







1、安装pymysql库
- 如果你想要使用python操作MySQL数据库,就必须先要安装pymysql库,这个库的安装很简单,直接使用pip install pymysql;进行安装。
- 假如上面这种方式还是安装不上,就用如下链接找一个合适的安装包进行安装,这个就不细说了,请自行百度。
- https://www.lfd.uci.edu/~gohlke/pythonlibs/
- 学习本篇文章,最好是先看我另外一篇关于游标cursor讲解的文章,这样会有更好的效果:https://blog.csdn.net/weixin_41261833/article/details/103827819
2、使用python连接mysql数据库
1)六个常用的连接参数
参数host:mysql服务器所在的主机的ip;
参数user:用户名
参数password:密码
参数port:连接的mysql主机的端口,默认是3306
参数db:连接的数据库名
参数charset:当读取数据出现中文会乱码的时候,需要我们设置一下编码;我们使用python操作数据库的时候,那么python就相当于是client,
我们是用这个client来操作mysql的server服务器,python3默认采用的utf8字符集,我的mysql服务器默认采用latin1字符集,
因此mysql中创建的每张表,都是建表的时候加了utf8编码的,因此这里设置的应该就是connection连接器的编码。
什么是connection?可以参考我的另外一篇文章学习。
https://blog.csdn.net/weixin_41261833/article/details/103488680
2)python连接mysql的语法
import pymysql
db = pymysql.connect(host='localhost',user='root',password='123456',port=3306,db='spiders',charset=' utf8')
- 最基本的参数是host,user,password和port,必须要有。剩下两个参数根据你自己的情况决定是否使用。
- host指的是mysql服务器安装在哪里,由于我的mysql就是安装在本机上,因此这里可以写localhost,我也可以写成主机名或者主机ip。
- db指的是你要操作的是哪一个数据库,在进行数据库连接的时候,最好加上这个参数。
3)一个简单的热身案例
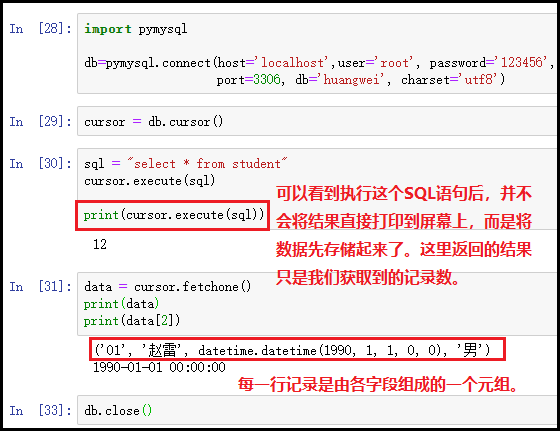
# 导包
import pymysql
# 使用pymysql连接上mysql数据库服务器,创建了一个数据库对象;
db = pymysql.connect(host='localhost',user='root', password='123456',
port=3306, db='huangwei', charset='utf8')
# 开启mysql的游标功能,创建一个游标对象;
cursor = db.cursor()
# 要执行的SQL语句;
sql = "select * from student"
# 使用游标对象执行SQL语句;
cursor.execute(sql)
# 使用fetchone()方法,获取返回的结果,但是需要用变量保存返回结果;
data = cursor.fetchone()
print(data)
# 断开数据库的连接,释放资源;
db.close()
结果如下:
3、cursor游标对象的一些常用方法
1)cursor用来执行命令的方法
- execute(query, args):执行单条sql语句,接收的参数为sql语句本身和使用的参数列表,返回值为受影响的行数;
- executemany(query, args):执行单挑sql语句,但是重复执行参数列表里的参数,返回值为受影响的行数;
2)cursor用来接收返回值的方法
- fetchone():返回一条结果行;
- fetchmany(size):接收size条返回结果行。如果size的值大于返回的结果行的数量,则会返回cursor.arraysize条数据;
- fetchall():接收全部的返回结果行;
4、创建表
import pymysql
db = pymysql.connect(host='localhost',user='root', password='123456',port=3306, db='huangwei', charset='utf8')
# 创建一个游标对象;
cursor = db.cursor()
# 建表语句;
sql = """
create table person(
id int auto_increment primary key not null,
name varchar(10) not null,
age int not null
)charset=utf8
"""
# 执行sql语句;
cursor.execute(sql)
# 断开数据库的连接;
db.close()
注意:你在mysql中sql语句怎么写,在这里就怎么写。还有一个细节需要注意的是,在python中,将代码进行多次换行的时候,最好使用“三引号”。
5、查询数据…查
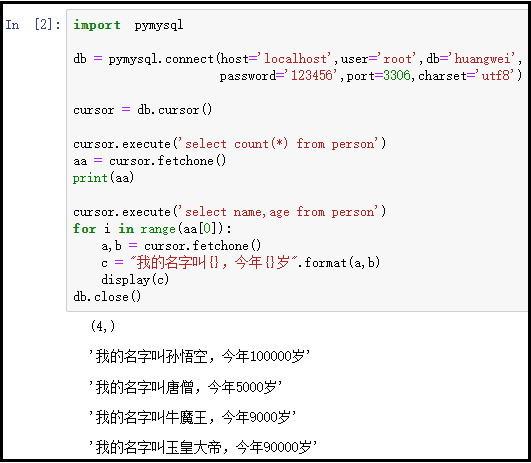
1)fetchone():一次获取一条记录
import pymysql
db = pymysql.connect(host='localhost',user='root',db='huangwei',password='123456',port=3306,charset='utf8')
cursor = db.cursor()
cursor.execute('select count(*) from person')
aa = cursor.fetchone()
print(aa)
cursor.execute('select name,age from person')
for i in range(aa[0]):
a,b = cursor.fetchone()
c = "我的名字叫{},今年{}岁".format(a,b)
display(c)
db.close()
结果如下:
2)fetchall():一次获取所有记录
import pymysql
db = pymysql.connect(host='localhost',user='root',db='huangwei',password='123456',port=3306,charset='utf8')
cursor = db.cursor()
cursor.execute('select name,age from person')
aa = cursor.fetchall()
# print(aa)
for a,b in aa:
c = "我的名字叫{},今年{}岁".format(a,b)
display(c)
db.close()
结果如下:
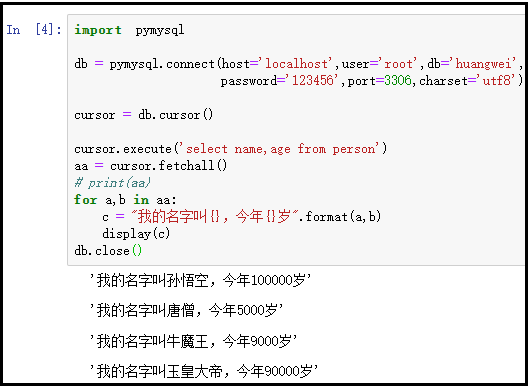
注:还有一个fetchmany()方法,用于一次性获取指定条数的记录,请自行下去研究。
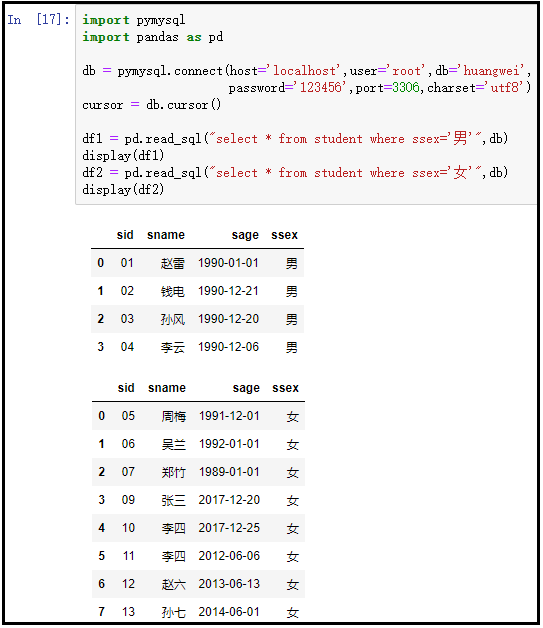
3)使用pandas中的read_sql()方法,将提取到的数据直接转化为DataFrame进行操作
import pymysql
import pandas as pd
db = pymysql.connect(host='localhost',user='root',db='huangwei',password='123456',port=3306,charset='utf8')
cursor = db.cursor()
df1 = pd.read_sql("select * from student where ssex='男'",db)
display(df1)
df2 = pd.read_sql("select * from student where ssex='女'",db)
display(df2)
结果如下:
6、插入数据…增
1)一次性插入一条数据
import pymysql
db = pymysql.connect(host='localhost',user='root', password='123456',port=3306, db='huangwei', charset='utf8')
cursor = db.cursor()
# mysql中SQL语句怎么写,这里就怎么写;
name = "猪八戒"
age = 8000
sql = 'insert into person(name,age) values ("猪八戒",8000)'
try:
cursor.execute(sql)
db.commit()
print("插入成功")
except:
print("插入失败")
db.rollback()
db.close()
1.1)一次性插入一条数据
import pymysql
db = pymysql.connect(host='localhost',user='root', password='123456',port=3306, db='huangwei', charset='utf8')
cursor = db.cursor()
# 插入数据
sql = 'insert into person(name,age) values(%s,%s)'
try:
cursor.execute(sql,('孙悟空',100000))
db.commit()
print("插入成功")
except:
print("插入失败")
db.rollback()
db.close()
2)一次性插入多条数据
import pymysql
db = pymysql.connect(host='localhost',user='root', password='123456',port=3306, db='huangwei', charset='utf8')
cursor = db.cursor()
# 插入数据
sql = 'insert into person(name,age) values(%s,%s)'
# 注意:(('牛魔王',9000),('铁扇公主',8000),('玉皇大帝',6000))也可以,小括号都可以换为中括号
datas = [('牛魔王',9000),('铁扇公主',8000),('玉皇大帝',6000)]
try:
cursor.executemany(sql,datas)
db.commit()
print("插入成功")
except:
print("插入失败")
db.rollback()
db.close()
总结如下:
① pymysql模块是默认开启mysql的事务功能的,因此,进行 “增” “删” "改"的时候,一定要使用db.commit()提交事务,否则就看不见所插入的数据。
② 进行 “增”、“删”、"改"的时候,一定要使用try…except…语句,因为万一没插入成功,其余代码都无法执行。当语句执行不成功,我们就db.rollback()回滚到操作之前的状态;当语句执行成功,我们就db.commit()提交事务。
7、更新数据…改
import pymysql
db = pymysql.connect(host='localhost',user='root', password='123456',port=3306, db='huangwei', charset='utf8')
cursor = db.cursor()
# 更新数据
sql = 'update person set age=%s where name=%s'
try:
cursor.execute(sql,[90000,"玉皇大帝"])
db.commit()
print("更新成功")
except:
print("更新失败")
db.rollback()
db.close()
8、删除数据…删
import pymysql
db = pymysql.connect(host='localhost',user='root', password='123456',port=3306, db='huangwei', charset='utf8')
cursor = db.cursor()
# 删除数据
sql = 'delete from person where age=8000'
try:
cursor.execute(sql)
db.commit()
print("删除成功")
except:
print("删除失败")
db.rollback()
db.close()















 395
395











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











