就是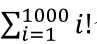
这就诞生了很多偷懒的方法,N-gram 模型是其中之一了。N-gram 什么情况呢?上面的context 都是这句话中这个词前面的所有词作为条件的概率,N-gram 就是只管这个词前面的n-1 个词,加上它自己,总共 n 个词,计算q(xj|contextj)只考虑用这 n 个词来算,换成数学的公式来表示,就是 p(xj|contextj)=p(xj|xj−n+1,xj−n+2,⋯,xj−1)
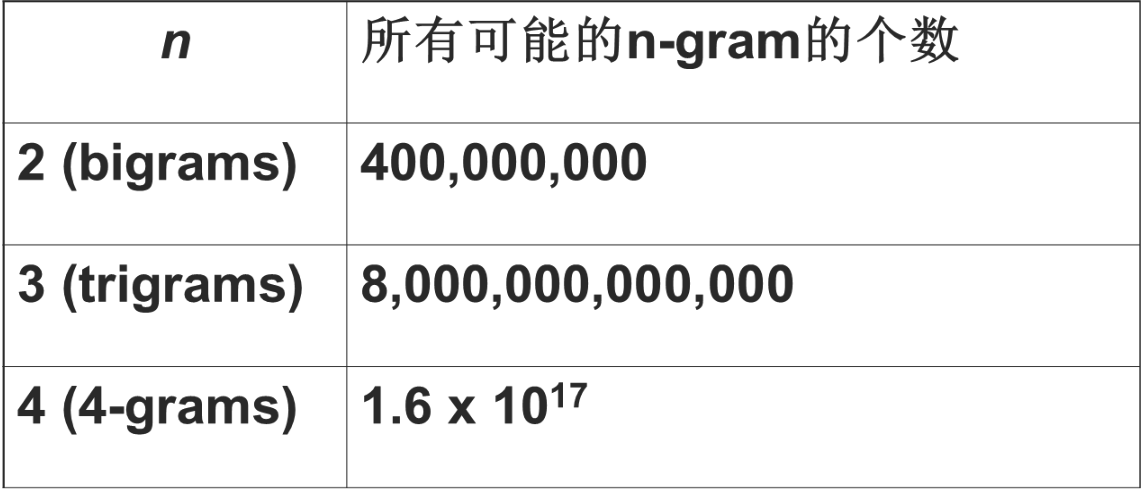
照图中的数据看去, 取 n=3 是目前计算能力的上限了。 在实践中用的最多的就是 bigram和 trigram 了,而且效果也基本够了。
N-gram 模型也会有写问题,总结如下:
1、n 不能取太大,取大了语料库经常不足,所以基本是用降级的方法
2、无法建模出词之间的相似度,就是有两个词经常出现在同一个 context
后面,但是模型是没法体现这个相似性的。
3、有些 n 元组(n 个词的组合,跟顺序有关的)在语料库里面没有出现过,
对应出来的条件概率就是 0, 这样一整句话的概率都是 0 了, 这是不对的,
解决的方法主要是两种:平滑法(基本上是分子分母都加一个数)和回退法(利用 n-1 的元组的概率去代替 n 元组的概率)
2.2.3N-pos 模型
当然学术是无止境的,有些大牛觉得这还不行,因为第 i 个词很多情况下是条件依赖于它前面的词的语法功能的,所以又弄出来一个 n-pos 模型,n-pos 模型也是用来计算q(xj|contxtj)的,但是有所改变,先对词按照词性(Part-of-Speech,POS)进行了分类,具体的数学表达是
p(xj|contextj) = p(xj|c(xj - n + 1),c(xj - n + 2),⋯,c(xj - 1))
2.2.4 模型的问题与目标
如果是原始的直接统计语料库的语言模型, 那是没有参数的, 所有的概率直接统计就得到了。 但现实往往会带一些参数, 所有语言模型也能使用极大似然作为目标函数来建立模型。
下面就讨论这个。
假设语料库是一个由 T 个词组成的词序列 s(这里可以保留疑问的,因为从很多资料看来是不管什么多少篇文档,也不管句子什么的,整个语料库就是一长串词连起来的,或许可以根据情况拆成句子什么的,这里就往简单里说) ,其中有 V 个词,则可以构建下面的极大似然函数
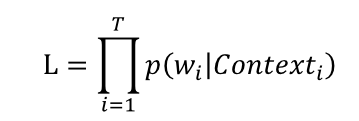
另外,做一下对数似然
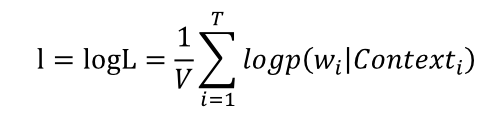
上面的问题跟正常的情况不太符合, 来看看下一种表达。 假设语料库是有 S 个句子组成的一个句子序列(顺序不重要) ,同样是有 V 个词,似然函数就会构建成下面的样子
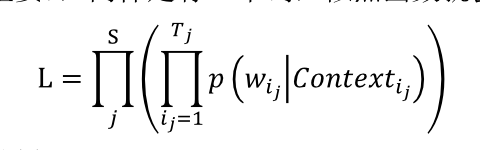
对数似然就会是下面的样子
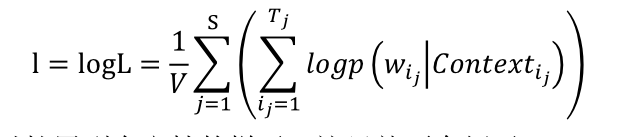
为啥要注意这个问题呢?原因有多种,计算q(xj|contextj)这个东西的参数是主要的原因。
为啥会有参数呢?在计算q(xj|contextj)这个东西的过程中,有非常多的方法被开发出来了,如上面的平滑法,回退法上面的,但这些都是硬统计一下基本就完了;这就带来一些需要求的参数,如平滑法中使用的分子分母分别加上的常数是什么?
这还不够, 假如用的是 trigram, 还得存储一个巨大的元组与概率的映射 (如果不存储,就得再进行使用的时候实际统计,那太慢了) ,存这个东西可需要很大的内存,对计算机是个大难题。
这都难不倒大牛们, 他们考虑的工作是利用函数来拟合计算q(xj|contextj), 换句话说,q(xj|contextj)不是根据语料库统计出来的,而是直接把 context 和 wi 代到一个函数里面计算出来的, 这样在使用的时候就不用去查那个巨大的映射集了 (或者取语料库里面统计这个概率) 。用数学的方法描述就是
q(xj|contextj) = f(xj,contextj;θ)
这样的工作也体现了科学家们的价值——这帮人终于有点东西可以忙了。
那么探索这个函数的具体形式就是主要的工作了,也是后面 word2vec 的工作的主要内容。函数的形式实在太多了,线性的还好,非线性真叫一个多,高维非线性的就更多了。 探索一个函数的具体形式的术语叫做拟合。 然后就有人提出了用神经网络来拟合这个函数,就有了各种方法,word2vec 是其中的一种。














 3861
3861











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









