







4.2.6 IPv6
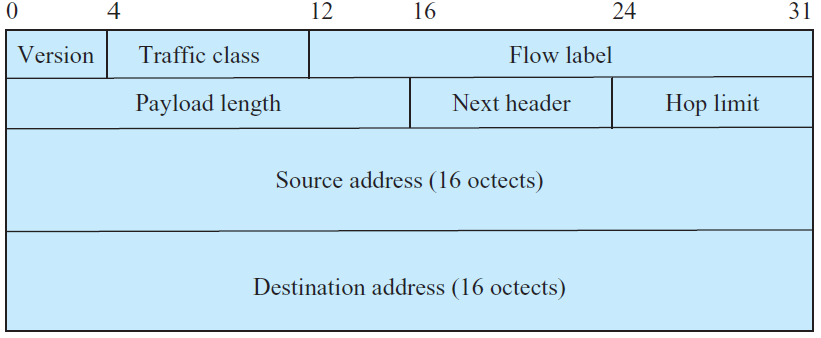
IPv6 header有固定的40bytes,没有option field,但是它有扩展头部。
Traffic class:类似于IPv4的TOS。
Flow label:用来识别相同流的数据包,如:视频流。
Payload lenght:不包括40bytes的ip header的数据包长度,多大为65535bytes。
Next header:表明上层协议类型或扩展头部。
Hop limit:类似于IPv4的TTL
每个address有128bits,有3中类型的地址:unicast, anycast, and multicast
Remark:没有了checksum field,所以router无需处理校验和;没有了分片flag,所以router无需处理分片。这两个措施有效的降低了router的负担。
IPv6的扩展头
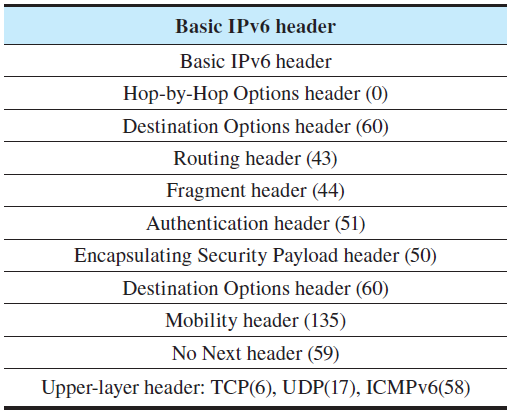
上面是IPv6可以携带的扩展头和其对应的协议字段。
扩展头的规则如下:
1)扩展头的顺序应该是上图的顺序。
2)处理扩展头的顺序要严格按照扩展头在packet中的出现顺序。
3)中间经过的router不应该处理除了Hop-by-Hop Options header以外的扩展头。
IPv6分片

上面是IPv6的分片的扩展头,跟IPv4类似。
Fragment offset、more fragment bit(M bit)和Identifier跟ipv4相同(请参考4.2.3)。
IPv6 address
IPv6包括unicast, multicast, and anycast三类。其中unicast包括与IPv4兼容的地址(prefix 00000000),Global Unicast Address和Link Local Unicast Address。multicast的prefix是11111111。一组router可能共用一个anycast address,目的地址为anycast的packet会被发送给一个距离它最近的router。
IPv4-compatible IPv6 address是由96个0后接IPv4的地址构成的。
IPv4-mapped IPv6 address是由80个0后接16个1再接IPv4的地址构成的。
Loop-back address是::1
Link local address不是全球唯一的,它仅用于自动地址配置和邻居发现等,它包括一个prefix1111111010后接56个0再接mac address
Autoconfigration
IPv6的自动配置无需通过DHCP,它是一种无服务器的自动配置。一个host先生成一个link local address,然后发送router solicitation message (an ICMP 信息).当router收到该信息后会相应一个router advertisement信息,该信息中包含了子网前缀信息。The host根据router advertisement信息产生一个global address。
Transition from IPv4 to IPv6
有两种转换方法:dual-stack and tunneling,由RFC 1933所规定。
拥有两个协议栈的router,负责将packet在ipv4和ipv6间互相转换,但是在转换的过程中会丢掉一些信息,因为ipv4 header不完全跟ipv6 header兼容。
IP tunneling可能建立在两个host间或两个router间,host将ipv6封装在ipv4的数据包中,该包通过ipv4的router,最终到达目的host。
[此为原创,转载请标明出处,谢谢!]














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









