









一.基础概念的介绍
XML在各种开发中都广泛应用,Android也不例外。作为承载数据的一个重要角色,如何读写XML成为Android开发中一项重要的技能。今天就由我向大家介绍一下在Android平台下几种常见的XML解析和创建的方法。
.
(一)SAX解析器:
SAX(Simple API for XML)解析器是一种基于事件的解析器,它的核心是事件处理模式,主要是围绕着事件源以及事件处理器来工作的。当事件源产生事件后,调用事件处理器相应的处理方法,一个事件就可以得到处理。在事件源调用事件处理器中特定方法的时候,还要传递给事件处理器相应事件的状态信息,这样事件处理器才能够根据提供的事件信息来决定自己的行为。
SAX解析器的优点是解析速度快,占用内存少。非常适合在Android移动设备中使用。
.
(二)DOM解析器:
DOM是基于树形结构的的节点或信息片段的集合,允许开发人员使用DOM API遍历XML树、检索所需数据。分析该结构通常需要加载整个文档和构造树形结构,然后才可以检索和更新节点信息。
由于DOM在内存中以树形结构存放,因此检索和更新效率会更高。但是对于特别大的文档,解析和加载整个文档将会很耗资源。
.
(三)PULL解析器:
PULL解析器的运行方式和SAX类似,都是基于事件的模式。不同的是,在PULL解析过程中,我们需要自己获取产生的事件然后做相应的操作,而不像SAX那样由处理器触发一种事件的方法,执行我们的代码。PULL解析器小巧轻便,解析速度快,简单易用,非常适合在Android移动设备中使用,Android系统内部在解析各种XML时也是用PULL解析器。
以上三种解析器,都是非常实用的解析器,我将会一一介绍。我们将会使用这三种解析技术完成一项共同的任务。
.
.
二.文件解析的实现
.
(一)创建XMl文件
在项目的assets目录中创建一个XML文档cars.xml,如图所示:
.
.
双击打开xml文件,编辑内容如下:
<Car id="1" >
<mark>宝马</mark>
<color>蓝色</color>
</Car>
<Car id="2" >
<mark>奥迪</mark>
<color>白色</color>
</Car>
<Car id="3" >
<mark>保时捷</mark>
<color>黄色</color>
</Car>
写完XML文件,布局文件不写,直接写代码,解析xml文件。
.
(二)三种读取xml文件的方法的代码
package com.example.resource;
import java.io.InputStream;
import java.util.ArrayList;
import java.util.List;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
import org.xmlpull.v1.XmlPullParser;
import android.app.Activity;
import android.os.Bundle;
import android.util.Log;
import android.util.Xml;
public class MainActivity extends Activity {
// 要解析文件的输入流
InputStream is;
// 创建一个List集合存放从XML文件获取到的数据
List<Car> list = null;
Car car = null;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
pullXml();// 使用pull解析
saxXml();// 使用Sax解析
domXml();// 使用DOM解析
}
----------//开始解析数据
// 使用DOM解析数据
private void domXml() {
list = new ArrayList<Car>();
try {
// 从assets里面获取文件,
// 通过getAssets获取到的是读取流
is = getAssets().open("cars.xml");
// 取得DocumentBuilderFactory实例
DocumentBuilderFactory factory = DocumentBuilderFactory
.newInstance();
// 从factory获取DocumentBuilder实例
DocumentBuilder builder = factory.newDocumentBuilder();
// 解析输入流 得到Document实例
org.w3c.dom.Document doc = builder.parse(is);
Element root = doc.getDocumentElement();
NodeList items = root.getElementsByTagName("Car");
for (int i = 0; i < items.getLength(); i++) {
car = new Car();
Element item = (Element) items.item(i);
// 获取id属性
car.id = item.getAttribute("id");
NodeList properties = item.getChildNodes();
for (int j = 0; j < properties.getLength(); j++) {
Node property = properties.item(j);
String nodeName = property.getNodeName();
// 获取节点值的具体代码
if (nodeName.equals("mark")) {
car.mark = property.getFirstChild().getNodeValue();
} else if (nodeName.equals("color")) {
car.color = property.getFirstChild().getNodeValue();
}
}
list.add(car);
}
for (Car c : list) {
Log.e("DOM", c.toString());
}
} catch (Exception e) {
e.printStackTrace();
}
}
----------
//上面是DOM解析数据的过程
----------
// 使用SAX方法解析的结果
private void saxXml() {
try {
// 从assets里面获取文件,
// 通过getAssets获取到的是读取流
is = getAssets().open("cars.xml");
// 取得SAXParserFactory实例
SAXParserFactory factory = SAXParserFactory.newInstance();
// 从factory获取SAXParser实例
SAXParser parser = factory.newSAXParser();
// 实例化定义的Handler
Myhandler handler = new Myhandler();
// 根据Handler规则解析输入流
parser.parse(is, handler);
// 打印信息
handler.showMessage();
} catch (Exception e) {
e.printStackTrace();
}
// 实例话
}
//实现SAX方法解析数据必须要借助DefaultHandler 类的实现
class Myhandler extends DefaultHandler {
StringBuffer sb = null;
// 根标签开始时
@Override
public void startDocument() throws SAXException {
super.startDocument();
list = new ArrayList<MainActivity.Car>();
sb = new StringBuffer();
}
// 节点开始时
@Override
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
super.startElement(uri, localName, qName, attributes);
// 当遍历到Car节点就新建Car对象
if (localName.equals("Car")) {
car = new Car();
car.id = attributes.getValue(0);// 获取第一个属性值,节点值在后面获取
}
// 将字符长度设置为零,以便从新开始读取元素内就字符节点
sb.setLength(0);
}
// 读取字符流
@Override
public void characters(char[] ch, int start, int length)
throws SAXException {
super.characters(ch, start, length);
sb.append(ch, start, length);
}
// 节点结束时
@Override
public void endElement(String uri, String localName, String qName)
throws SAXException {
super.endElement(uri, localName, qName);
if (localName.equals("mark")) {
car.mark = sb.toString();
} else if (localName.equals("color")) {
car.color = sb.toString();
} else if (localName.equals("Car")) {
list.add(car);
}
}
public void showMessage() {
// 打印获得的数据
for (Car c : list) {
Log.e("SAX", c.toString());
}
}
}
----------
//上面是SAX方法解析数据的过程
----------
// 使用pull方法解析文件的具体操作
private void pullXml() {
try {
// 从assets里面获取文件,
// 通过getAssets获取到的是读取流
is = getAssets().open("cars.xml");
// 创建一个pull解析对象,并获取示例
XmlPullParser pull = Xml.newPullParser();
// 设置解析格式
pull.setInput(is, "utf-8");
// 开始解析
// 产生事件用来循环
int type = pull.getEventType();
// 实例化List集合存放从XML文件获取到的数据
list = new ArrayList<Car>();
// 通过判断事件,来获取相应的数据
while (type != XmlPullParser.END_DOCUMENT) {// 没到结束的根标签就一直循环获取
// 通过判断事件,
switch (type) {
case XmlPullParser.START_TAG:// 标签开始
// 获取节点值节点属性值的具体代码
if (pull.getName().equals("Car")) {// 当遍历到标签开始是Car
// 新建Car对象
car = new Car();
// 获取标签属性id,属性值和节点值的取法是不一样的
car.id = pull.getAttributeValue(0);
} else if (pull.getName().equals("mark")) {
// 获取标签的信息
car.mark = pull.nextText();
} else if (pull.getName().equals("color")) {
car.color = pull.nextText();
}
break;
case XmlPullParser.END_TAG:// 标签结束时
// 如果是Car标签结束,就对数据对象进行存储
if (pull.getName().equals("Car")) {
list.add(car);
}
break;
default:
break;
}
// 继续下一个标签
pull.next();
type = pull.getEventType();
}
// 打印一下集合的数据
for (Car car2 : list) {
Log.e("pull", car2.toString());
}
} catch (Exception e) {
e.printStackTrace();
}
}
----------
//上面的使用pull方法解析文件的过程
----------
//定义一个对象类,用来存放和显示数据
static class Car {
String id;
String color;
String mark;
@Override
public String toString() {
return "Car [id=" + id + ", color=" + color + ", mark=" + mark
+ "]";
}
}
}
程序运行后显示的Log内容如下:
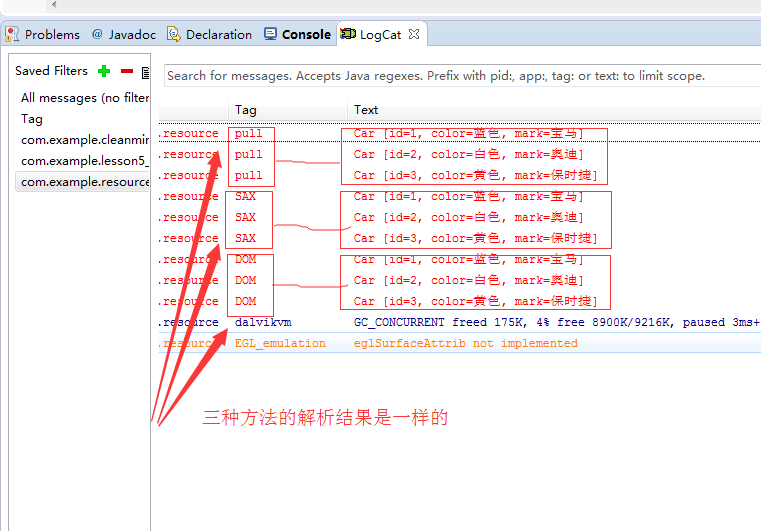
上面就是三种解析XML数据的方法,其中值得注意的是截取节点的值和截取节点的属性的值用的方法是不一样的。也要区分根节点和普通节点要执行的相关操作。
本示例主要数实现数据的解析过程,相关数据的处理没有很好的表现出来,但是结果都是能解析出正确的数值的。
对于这三种解析器各有优点,一般推荐使用PULL解析器,因为SAX解析器操作起来太笨重,DOM不适合文档较大,内存较小的场景,唯有PULL轻巧灵活,速度快,占用内存小, 使用非常顺手。大家也可以根据自己的喜好选择相应的解析技术。
上面是解析xml文件的三种基本方式,后面也会接触到很多其他封装类的解析方法。但是都是在上面基础上设计的。
















 425
425











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











