









历时一个多月,我们终于结束了【企业级360°全方位用户画像】的项目,想看具体详情的朋友,可以移步至博主的大数据项目专栏一饱眼福…
言归正传,在完成了两个大数据项目之后,接下来的几天,我们将要开始学习一项非常牛X的大数据组件——Flink。相信大数据圈的朋友肯定也早已知晓它的"威力",不清楚的朋友们也不要着急。本篇博客,菌哥为大家先介绍Flink的简介与架构体系。
码字不易,先赞后看!

文章目录
一、Flink 的简介
1.1 Flink的引入
这几年大数据的飞速发展,出现了很多热门的开源社区,其中著名的有 Hadoop、Storm, 以及后来的 Spark,他们都有着各自专注的应用场景。Spark 掀开了内存计算的先河,也以内存为赌注,赢得了内存计算的飞速发展。 Spark 的火热或多或少的掩盖了其他分布式计算的系统身影。就像 Flink,也就在这个时候默默的发展着。
在国外一些社区,有很多人将大数据的计算引擎分成了 4 代,当然,也有很多人不会认同。我们先姑且这么认为和讨论。
首先第一代的计算引擎,无疑就是 Hadoop 承载的 MapReduce。这里大家应该都不会对 MapReduce 陌生,它将计算分为两个阶段,分别为 Map 和 Reduce。对于上层应用来说,就 不得不想方设法去拆分算法,甚至于不得不在上层应用实现多个 Job 的串联,以完成一个 完整的算法,例如迭代计算。
由于这样的弊端,催生了支持 DAG 框架的产生。因此,支持 DAG 的框架被划分为第二 代计算引擎。如 Tez 以及更上层的 Oozie。这里我们不去细究各种 DAG 实现之间的区别, 不过对于当时的 Tez 和 Oozie 来说,大多还是批处理的任务。
接下来就是以 Spark 为代表的第三代的计算引擎。第三代计算引擎的特点主要是 Job 内部的 DAG 支持(不跨越 Job),以及强调的实时计算。在这里,很多人也会认为第三代计 算引擎也能够很好的运行批处理的 Job。随着第三代计算引擎的出现,促进了上层应用快速发展,例如各种迭代计算的性能以及对流计算和 SQL 等的支持。
接下来就是以 Spark 为代表的第三代的计算引擎。第三代计算引擎的特点主要是 Job 内部的 DAG 支持(不跨越 Job),以及强调的实时计算。在这里,很多人也会认为第三代计算引擎也能够很好的运行批处理的 Job。随着第三代计算引擎的出现,促进了上层应用快速发展,例如各种迭代计算的性能以及对流计算和 SQL 等的支持。
Flink 的诞生就被归在了第四代。这应该主要表现在 Flink 对流计算的支持,以及更一步的实时性上面。当然 Flink 也可以支持 Batch 的任务,以及 DAG 的运算。首先,我们可以通过下面的性能测试初步了解两个框架的性能区别,它们都可以基于内存计算框架进行实时计算,所以都拥有非常好的计算性能。经过测试,Flink 计算性能上略好。 特点:批处理、流处理、SQL 高层 API 支持,自带 DAG,流式计算性能更高、可靠性更高。
测试环境:
1.CPU:7000 个;
2.内存:单机 128GB;
3.版本:Hadoop 2.3.0,Spark 1.4,Flink 0.9
4.数据:800MB,8GB,8TB;
5.算法:K-means:以空间中 K 个点为中心进行聚类,对最靠近它们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。
6.迭代:K=10,3 组数据
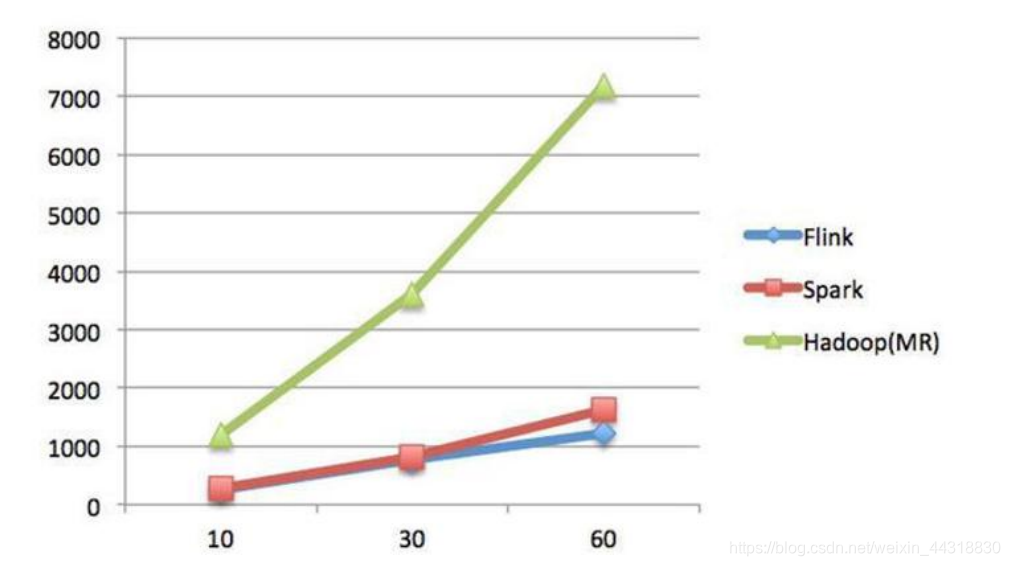
Spark 和 Flink 全部都运行在 Hadoop YARN 上,性能为 Flink > Spark > Hadoop(MR) , 迭代次数越多越明显,性能上,Flink 优于 Spark 和 Hadoop 最主要的原因是 Flink 支持增量迭代,具有对迭代自动优化的功能。
Flink 和 Spark 的差异见下表
| SparkStreaming | Flink | |
|---|---|---|
| 定义 | 弹性的分布式数据集,并非 真正的实时计算 | 真正的流计算,就像 storm 一样;但 flink 同时支持有 限的数据流计算( 批处理) 和无限数据流计算( 流处 理) |
| 高容错 | 沉重 | 非常轻量级 |
| 内存管理 | JVM 相关操作暴露给用户 | Flink 在 JVM 中实现的是 自己的内存管理 |
| 程序调优 | 只有 SQL 有自动优化机制 | 自动地优化一些场景,比如 避免一些昂贵的操作 ( 如 shuffle 和sorts),还有一些中间缓存 |
1.2 什么是 Flink
Flink 起源于 Stratosphere 项目,Stratosphere 是在 2010~2014 年由 3 所地处柏林的大学和欧洲的一些其他的大学共同进行的研究项目, 2014 年 4 月 Stratosphere 的 代码 被复制并捐赠 给了 Apache 软件 基金会 , 参加 这个孵 化项目 的初始成 员是 Stratosphere 系统的核心开发人员,2014 年 12 月, Flink 一跃成为 Apache 软件基金 会的顶级项目。在德语中, Flink 一词表示快速和灵巧, 项目采用一只松鼠的彩色图案作 为 logo, 这不仅是因为松鼠具有快速和灵巧的特点, 还因为柏林的松鼠有一种迷人的红 棕色, 而 Flink 的松鼠 logo 拥有可爱的尾巴, 尾巴的颜色与 Apache 软件基金会的 logo 颜色相呼应, 也就是说,这是一只 Apache 风格的松鼠。

Flink 主页在其顶部展示了该项目的理念:“Apache Flink 是为分布式、高性能、随时可用以及准确的流处理应用程序打造的开源流处理框架” 。 Apache Flink 是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。 Flink 被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算。
1.3 Flink 流处理特性
-
支持高吞吐、 低延迟、 高性能的流处理
-
支持带有事件时间的窗口(Window) 操作
-
支持有状态计算的 Exactly-once 语义
-
支持高度灵活的窗口(Window) 操作, 支持基于 time、 count、 session,以及 data-driven 的窗口操作
-
支持具有 Backpressure 功能的持续流模型
-
支持基于轻量级分布式快照(Snapshot) 实现的容错
-
一个运行时同时支持 Batch on Streaming 处理和 Streaming 处理
-
Flink 在 JVM 内部实现了自己的内存管理
-
支持迭代计算
-
支持程序自动优化: 避免特定情况下 Shuffle、 排序等昂贵操作, 中间结果有必要进行缓存
1.4 Flink 基石
Flink 之所以能这么流行,离不开它最重要的四个基石:Checkpoint、State、Time、 Window。
首 先 是 Checkpoint 机 制 , 这 是 Flink 最 重 要 的 一 个 特 性 。 Flink 基 于 Chandy-Lamport 算法实现了一个分布式的一致性的快照, 从而提供了一致性的语义。 Chandy-Lamport 算法实际上在 1985 年的时候已经被提出来, 但并没有被很广泛的应用, 而 Flink 则把这个算法发扬光大了。Spark 最近在实现 Continue streaming, Continue streaming 的目的是为了降低它处理的延时,其也需要提供这种一致性的语义, 最终采用 Chandy-Lamport 这个算法, 说明 Chandy-Lamport 算法在业界得到了一定的肯定。
提供了一致性的语义之后, Flink 为了让用户在编程时能够更轻松、 更容易地去管理 状态,还提供了一套非常简单明了的 State API, 包括里面的有 ValueState、 ListState、 MapState,近期添加了 BroadcastState, 使用 State API 能够自动享受到这种一致性的 语义。
除此之外,Flink 还实现了 Watermark 的机制,能够支持基于事件的时间的处理,或者说基于系统时间的处理, 能够容忍数据的延时、 容忍数据的迟到、 容忍乱序的数据。 另外流计算中一般在对流数据进行操作之前都会先进行开窗, 即基于一个什么样的窗口上 做这个计算。 Flink 提供了开箱即用的各种窗口, 比如滑动窗口、 滚动窗口、 会话窗口以及非常灵活的自定义的窗口。

1.5 批处理与流处理
批处理的特点是有界、 持久、 大量, 批处理非常适合需要访问全套记录才能完成的 计算工作,一般用于离线统计。 流处理的特点是无界、 实时, 流处理方式无需针对整个数据集执行操作, 而是对通过系统传输的每个数据项执行操作, 一般用于实时统计。
在 Spark 生态体系中, 对于批处理和流处理采用了不同的技术框架, 批处理由SparkSQL 实现, 流处理由 Spark Streaming 实现, 这也是大部分框架采用的策略, 使用独立的处理器实现批处理和流处理, 而 Flink可以同时实现批处理和流处理。
Flink 是如何同时实现批处理与流处理的呢? 答案是,Flink 将批处理( 即处理有限的静态数据)视作一种特殊的流处理 。Flink 的核心计算架构是下图中的 Flink Runtime 执行引擎, 它是一个分布式系统, 能够接受数据流程序并在一台或多台机器上以容错方式 执行。
Flink Runtime 执行引擎可以作为 YARN( Yet Another Resource Negotiator) 的应用程序在集群上运行, 也可以在 Mesos 集群上运行, 还可以在单机上运行(这对于调试 Flink 应用程序来说非常有用)。
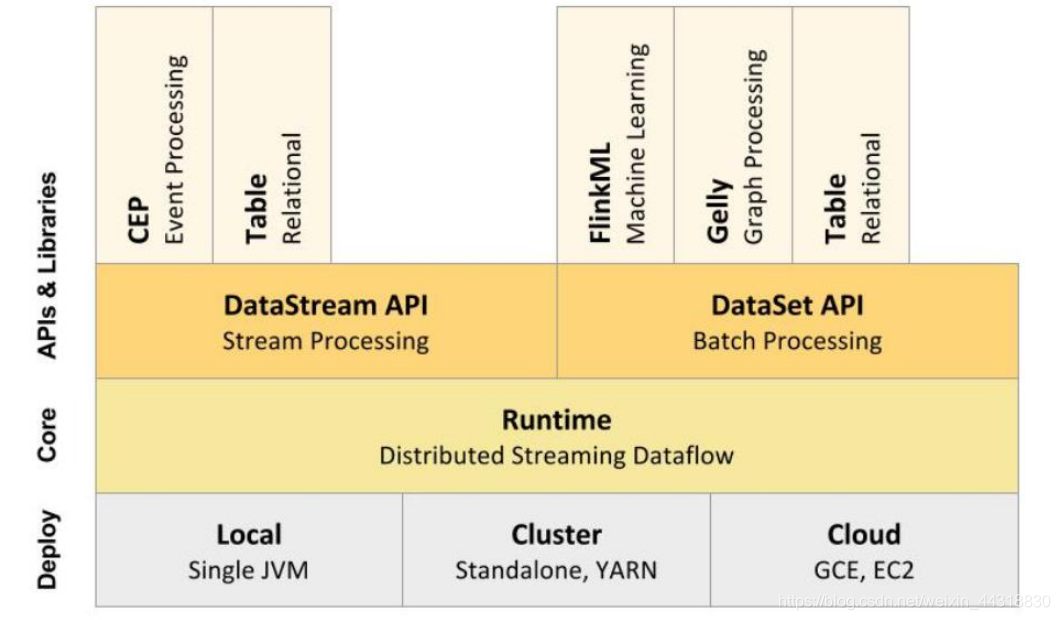
从下至上:
1、部署: Flink ⽀持本地运⾏、能在独⽴集群或者在被 YARN 或 Mesos 管理的集群上运⾏,也能部署在云上。
2、运⾏: Flink 的核⼼是分布式流式数据引擎,意味着数据以⼀次⼀个事件的形式被处理。
3、API: DataStream、 DataSet、 SQL API。
4、扩展库: Flink 还包括⽤于复杂事件处理,机器学习,图形处理
上图为 Flink 技术栈的核心组成部分, 值得一提的是, Flink 分别提供了面向流式处理的接口(DataStream API) 和面向批处理的接口(DataSet API) 。 因此, Flink 既 可以完成流处理,也可以完成批处理。 Flink 支持的拓展库涉及机器学习(FlinkML) 、 复杂事件处理(CEP) 、 以及图计算(Gelly) , 还有分别针对流处理和批处理的 Table API。
能被 Flink Runtime 执行引擎接受的程序很强大, 但是这样的程序有着冗长的代码, 编写起来也很费力, 基于这个原因, Flink 提供了封装在 Runtime 执行引擎之上的 API, 以帮助用户方便地生成流式计算程序。 Flink 提供了用于流处理的 DataStream API 和用 于批处理的 DataSetAPI。值得注意的是,尽管 Flink Runtime 执行引擎是基于流处理的, 但是 DataSet API 先于 DataStream API 被开发出来, 这是因为工业界对无限流处理的需 求在 Flink 诞生之初并不大。DataStream API 可以流畅地分析无限数据流, 并且可以用 Java 或者 Scala 来实现。 开发人员需要基于一个叫 DataStream 的数据结构来开发, 这 个数据结构用于表示永不停止的分布式数据流。
Flink 的分布式特点体现在它能够在成百上千台机器上运行, 它将大型的计算任务分成许多小的部分, 每个机器执行一部分。 Flink 能够自动地确保发生机器故障或者其他错误时计算能够持续进行, 或者在修复 bug或进行版本升级后有计划地再执行一次。 这种能力使得开发人员不需要担心运行失败。 Flink 本质上使用容错性数据流, 这使得开发人员可以分析持续生成且永远不结束的数据( 即流处理)。
二、Flink 架构体系
2.1 Flink 中的重要角色
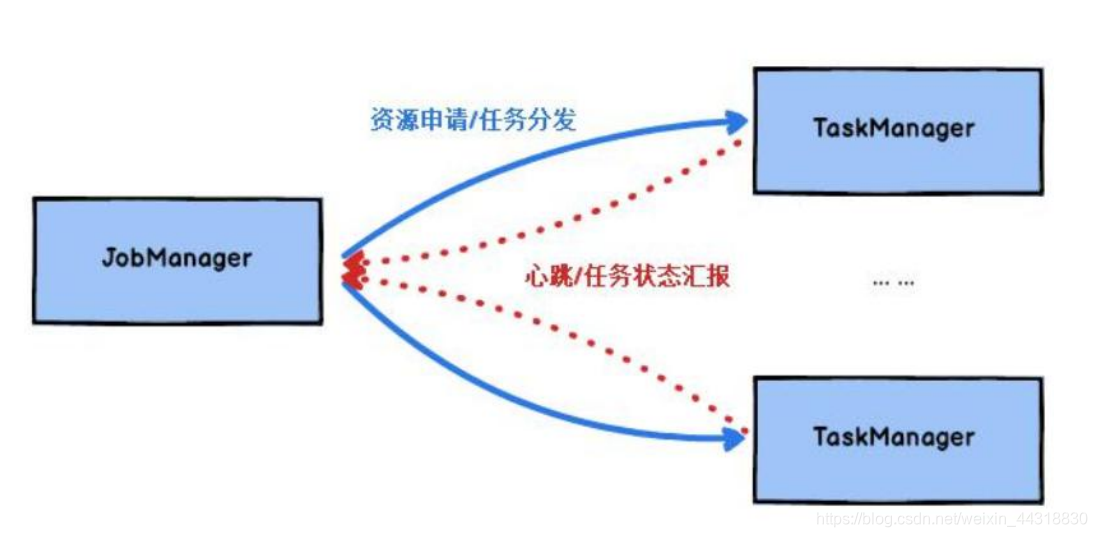
JobManager 处理器:
也称之为 Master, 用于协调分布式执行, 它们用来调度 task, 协调检查点, 协调失败时恢复等。 Flink 运行时至少存在一个 master 处理器, 如果配置高可用模式则会存在多个master 处理器, 它们其中有一个是 leader, 而其他的都是 standby。
TaskManager 处理器:
也称之为 Worker, 用于执行一个 dataflow 的 task (或者特殊的 subtask)、 数据缓冲和 datastream 的交换, Flink 运行时至少会存在一个 worker 处理器。
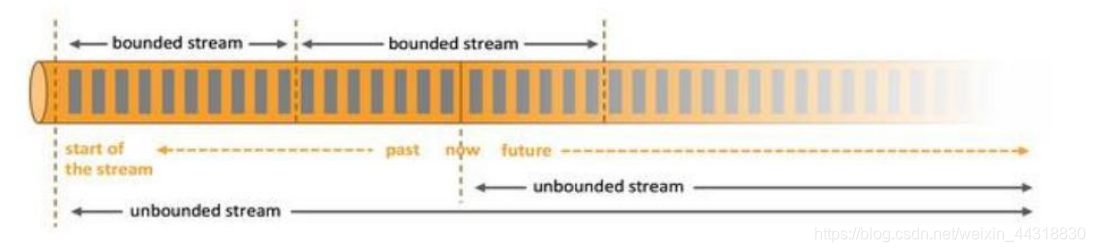
2.2 无界数据流与有界数据流
无界数据流: 无界数据流有一个开始但是没有结束, 它们不会在生成时终止并提供数据, 必须连续处理无界流, 也就是说必须在获取后立即处理 event。 对于无界数据流我们无法等待所有数据都到达, 因为输入是无界的, 并且在任何时间点都不会完成。 处理无界数据通常要求以特定顺序( 例如事件发生的顺序) 获取 event, 以便能够推断结果完整性。
有界数据流: 有界数据流有明确定义的开始和结束,可以在执行任何计算之前通过获取所有数据来处理有界流, 处理有界流不需要有序获取, 因为可以始终对有界数据集进行排序, 有界流的处理也称为批处理。
Apache Flink 是一个面向分布式数据流处理和批量数据处理的开源计算平台, 它能够基于同一个 Flink 运行时(Flink Runtime), 提供支持流处理和批处理两种类型应用的功能。 现有的开源计算方案, 会把流处理和批处理作为两种不同的应用类型, 因为它们要实现的目标是完全不相同的: 流处理一般需要支持低延迟、 Exactly-once 保证, 而批处理需要支持高吞吐、 高效处理,所以在实现的时候通常是分别给出两套实现方法, 或者通过一个独立的开源框架来实现其中每一种处理方案。 例如, 实现批处理的开源方案有 MapReduce、 Tez、 Crunch、 Spark, 实现流处理的开源方案有 Samza、 Storm。
Flink 在实现流处理和批处理时, 与传统的一些方案完全不同, 它从另一个视角看待 流处理和批处理, 将二者统一起来: Flink 是完全支持流处理, 也就是说作为流处理看待时输入数据流是无界的; 批处理被作为一种特殊的流处理, 只是它的输入数据流被定义为有界的。 基于同一个 Flink 运行时(Flink Runtime), 分别提供了流处理和批处理 API, 而这两种 API 也是实现上层面向流处理、 批处理类型应用框架的基础。
2.3 Flink 数据流编程模型
Flink 提供了不同的抽象级别以开发流式或批处理应用。
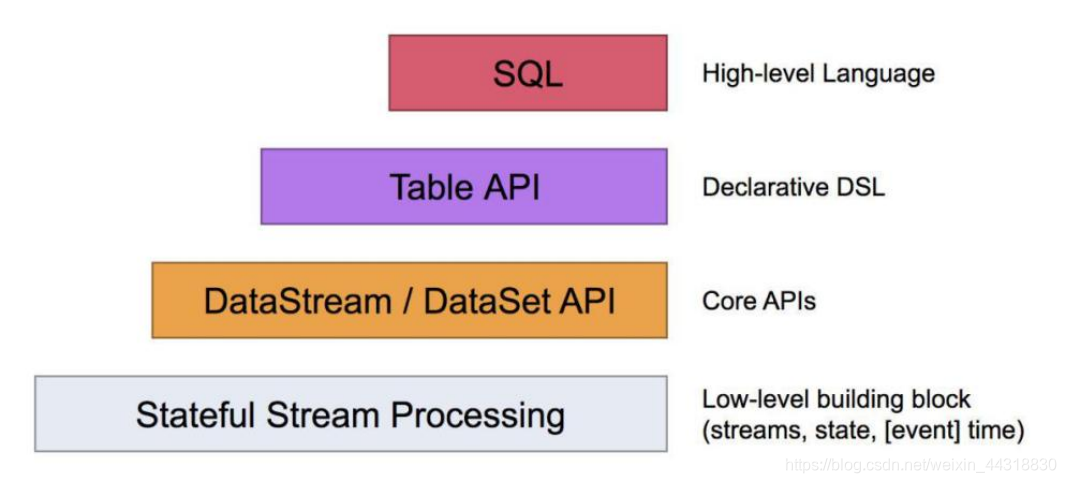
最底层级的抽象仅仅提供了有状态流, 它将通过过程函数( Process Function) 被嵌入到 DataStream API 中。 底层过程函数(Process Function) 与 DataStream API 相集成, 使其可以对某些特定的操作进行底层的抽象, 它允许用户可以自由地处理来自一个或多个数据流的事件, 并使用一致的容错的状态。 除此之外, 用户可以注册事件时间并处理时间回调, 从而使程序可以处理复杂的计算。
实际上, 大多数应用并不需要上述的底层抽象, 而是针对核心 API(Core APIs) 进 行编程,比如 DataStream API(有界或无界流数据) 以及 DataSet API(有界数据集) 。 这些 API 为数据处理提供了通用的构建模块, 比如由用户定义的多种形式的转换 ( transformations) , 连接(joins) , 聚合(aggregations) , 窗口操作(windows) 等等。 DataSet API 为有界数据集提供了额外的支持, 例如循环与迭代。 这些 API 处理 的数据类型以类(classes) 的形式由各自的编程语言所表示。Table API 是以表为中心的 声明式编程, 其中表可能会动态变化(在表达流数据时) 。 TableAPI 遵循(扩展的) 关 系模型: 表有二维数据结构(schema) (类似于关系数据库中的表) , 同时 API 提供 可比较的操作, 例如 select、 project、 join、 group-by、 aggregate 等。
Table API 程序声明式地定义了什么逻辑操作应该执行, 而不是准确地确定这些操作代码的看上去如何 。尽管 Table API 可以通过多种类型的用户自定义函数(UDF) 进行扩展, 其仍不如核心 API 更具表达能力, 但是使用起来却更加简洁(代码量更少) 。 除 此之外, Table API 程序在执行之前会经过内置优化器进行优化。你 可 以 在 表 与 DataStream/DataSet 之 间 无 缝 切 换 ,以 允 许 程 序 将 Table API 与 DataStream 以及 DataSet 混合使用。
Flink 提供的最高层级的抽象是 SQL 。 这一层抽象在语法与表达能力上与 Table API 类似,但是是以 SQL 查询表达式的形式表现程序。 SQL 抽象与 Table API 交互密切, 同 时 SQL 查询可以直接在 Table API 定义的表上执行。
| Spark | Spark Flink |
|---|---|
| RDD/DataFrame/DStream | DataSet/Table/DataStream |
| Transformation | Transformation |
| Action | Sink |
| Task | subTask |
| Pipeline | Oprator chains |
| DAG | DataFlow Graph |
| Master + Driver | JobManager |
| Worker + Executor | TaskManager |
2.4 Libraries 支持
Flink的函数库
-
支持机器学习( FlinkML)
-
支持图分析( Gelly)
-
支持关系数据处理( Table)
-
支持复杂事件处理( CEP)
小结
本篇博客,博主从Flink的引入再到为大家介绍了Flink的流处理特性,以及后续我们会详细讨论的Flink四大基石的简介,然后又为大家解析了Flink的架构体系等等…
看了这么久,不知道大家是否已经摩拳擦掌,想要尽快将Flink安装好,一探究竟。不用担心,下一篇博客,我们就要来 谈谈 Flink 的 环境搭建,各位小伙伴们敬请期待😎
如果以上过程中出现了任何的纰漏错误,烦请大佬们指正😅
受益的朋友或对大数据技术感兴趣的伙伴记得点赞关注支持一波🙏
希望我们都能在学习的道路上越走越远😉















 461
461











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











