







基础的东西经过很长时间积累而且还会在未来至少10年通用。
指针是一个特殊的变量,它里面存储的数值被解释成为内存(用户空间的虚拟内存)里的一个地址。
一、指针的属性
一个指针包含四个方面的内容:指针的类型、指针所指向的类型、指针所指向的内存区、指针本身所占据的内存区。
接下来就下面几个例子作说明:
1、 int *p;
2、 char *p;
3、 int **p;
4、 int (*p)[3];
5、 int *(*p)[4];1.1、指针的类型
从语法的角度,只要把指针声明语句里的指针名字去掉,剩下的部分就是这个指针的类型,即指针本身所具有的类型。
1、 int *p; //指针的类型是 int*
2、 char *p; //指针的类型是 char*
3、 int **p; //指针的类型是 int**
4、 int (*p)[3]; //指针的类型是 int(*)[3]
5、 int *(*p)[4]; //指针的类型是 int*(*)[3]然后有的人还是不知道怎么读…(后面再说)
插播:指针类型说明原则:从变量名处起,根据运算符优先级结合,一步一步分析。
1.2、指针所指向的类型
通过指针来访问指针所指向的内存区时,指针所指向的类型决定了编译器将把那片内存区里的内容当做什么看待,简而言之,就是编译器会在内存中预留出多大的内存空间给这个指针
从语法上,把指针声明语句中的指针名字和名字左边的指针声明符*去掉,剩下的就是指针所指向的类型。
1、 int *p; //指针所指向的类型是 int
2、 char *p; //指针所指向的类型是 char
3、 int **p; //指针所指向的类型是 int*
4、 int (*p)[3]; //指针所指向的类型是 int()[3]
5、 int *(*p)[4]; //指针所指向的类型是 int*()[3]注意指针的类型和指针所指向的类型是两个概念,当然第一个其实没什么卵用,后面这个概念才是重点。
指针所指向的类型,表示了编译器为给这个指针所指向的区域分配了多大内存,这个概念是非常重要的,尤其在指针进行自增自减,以及加减常数运算的时候。
比如:
1、 int *p; //对于这个编译器为p所指向的类型预留了4个字节的空间(int类型),p++的时候,
//是以4个字节为单位进行递增的(p+2,实则是偏移了2*4个字节的位置)
2、 char *p; //以一个字节为单位(char占用1个字节)
3、 int **p; //以4个字节为单位(int * 占用4个字节)
4、 int (*p)[3]; //首先这是个数组指针(指向一个大小为3的数组,里面存放的是int类型),以12个字节为单位
5、 int *(*p)[4]; //同样12个字节为单位,数组里面存放的是int*类型(4个字节)
6、 struct str *p; //就是以sizeof(struct str)为单位了
7、 void *p; //p++,就出错了,因为p所指向的类型是未定义的,即编译器不知道该为这个p所指向的类型分配多大空间 这个概念非常重要,尤其在处理指针偏移量的时候,是以该指针所指向的数据类型为单位。
在32位系统下,任何指针变量所占用的空间都是4个字节(32位),包括void*,这样意味着每个指针变量的寻址空间是0~2^32-1(即4G的寻址空间)。
1.3、指针所指向的内存区域地址
指针的值就是指针本身存储的数值,这个值被编译器当做一个地址,指针所指向的内存区就是从指针的数值所表示的那个内存地址开始,长度为 sizeof(指针所指向的类型)的一片内存区。
结合上面的第二点(指针所指向的类型),定义一个指针,我们就可以知道这个指针的有效区域,什么意思呢,看下面
1、 int *p; //p数值表示这块区域的首地址,哪个地方结束呢,(unsigned long)p+sizeof(int)编译器会划定长度为 sizeof(指针所指向的类型)的一片内存区给这个指针变量,就是说用户程序使用这个指针变量(解引用*)时,编译器得知道p所表示的地址后面还有多少的空间数据是属于这个指针变量的,不多也不少。
1.4、指针本身所占据的内存区
前面说了,32位平台里,指针本身占据了4个字节的长度。
一个指针本身占据有内存的话,那么这个指针是一个左值,否则就不是一个左值。
用哲学的观点解释就是,世界是物质的,一个变量要作为左值,它得自身占据一个内存空间, 不然赋值给它的对象放在哪
如果一个表达式的结果是一个指针,那么这个表达式就叫指针表达式。
int a;
int *pa;
pa = &a;//&a是一个指针,但是它不能作为左值,因为&a它本身没有占据明确的内存x=y;
左值:在这个上下文环境中,编译器认为 x 的含义是 x 所代表的地址。这个地址只有编译器知道,在编译的时候确定,编译器在一个特定的区域保存这个地址,我们无需知道;
右值,在这个上下文环境中,编译器认为 y 的含义是 y 所代表的地址里面的内容,这个内容是什么,只有到运行时才知道。
pa 与 &a 在编译器看来是不一样的。编译器没有为 &a 这个东东分配一块内存来存其地址,皮之不存毛将安附焉。
二、指针的算术运算
2.1、指针的加减整数
指针可以加上或减去一个整数。但是它加减的单位不是单纯的整数,而是整数*sizeof(指针所指向的类型),这个在前面的第2点讲述了,这里不赘述。
强制类型转换不会改变原有指针的类型
char str[20] = "hello world";
int *p = (int *)str; //str的类型不变
++p; // *p的值?str的类型不变是什么意思呢,就是str++还是以sizeof(char)为单位进行运算的。
p 被初始化为指向整型变量str,我们知道str表示这个char数组的首地址,第二行语句就是把这个首地址赋值给p,进行强制转换的意图就是重新把str所指向的这块区域进行细分,原来是char类型,是以1个字节为单位划分的,现在是int类型,就成了以4个字节为单位划分的。
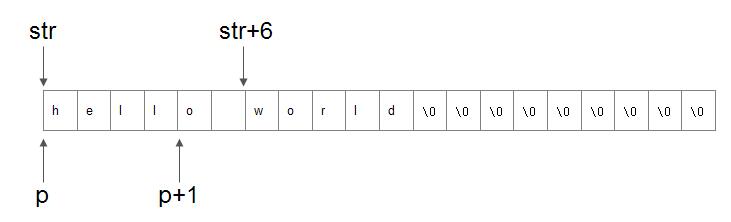
所以++p之后,p就到了图中p+1的位置处,那么++p之后*p的值呢?
为方便说明,我们令 pt = p+1; 那么pt对应的区域就是 o wo这四个字符占据的空间,然后转换为asscii码就是(十六进制) 6F,20,77,6F, *pt的值还需要考虑你测试机器的大小端模式,X86是小端模式,所以 *pt = 0x6F77206F = 1870078063
* ((char*)p) = ‘o’
对此,我们要清楚的认识到,指针的运算实值是地址的偏移,加往后偏移,减则往前面偏移, 所以 a[-1]是正确的,当然前提是这个位置是定义了的,而不是未映射区域。由此可以导出一点,指针的偏移操作不能超出范围(指针语义上没错,但一旦应用程序中这样使用,保你崩溃)
另外,两个指针不能进行加法运算,进行加法后,得到的结构指向一个不知所向的地方;两个指针可以进行减法操作,但必须类型相同,一般用于确定两个同类型指针变量之间的偏移量,linux内核数据结构 list 就是很好的应用这一特性的典范。
2.2、运算符&和*
这里讨论是C语言中的指针,& 不涉及到C++中的引用语义。
这里 & 是取地址运算符,之前我们说过世界是物质的,在计算机内存中也不例外,一个有效变量它总会在内存的某个地方占据一个对应的空间大小,用于存放这个数值,而&则是获取这个变量存放的地址。
&a 的结果自然是一个指针,*习惯称之为解引用,*p就是获取p所指向的内容。
三、指针和数组
指针是指针,数组是数组,两个是不一样的东西
- 指针就是指针,指针变量在32位系统下,永远占4个byte,其值为某一个内存的地址,指针可以指向任何地方,但不是任何地方你都能通过这个指针访问到。
- 数组就是数组,其大小与元素的类型和个数有关,定义数组时,必须指定其元素的类型和个数、数组可以存任何类型的数据,但不能存函数,可以存函数指针。
指针与数组之间的恩恩怨怨起源于,数组名表示数组首元素的地址
C语言中,当一维数组作为函数参数的时候,编译器总是把它解析成一个指向其首元素首地址的指针。(仅限于一维数组)
这也是为什么无法向函数传递一个数组,而必须在传递的同时指定数组的长度。
看下面
int a[5] = {1,2,3,4,5};
//a 表示数组首元素的地址,即a[0]的地址,*a = 1
//&a 表示数组的首地址
//&a[0] 也表示数组首元素的地址有趣的事,上面三个变量的数值是一样的,其数值就是数组的首位置地址。但是意义是不同的,用前面第一章第2点的说法(指针所指的数据类型)来解释就是,这三个变量代表的意义是不同的,这就表示它们自增之后的数值就不一样了。
a+n 的值是 &a[0] + n * sizeof(int);
&a+1 的值是 &a[0] + 1 * sizeof(a) = &a[0] + 1*5*sizeof(int);
那么 a 和 &a[0] 的区别在哪呢,这两个变量作为右值的话,是没有区别的,都是表示数组首元素的地址,而不是数组的地址。
但是,a 不能作为左值,编译器没有为数组a分配一块内存来存其地址,另外我们只能访问数组的某个元素而无法把数组当一个总体进行访问。
因为数组名表示该数组首元素的地址,所以我们可以用指针获取这个地址值,然后增加偏移量来读取数组元素
就一维数组和一级指针而言,二者在一定程度上是等效的,根据上面的分析,很好理解应用。
二维数组与指针
看看二维数组,首先把内存看做是一个连续的一维大数组,二维只是我们为了方便处理把它意识形态上的划分为二维,其本质还是一维的。
int a[3][4];上面声明了一个二维数组,三行四列,
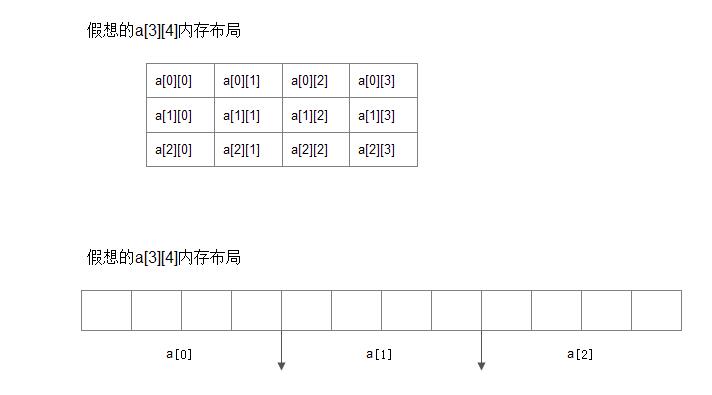
然后尝试用指针对这个二维数组进行元素访问。由上图可知,编译器总是将二维数组看成一个一维数组(更高维数也是一样的),而一维数组的每一个元素又都是一个数组。
a[0]这个一维数组的三个元素分别为 a[0],a[1],a[2],而这个a[0],a[1],a[2]又都是一个有四个元素的一维数组
int a[3][4] = { 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 };
所以上面后面的a[0],a[1],a[2]的首地址分别为 &a[0], &a[0] + 1*sizeof(a[0]), &a[0] + 2*sizeof(a[0]);
也就是说 a[i] 的首地址为 &a[0] + i * sizeof(a[0]); 而后a[i] 中有是个int 类型的元素,其每个元素的首地址分别为 &a[i], &a[i] + sizeof(int),&a[i] + 2*sizeof(int),&a[i] + 3*sizeof(int);
所以 a[i][j] 的首地址为 &a[i]+j*sizeof(int) ,在把 &a[i] 的值用 &a[0] 表示:
a[i][j]元素的首地址为 &a[0] + i * sizeof(a[0]) + j*sizeof(int) , &a[0] 和 a 作为右值是一样的,所以上面就等于 a + i * sizeof(a[0]) + j*sizeof(int) ;其中的a[0]就是上图中的包含4个int变量的一维数组。
再回到第一章的第二点(指针所指向的数据类型),a[0] 是一个一维数组,a 等效于 &a[0],a+i 就等同于 &a[0] + i + sizeof(a[0]) //把a[0]当做一个整体元素看待,这里 a+i 就表示了a这个二维数组中的第i个一维数组,(a+i) 就是取这个二维数组的第i个元素,这个元素是个一维数组,所以取到的值是这个一维数组的首地址,上面后面 + j*sizeof(int),就是这个一维数组偏移 j*sizeof(int) 个字节位置,等效于 (a+i)+j,定位到了这个一维数组的第j个元素的首地址,所以再取这个元素值就是 * ( *(a+i)+j)。
所以,由此会衍生一个问题,就是二维数组的初始化声明的时候,第一个数字是可以不填写的
int a[][4] = { 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 };//correct
int a[3][] = { 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 };//error原因相信你们都知道,看到第一个知道怎么划分,第二个声明呢,你会知道怎么划分么?3*4,3*5…
四、二级指针
二级指针也是经常用的,比如函数传参,一级指针传参是为了修改其值,二级指针传值就是为了修改其一级指针,比如C语言实现链表结构,创建链表不带返回值时,就需要借助二级指针。
二级指针它终究是指针,它表示的也还是一个地址,只是这个地址里面的内容仍然是一个地址,对于一维数组需要 * 解引用一次,对于二维数组则需要 * 解引用两次。
二维数组和二级指针
首先,指针和数组是两个概念,一维数组和一级指针在一定程度上可以等效,因为,然后二维数组和二级指针就真没什么关系了。
事实上,我们可以利用一维数组与一级指针的某种等效关系,将两个“降维”处理再进行等效。
上一节说到,二维数组必须指定维数,必须指定后面的维数。
int a[][4] = { 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 };
int (*p)[4] = a;看到“降维”了吧,p 是一个数组指针,指向一个数组,每个数组里面有4个int变量。
p 是一个数组指针,指向的是一个有4个 int 变量的数组,这里是{0,1,2,3} 四个元素,p+1 指向的数组里面的元素就是{4,5,6,7}
p+1 地址偏移了多少个字节,就看 p 这个指针指向的数据是什么类型的,这里是 一个存放四个 int 变量的数组,所以 p+1 偏移的字节数就是 4 * sizeof(int) bytes。
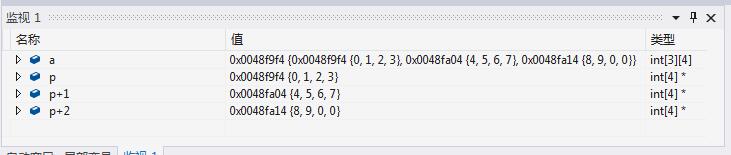
那么回过头,可以不可以用 指针数组 替代呢?
回答这个问题前,我们先来了解下 数组指针 和 指针数组
五、复杂指针类型
5.1、数组指针和指针数组
- 数组指针:首先它是一个指针,它指向一个数组。在32位系统下永远是占4个字节,至于它指向的数组占多少个字节,看声明。它是“指向数组的指针”的简称。
- 指针数组:首先他是一个数组,数组的元素都是指针,数组占多少字节由数组本身决定(指针本身占用的字节是固定的),它是“存储指针的数组”的简称。
到底如何判断是数组指针还是指针数组,以及后面的函数指针,函数指针数组等等更为复杂的指针类型,就涉及到复杂指针的读法了。
原则上:从变量名处起,根据运算符优先级结合,一步一步分析。
这里先看数组指针和指针数组:
int *p1[10]; //A
int (*p2)[10]; //B根据上面的元组,根据运算符优先级结合
对于A,[] 的优先级高于 * ,所以 p1 首先跟[] 结合,p1 是一个数组,这个数组存储的元素是什么类型的呢? int*,所以 p1 是一个指针数组,且存放了10个这样的 int* 。
对于B,()的优先级高于[],看()里面,* 与p2构成一个指针,所以p2首先是一个指针,再看外头的[],这个指针指向一个数组,所以p2是一个数组指针,那么这个数组里面存放的数据类型是什么呢,int。
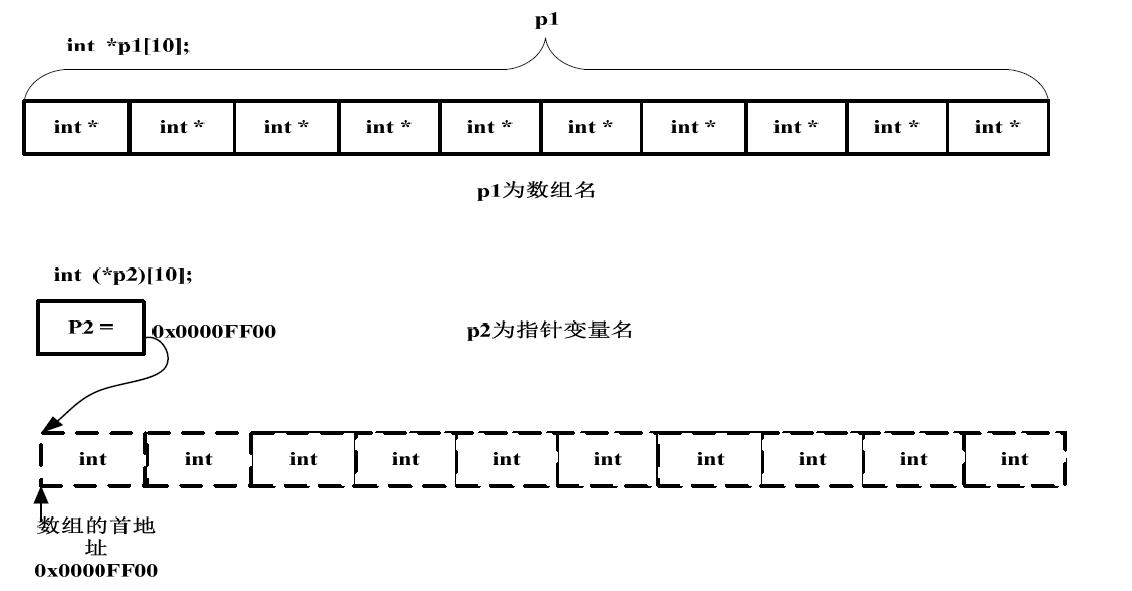
从上面的分析步骤,我们看到一个指针也好看到一个数组也好,首先要有这么个概念:看到指针要分析它的四要素,其实主要就是第二个,即这个指针指向的数据类型是什么,看到数组要分析这个数组存放的数据类型是什么,看到函数要分析这个函数的参数和返回值是什么类型的。
ok,再回到前面,我们得知,可以用数组指针代替一个二维数组,那么可否用指针数组来代替一个二维数组呢?
但是不行的,其实看了上面的指针数组和数组指针的内存布局,你就知道原因了,上图的第二个数组指针的内存布局和二维数组的内存布局是一样的,一个线性连续数组里面存放的都是int型变量,但是数组指针就不是了,里面存放的是 int*,数据类型都不一样了,你说能替代么?
那么很显然,二维数组也是不能通过二级指针替代的,二维数组需要明确知道第二维的维数(即第二个数字),你用二级指针替代,编译器完全不知道内部内存的划分细节了,二级指针变量解引用一次后自增,编译器不知道该偏移多少字节位置。
5.2、函数指针
函数指针顾名思义就是函数的指针,即指向一个函数的指针。
这个应用相当广泛,游览 linux kernel 的源码,随处可见,内核协议栈,VFS,文件操作函数等等充当各种接口。
char* (*fun1)(char *p1, char *p2);
char** fun2(char *p1, char *p2);
char* fun3(char *p1, char *p2);根据上面的优先级结合原则,和另一原则,看到指针分析它指向数据类型,看到函数分析它的形参和返回值类型。
对于fun1,首先它是一个指针,从变量名处开始,()锁定优先级高,然后与fun1结合,这个指针指向什么类型呢,看到后面有个(),说明这个指针指向一个函数,那麽这个函数的类型的,括号里面是函数形参,两个 char*,返回值也是char*;
对于fun2,首先人家是一个函数(看优先级()高于 * ),不是指针类型,这个函数的返回值类型是char**;
对于fun3,很普通的函数。
那么函数指针有何用处?最大的好处就是增加函数调用的灵活性,最常用于函数接口。
/*
* NOTE:
* read, write, poll, fsync, readv, writev can be called
* without the big kernel lock held in all filesystems.
*/
struct file_operations {
struct module *owner;
loff_t (*llseek) (struct file *, loff_t, int);
ssize_t (*read) (struct file *, char *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char *, size_t, loff_t *);
int (*readdir) (struct file *, void *, filldir_t);
unsigned int (*poll) (struct file *, struct poll_table_struct *);
int (*ioctl) (struct inode *, struct file *, unsigned int, unsigned long);
int (*mmap) (struct file *, struct vm_area_struct *);
int (*open) (struct inode *, struct file *);
int (*flush) (struct file *);
int (*release) (struct inode *, struct file *);
int (*fsync) (struct file *, struct dentry *, int datasync);
int (*fasync) (int, struct file *, int);
int (*lock) (struct file *, int, struct file_lock *);
ssize_t (*readv) (struct file *, const struct iovec *, unsigned long, loff_t *);
ssize_t (*writev) (struct file *, const struct iovec *, unsigned long, loff_t *);
};上面就是linux 内核中文件系统部分的源码,文件操作函数集,定义这个通用函数接口,编写内核驱动的时候,你可以自己实现对应的函数,然后把你的函数名赋值给上面的函数指针,这样就会调用你自己实现的函数了,这样就实现了,同样的函数接口可以通过调用不同的函数来实现不同的驱动。
5.3、函数指针数组
首先它是一个数组,数组里面存放的是函数指针。
怎么定义一个函数指针数组?
层层封装,首先是一个数组 pf[3],然后是指针数组 *pf[3],再然后是函数指针数组 (*pf[3])();ok 到了函数了,是什么形参什么返回值,个人需求了。
int* (*pf[3])(int *p);
//pf 是一个存放3个指针类型的数组,这个指针指向一个函数,这个函数的形参和返回值均是int* 类型学过C++的一定知道,C++实现多态的虚函数表,实际上是一个函数指针数组。详见C++对象模型
至于函数指针数组的指针,我们就不说了,举一反三,层层抽离、封装即可。
另外,函数名跟数组名是一个调调,都会被编译器解析为地址
5.4、复杂指针类型读法牛刀小试
5.4.1 ( * (void(*) () )0 )();
这是《C Traps and Pitfalls》这本经典书中的一个例子。怎么分析,读是层层剥离(优先级顺序),定义是层层封装(从右到左)
- void(*)(),这是一个函数指针,无参无返回值;
- (void(*)())0,这是将 0 强制转换为函数指针类型,0 是一个地址,就是说,这个函数保存在首地址为 0 的一段区域内(32平台下,这段区域长度是4个字节);
- (* (void(* ) ())0),增加一个解引用符号 *,即取 0 地址开始的一段内存里面的内容,其内容就是保存在首地址为 0 的一段区域内的函数,直白点,内容就是一个函数;
- ( * (void(*) () )0 )(),函数调用。
上面虽然没有看到习惯上的变量名,但是有 0 这个变量,常数也是变量啊
六、指针与结构体
指针可以指向任何数据类型,自然也包括结构类型。
//#pragma pack(1)
struct MyStruct
{
int a;
char c;
int b;
};
struct MyStruct ss = { 20, 'w', 40 };
struct MyStruct *pss = &ss;
int *ptr = (int *) &ss;上面的注释我就免了,如果看到这里,你还不知道,我只好说,你不适合走编程这条路。
我们都知道访问结构体成员的时候,我们都是这样的访问的
ss.a;
pss->b;//建议用这种,也最常用那么后面我们可以不可以通过 ptr 指针来访问呢,答案是否定的,这是因为结构体成员对齐的原因。
编译器在存放结构体对象的时候,一般会考虑字节对齐或双字节对齐等等,则需要在相邻两个非对齐成员(不同类型)之间补上若干个“填充字节”用于对齐。
因为结构体是把不同个数据类型成员捆绑在一起,不像数组里面的元素都是同一种类型。
回到上面,为何不能用 ptr 指针访问?
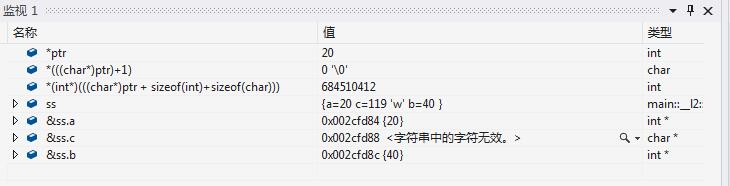
首先你可以通过 *ptr 获得第一个int 成员的值, *ptr == 20;
第二个char成员呢,你可以这样获得 * (((char*)ptr)+1) ==’w’;
那么后面的成员b,你怎么通过 ptr 获得,由 ptr 偏移 sizeof(int) + sizeof(char) 个字节?你可以试试,但是我会告诉你得到的结果绝对不是40,除非你的编译器是对结构器不对齐的,或者你添加了 #pragma pack(1)
看内存布局:
默认对齐方式下:
不对齐方式下(以1byte对齐),不注释#pragma pack(1)
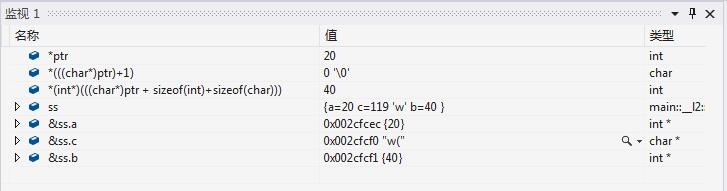
其余的不用看,直接看两种方式下,结构体中的成员的地址。
七、指针类型转换
其实前面我们或多或少的讲到了指针类型转换,记住一个原则,你在应用指针类型转换的时候,你要清楚转换对象与被转换对象的内存布局,上面的指针与结构类型一节就涉及到了。
强制类型转换之后,原来的指针的一切属性都没有被修改,转换后的指针,它所运算(指针加减)的单位变了。
char* 强制转换为 int*,转换后加减的单位成了4个字节,但是原来的指针还是不变的。
指针类型转换,在linux 内核网络协议栈中尤为常见,而且那里还是结构体类型的强制转换,不过人家大神在写那些结构体的时候,设计的时候都是严格按照成员对齐方式的,即使从链路层抽离网络层的ip首部,之后还是可以正确访问到ip首部数据的。
//下面代码来源于linux kernel 源码,以及博文中发送skb代码
static inline struct iphdr *ip_hdr(const struct sk_buff *skb)
{
return (struct iphdr *)skb_network_header(skb);
}
……
udph = (struct udphdr*)skb_push(skb, sizeof(struct udphdr));
iph = (struct iphdr*)skb_push(skb, sizeof(struct iphdr));
ethdr = (struct ethhdr*)skb_push(skb, sizeof(struct ethhdr));突然发现,linux kernel 源码真是一个学习C语言的好项目啊。
八、指针安全
前面一到七章,从各个层面分析了C语言中指针的好处,这也是C语言风靡至今屹立不倒的一个重要原因,但技术总是一把双刃剑,在带来强大功能的同时,也会带来一些列安全问题。
正因为指针可以指向用户空间内存的任意位置,这就意味着,我们可以读取甚至修改用户空间中用户程序可以访问的任一内存。
这是比较恐怖的,万一你通过指针去修改的那块内存,恰恰是一个代码段,或者另一个线程空间,那么程序就会崩溃。
为什么说一个进程下的某一个线程崩溃了,就会导致进程崩溃?首先确定这个崩溃是由于内存访问造成的。因为线程没有自己独立的内存地址空间,一个进程下的所有线程都是共享进程下的内存地址空间的,在一个线程中把另外一个线程的栈空间写坏是再正常不过的事情了。因为一个线程都可以通过内存地址(指针)访问到其他线程的栈空间,所以指针数据的错误可以导致任何同地址空间内其他线程的崩溃,当然也可以导致进程崩溃。
所以编写程序,在使用指针时,程序员心里必须非常清楚:我的指针究竟指向了哪里,用指针访问数组的时候,注意不要越界。换言之,你要确保你用指针访问的内存区域是安全的,对它进行访问不会产生安全隐患,不要去访问未定义区域。
结束语
至此,算是把C语言中的指针剖析的差不多了吧,本人做技术比较喜欢追溯内部细节和底层原理,知其然并知其所以然。
建议大家在学习C语言指针的时候,一定要手动编写程序逐个测试,做技术忌眼高手低。我个人初学(几年前了)的时候,比较喜欢调试,不是直接运行看结果,监视各个变量以及地址,再者就是通过反汇编看起汇编代码,熟悉内部原理。
visual studio 2013 这个 IDE 用于学习C和C++内部原理还是非常方便的,个人不打Windows和Linux的口水仗,但我还是喜欢在 linux下开发
阅读一些优秀的开源项目 linux kernel、STL(C++)等,在Windows下用SourceInsight看源码,然后在linux下开发,怪不得开发人员都要有两台电脑。
另外,由于 MarkDown 编辑器的原因,符号‘’在该编辑器中是一个操作符,所以在可能在某些地方声明指针的时候,可能会出现 被编辑器当作操作符处理了。















 495
495

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









