







趁着暑假的空闲,把在上个学期学到的Python数据采集的皮毛用来试试手,写了一个爬取豆瓣图书的爬虫,总结如下:
下面是我要做的事:
1. 登录
2. 获取豆瓣图书分类目录
3. 进入每一个分类里面,爬取第一页的书的书名,作者,译者,出版时间等信息,放入MySQL中,然后将封面下载下来。
第一步
首先,盗亦有道嘛,看看豆瓣网的robots协议:
User-agent: *
Disallow: /subject_search
Disallow: /amazon_search
Disallow: /search
Disallow: /group/search
Disallow: /event/search
Disallow: /celebrities/search
Disallow: /location/drama/search
Disallow: /forum/
Disallow: /new_subject
Disallow: /service/iframe
Disallow: /j/
Disallow: /link2/
Disallow: /recommend/
Disallow: /trailer/
Disallow: /doubanapp/card
Sitemap: https://www.douban.com/sitemap_index.xml
Sitemap: https://www.douban.com/sitemap_updated_index.xml
# Crawl-delay: 5
User-agent: Wandoujia Spider
Disallow: /再看看我要爬取的网站:
https://book.douban.com/tag/?view=type&icn=index-sorttags-all
https://book.douban.com/tag/?icn=index-nav
https://book.douban.com/tag/[此处是标签名]
https://book.douban.com/subject/[书的编号]/好了,并没有违反robots协议,安心的写代码了。
第二步
既然写了,就做得完整一些,现在先登录一下豆瓣:
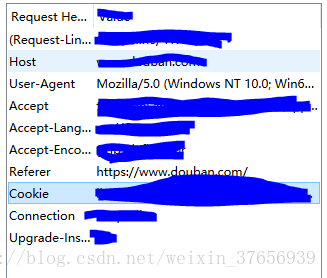
我在这里采用的是cookies登录的方式,首先用firefox神奇的插件HttpFox获得一下正常登录的headers和cookies、
找到这条记录
查看内容
这样就获得了cookies和headers,把他们复制下来,直接复制到程序里或者用文件存储,用你喜欢的方式保存下来。
login函数

def login(url):
cookies = {}
with open("C:/Users/lenovo/OneDrive/projects/Scraping/doubancookies.txt") as file:
raw_cookies = file.read();
for line in raw_cookies.split(';'):
key,value = line.split('=',1)
cookies[key] = value
headers = {'User-Agent':'''Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.78 Safari/537.36'''}
s = requests.get(url, cookies=cookies, headers=headers)
return s 我在这里采用的是将headers复制到程序里,将cookies放入文件中读取的方式,同时注意要将cookies处理成字典的形式,然后用requests库的get函数获得网页响应。
第三步
先进入豆瓣读书的分类目录
https://book.douban.com/tag/?view=type&icn=index-sorttags-all
我们把这个网站上的分类链接爬取下来:
import requests
from bs4 import BeautifulSoup
#from login import login #导入上述login函数
url = "https://book.douban.com/tag/?icn=index-nav"
web = requests.get(url) #请求网址
soup = BeautifulSoup(web.text,"lxml") #解析网页信息
tags = soup.select("#content > div > div.article > div > div > table > tbody > tr > td > a")
urls = [] #储存所有链接
for tag in tags:
tag=tag.get_text() #将列表中的每一个标签信息提取出来
helf="https://book.douban.com/tag/"
#观察一下豆瓣的网址,基本都是这部分加上标签信息,所以我们要组装网址,用于爬取标签详情页
url=helf+str(tag)
urls.append(url)
# 将链接存入文件
with open("channel.txt","w") as file:
for link in urls:
file.write(link+'\n')
上面代码当中用了CSS选择器,不懂CSS没关系,将相应的网站页面用浏览器打开,打开开发者工具,在elements界面右键要爬取的内容,copy->selector
(我用的是chrome浏览器,在正常的图形网页里右键检查就能直接定位到对应的elements位置),将CSS选择器复制下来,注意如果出现了:nth-child(*)之类的都要去掉,不然会报错。
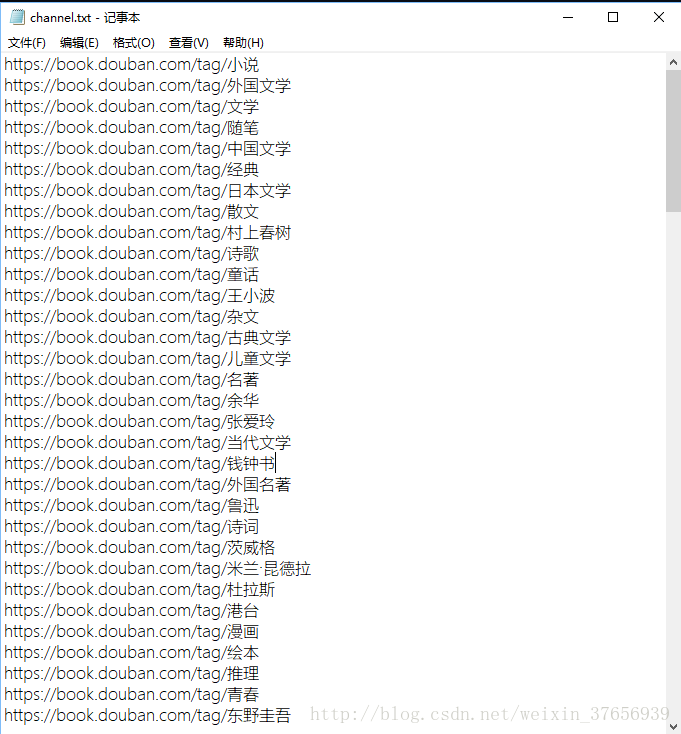
然后我们得到了链接的目录:
第四步
下面先找一找爬取的方法
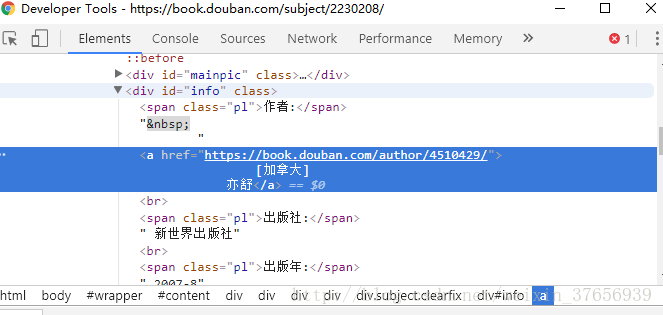
根据上面说的CSS选择器的方法,可以得到书名,作者,译者,评价人数,评分,还有这本书的封面链接和简介。
title = bookSoup.select('#wrapper > h1 > span')[0].contents[0]
title = deal_title(title)
author = get_author(bookSoup.select("#info > a")[0].contents[0])
translator = bookSoup.select("#info > span > a")[0].contents[0]
person = bookSoup.select("#interest_sectl > div > div.rating_self.clearfix > div > div.rating_sum > span > a > span")[0].contents[0]
scor = bookSoup.select("#interest_sectl > div > div.rating_self.clearfix > strong")[0].contents[0]
coverUrl = bookSoup.select("#mainpic > a > img")[0].attrs['src'];
brief = get_brief(bookSoup.select('#link-report > div > div > p'))有几点要注意:
- 文件名不能含有
:?<>"|\/*所以用正则表达式处理一下:
def deal_title(raw_title):
r = re.compile('[/\*?"<>|:]')
return r.sub('~',raw_title)然后将封面下载下来:
path = "C:/Users/lenovo/OneDrive/projects/Scraping/covers/"+title+".png"
urlretrieve(coverUrl,path);- 作者名字爬取下来格式要处理过,否者会很难看
def get_author(raw_author):
parts = raw_author.split('\n')
return ''.join(map(str.strip,parts))- 图书简介也要处理一下
def get_brief(line_tags):
brief = line_tags[0].contents
for tag in line_tags[1:]:
brief += tag.contents
brief = '\n'.join(brief)
return brief而对于出版社,出版时间,ISBN和图书定价,则可以用下面更简洁的方法获得:
info = bookSoup.select('#info')
infos = list(info[0].strings)
publish = infos[infos.index('出版社:') + 1]
ISBN = infos[infos.index('ISBN:') + 1]
Ptime = infos[infos.index('出版年:') + 1]
price = infos[infos.index('定价:') + 1]第五步
先创建数据库和数据表
CREATE TABLE `allbooks` (
`title` char(255) NOT NULL,
`scor` char(255) DEFAULT NULL,
`author` char(255) DEFAULT NULL,
`price` char(255) DEFAULT NULL,
`time` char(255) DEFAULT NULL,
`publish` char(255) DEFAULT NULL,
`person` char(255) DEFAULT NULL,
`yizhe` char(255) DEFAULT NULL,
`tag` char(255) DEFAULT NULL,
`brief` mediumtext,
`ISBN` char(255) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;然后用executemany方法便捷地将数据存入。
connection = pymysql.connect(host='你的主机',user='你的账号',password='你的密码',charset='utf8')
with connection.cursor() as cursor:
sql = "USE DOUBAN_DB;"
cursor.execute(sql)
sql = '''INSERT INTO allbooks (
title, scor, author, price, time, publish, person, yizhe, tag, brief, ISBN)VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)'''
cursor.executemany(sql, data)
connection.commit()第六步
到此,我们已经找到了全部的方法,就剩写出完整程序了
还要注意的一点就是要设置随机访问间隔,以防封IP。
代码如下,也在github更新,欢迎star,我的github链接。
# -*- coding: utf-8 -*-
"""
Created on Sat Aug 12 13:29:17 2017
@author: Throne
"""
#每一本书的 1cover 2author 3yizhe(not must) 4time 5publish 6price 7scor 8person 9title 10brief 11tag 12ISBN
import requests #用来请求网页
from bs4 import BeautifulSoup #解析网页
import time #设置延时时间,防止爬取过于频繁被封IP号
import pymysql #由于爬取的数据太多,我们要把他存入MySQL数据库中,这个库用于连接数据库
import random #这个库里用到了产生随机数的randint函数,和上面的time搭配,使爬取间隔时间随机
from urllib.request import urlretrieve #下载图片
import re #处理诡异的书名
connection = pymysql.connect(host='localhost',user='root',password='',charset='utf8')
with connection.cursor() as cursor:
sql = "USE DOUBAN_DB;"
cursor.execute(sql)
connection.commit()
def deal_title(raw_title):
r = re.compile('[/\*?"<>|:]')
return r.sub('~',raw_title)
def get_brief(line_tags):
brief = line_tags[0].contents
for tag in line_tags[1:]:
brief += tag.contents
brief = '\n'.join(brief)
return brief
def get_author(raw_author):
parts = raw_author.split('\n')
return ''.join(map(str.strip,parts))
def login(url):
cookies = {}
with open("C:/Users/lenovo/OneDrive/projects/Scraping/doubancookies.txt") as file:
raw_cookies = file.read();
for line in raw_cookies.split(';'):
key,value = line.split('=',1)
cookies[key] = value
headers = {'User-Agent':'''Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.78 Safari/537.36'''}
s = requests.get(url, cookies=cookies, headers=headers)
return s
def crawl():
# 获取链接
channel = []
with open('C:/Users/lenovo/OneDrive/projects/Scraping/channel.txt') as file:
channel = file.readlines()
for url in channel:
data = [] #存放每一本书的数据
web_data = login(url.strip())
soup = BeautifulSoup(web_data.text.encode('utf-8'),'lxml')
tag = url.split("?")[0].split("/")[-1]
books = soup.select(
'''#subject_list > ul > li > div.info > h2 > a''')
for book in books:
bookurl = book.attrs['href']
book_data = login(bookurl)
bookSoup = BeautifulSoup(book_data.text.encode('utf-8'),'lxml')
info = bookSoup.select('#info')
infos = list(info[0].strings)
try:
title = bookSoup.select('#wrapper > h1 > span')[0].contents[0]
title = deal_title(title)
publish = infos[infos.index('出版社:') + 1]
translator = bookSoup.select("#info > span > a")[0].contents[0]
author = get_author(bookSoup.select("#info > a")[0].contents[0])
ISBN = infos[infos.index('ISBN:') + 1]
Ptime = infos[infos.index('出版年:') + 1]
price = infos[infos.index('定价:') + 1]
person = bookSoup.select("#interest_sectl > div > div.rating_self.clearfix > div > div.rating_sum > span > a > span")[0].contents[0]
scor = bookSoup.select("#interest_sectl > div > div.rating_self.clearfix > strong")[0].contents[0]
coverUrl = bookSoup.select("#mainpic > a > img")[0].attrs['src'];
brief = get_brief(bookSoup.select('#link-report > div > div > p'))
except :
try:
title = bookSoup.select('#wrapper > h1 > span')[0].contents[0]
title = deal_title(title)
publish = infos[infos.index('出版社:') + 1]
translator = ""
author = get_author(bookSoup.select("#info > a")[0].contents[0])
ISBN = infos[infos.index('ISBN:') + 1]
Ptime = infos[infos.index('出版年:') + 1]
price = infos[infos.index('定价:') + 1]
person = bookSoup.select("#interest_sectl > div > div.rating_self.clearfix > div > div.rating_sum > span > a > span")[0].contents[0]
scor = bookSoup.select("#interest_sectl > div > div.rating_self.clearfix > strong")[0].contents[0]
coverUrl = bookSoup.select("#mainpic > a > img")[0].attrs['src'];
brief = get_brief(bookSoup.select('#link-report > div > div > p'))
except:
continue
finally:
path = "C:/Users/lenovo/OneDrive/projects/Scraping/covers/"+title+".png"
urlretrieve(coverUrl,path);
data.append([title,scor,author,price,Ptime,publish,person,translator,tag,brief,ISBN])
with connection.cursor() as cursor:
sql = '''INSERT INTO allbooks (
title, scor, author, price, time, publish, person, yizhe, tag, brief, ISBN)
VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)'''
cursor.executemany(sql, data)
connection.commit()
del data
time.sleep(random.randint(0,9)) #防止IP被封
start = time.clock()
crawl()
end = time.clock()
with connection.cursor() as cursor:
print("Time Usage:", end -start)
count = cursor.execute('SELECT * FROM allbooks')
print("Total of books:", count)
if connection.open:
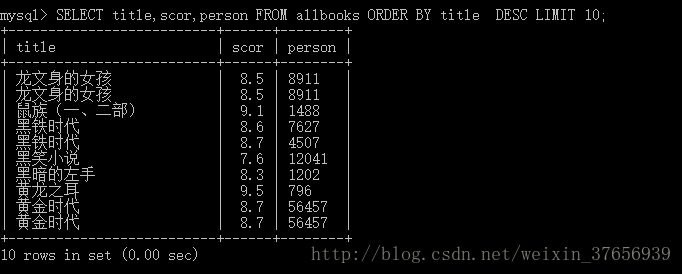
connection.close()结果展示
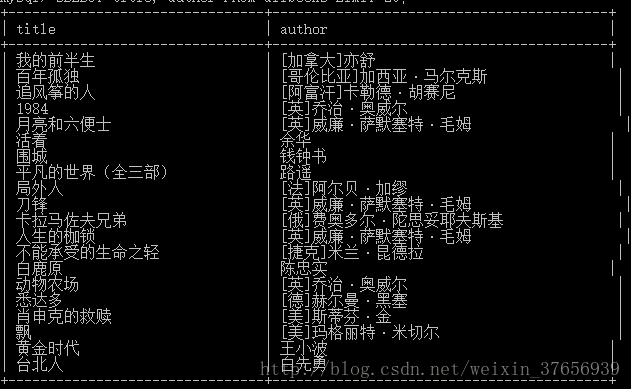
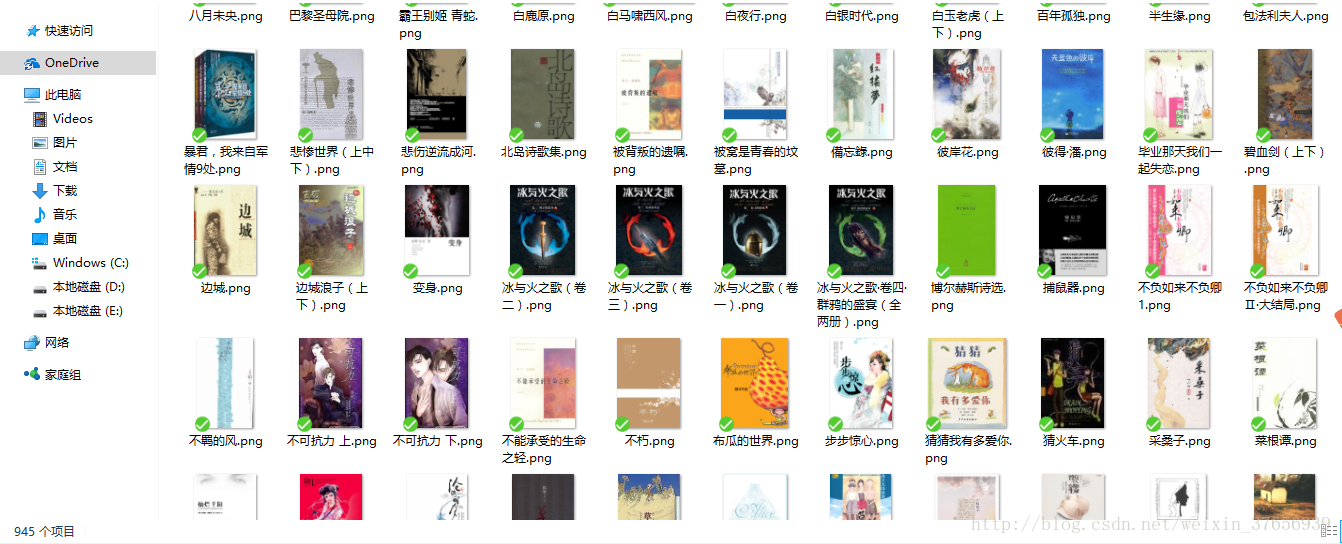
文章原创,要转载请联系作者














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









