






目录:
1. 前言.
2. 渊源.
3. 还原大纲
4. 开始还原 -- X86乱序整理.
5. 开始还原 –X86膨胀压缩.
6. 开始还原 –前X86(压缩后)转为Vm指令
7. 还原核心 – VM指令层.
8. 终章 – VM还原的核心秘密
代码地址:http://download.csdn.net/detail/whatday/7192725
1. 前言.
这篇文章写于2012年的8月,ZVM这个工程是我于2007年左右,一时头脑发晕而做的项目.做的时候是有考虑将其加密解密作为商业化运营的,如果失败,就当是体验一下这种所谓的CRACK界最强,也是最后一道防御是什么样子的.或者还能自己实现一套类似的软件.不管怎么说,研究VMP前后大约花掉我半年多的业余时间(最早还是个CONSOLE工程),还原引擎包含了VM指令调试器,X86层调试器,乱序重组系统,虚拟执行系统,压缩系统,以及一系列识别脚本系统.七七八八的工具加一起,总代码量大约是8W行左右(单独准备放出去的ZVM引擎本身就有3W左右).基本上做到了将所有的x86代码经过VM和混淆之后,精确的还原为原始代码(如果有jxx,逻辑先后到达顺序可能稍有不同).但是无法做到商业级应用(任何环境下100%还原),所以还是个实验室产品,由于基本的目的已经达到,加上完美的搞定还原,估计需要的精力和时间都不够,对于这个工程的前景不甚看好,就一直搁置了下去.
时隔5年,我早已放弃了将其商业化的想法,因为这东西会的人已经很多很多了.早些时候就有打算整理成文档,包括之前前就答应了紫色秋枫群里的朋友们,要写一篇VM还原的文,如今终于得空(被迫?),可以兑现承诺了,我将腾出这一个月的业余时间,尽量的阐述VM加密技术中种种尚未公开的奥秘给诸位,各位看官觉得好,给个顶字.也聊以安慰我也曾经为之痴狂的那些技术年月.在文章的最后,还将附上我写的还原引擎的源代码.代码虽然简陋,但是必须是完整的.希望能给大家有所参考的价值.
毕竟年代久远了,文中所述的VM保护这类思想和方法可能已经跟不上时代.加上先例甚少,很多名词多为个人杜撰.错漏之处,多多包含.另由于写这篇文章的时间有限,无法将我当年所有的记忆思路描述.有增删减补的地方,我会出个后篇统一处理.
顺便多说一个,工程之所以叫ZVM,一个意思是ZIP VM,因为VM类的加密,通常是把单独的少数指令,经过一系列复杂到变态的加密,生成了几百万条面目全非的指令洪流.仿佛就是一个无限膨胀的指令机器.所以还原的方法,也可以看做是一种压缩动作.至于另外一个意思就是我的网名叫ZV.也可以是ZVMachine.
2. 渊源.
我是在很偶然的机会下分析程序的时候知道VM这种技术的,当我见到VM的当时,以为是和花指令差不多的东西,然而网络之上,虽然有对于这类加密的基础性文章,但是大部分文章对于VMP(或者是TMD)这个级别的加密软件来说,只是一个方向性的阐述.对于研究其加密的核心思想,帮助很有限.
当时据我所知,国内唯一一个研究VM加密还原比较深入的人是我在看雪认识的SoftWorm前辈,不知道SoftWorm博士还记得当初一个给你写Email问TMD问题的网友么?SoftWorm当初研究的是TMD.就我们当时互通的Email看来,前辈应该是研究到了比较深入的程度.由于时间的关系,当时的我对TMD的研究,仅仅停留在压缩了混淆和膨胀代码 进入VM虚拟指令层面上.但是无论如何,这是我第一次和VM做正面碰撞,以失败告终.
从此之后我就留意上了VM加密技术,并对挑战这种加密系统充满了兴趣,正是因为如此,让我和这项技术之间有了一段估计在我毕生都记忆深刻的研究历史.
3. 还原大纲
就VMP使用的技术而论,包含了非常多的步骤,单独每一步拿出来,都可以作为一个完整的加密手段来讨论,实际上我在之后的工作中,分析到的一些加密或者有企图掩盖执行目的的代码的时候,经常有碰到VMP使用过的某些技术.可见VMP并不是一个单纯的以VM为加密手段的加密软件,甚至于,有些地方明显感觉到设计者企图采用不可逆的方式,为代码加密.这可能也是为什么它的难度处于所有VM类加密软件之首(就我当初看来是这样,已经很久不从事这行业,孤陋寡闻不要见怪).所以我有必要将其加密的过程(或者叫解密的顺序)列出一个大纲.对每一步进行讲解和讲述对应解密代码的功用.
值得一提的是,我的办法肯定不是最好的,就我研究VM的过程中,各种传闻都有听说.包括用人工智能还原,极致的算法还原,甚至于强悍的手工还原等等等等.诸如此类真真假假的东西甚多,不过可以确定的是,不是只有我一个人能够做到.只是我的办法是正面的对VMP进行强行攻击.将VMP加密的每一个步骤,都完完全全的反向倒推回去.所以虽然我的还原办法不是最好的办法.但是你却可以通过我的阐述,完整,系统的了解VMP这个软件的设计核心思想,以及所用到的繁复技术.这一点就是我这篇文章最大的价值所在.
首先,要设定一个软件版本,我这里使用的是我最后一个接触到的VMP的版本—1.7.0.所有的软件还原和代码,都是基于这个版本的VMP进行处理的.另外,准备几个用来试验的软件.分别是:
RADASM,这个用来写我们的测试代码,不用C的原因是ASM还原成C,这本身就是个香肠变猪的问题.我们还是从香肠变肉开始.
IDA,这个用来将还原引擎生成的中间代码,翻译成asm来阅读,以便保证后续还原的正确性.
下面介绍一下VMP的还原步骤,我个人将VMP的还原步骤分为以下几步:
--------------前X86层-------------
1. X86乱序整理
2. X86膨胀压缩
-------------VM层-------------
3. VM指令翻译
4. VM膨胀压缩
-----------后 X86层-------------
5. X86指令翻译
这里多介绍下VMP这个加密软件,这个软件是俄罗斯人写的,据说是同类加密软件中强度和难度最高的软件.它提供了如图所示的三种加密办法:
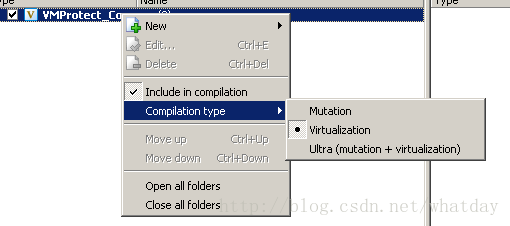
第一种加密,纯粹的代码混淆,简单说,就是只有上面列出的步骤中的1和2两个步骤.这种加密方式不包含VM加密核心,仅仅是对代码进行膨胀和乱序.这种加密对执行速度的影响很小,但是对代码的保护力度很差.通常只能阻止部分没有编码经验的分析者.通过写对应的程序,可以很快的还原出原始代码.
第二种加密,就是我重点研究的加密,也就是包含了上面列出的所有步骤.其强度已经达到了令人望而生畏的程度,也是VMP推荐的默认加密选项.
第三种加密,是高级加密,这种加密我没有分析,但是从字面上不难看出是前两种加密的结合体,本文重点讨论第二种加密方式.这种加密大同小异,略过不论.
另外,VMP中,影响加密之后代码的,还有一个所谓的虚拟机个数设定,在Option页,如图:

这个所谓的虚拟机个数设定,我分析之后发现,并不是设定执行的虚拟机的个数,
其原理不过是增加了无用代码中JXX镜像的数量.
我们假想一下,如果JXX指令之前的FLAG位,没有任何指令去设定,那么JXX指令是否跳转,就成了一种随机的不可预知的情况.
再者,如果JXX指令跳与不跳,目的地的代码都是一样的.那么JXX指令跳和不跳的就没什么区别了.这就是”镜像”.
于是这里就出现了个很好玩的情况,当你的VM代码处于多线程(且在多CPU的机器上)执行的时候.每个进入VM代码的线程,走的流程可能是不一样的,但是执行效果却相同,这可能就达到了设定虚拟机个数的目的,看下图,更好的理解下,这个设定的意思.
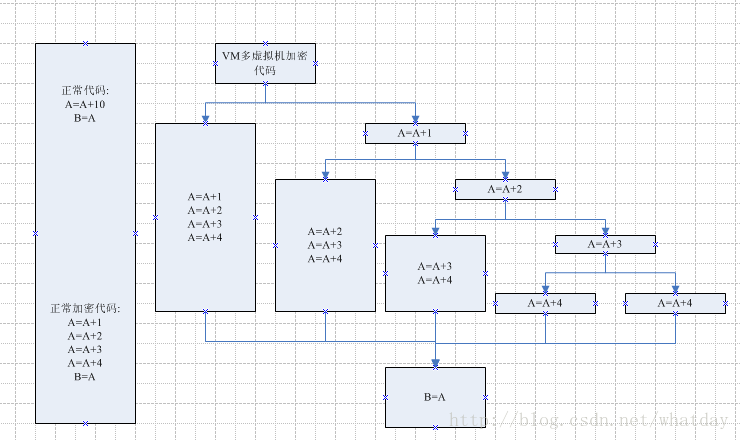
这就解释了为什么这个个数设置为9的时候,生成的软件体积将增加非常多,那是因为多了很多”镜像”代码,用于JXX的跳转(如图所示,生成的代码量相当于原始加密的3.5倍左右).
但是就还原难度而言,这个设定所带来的难度,几乎没有增加多少.也就是说,正常加密代码本身,就有带少量的JXX”镜像”,要解密的人,就必须处理这种问题,而这个选项只不过让这些镜像的数量更多了.但只要处理了,多少个”镜像”加密,意义都是一样的.
所以,这个设定估计是用来作为多线程乱入执行的用的,其最终实际含义,我也不甚明确.
除了上述说到的VMP的几个设定,对于生成的加密代码逆向有难度影响之外,其他的选项基本上都是作为反调试或者是其他目的,为了方便对VM做专题讨论,我们将其他Options部分设定的选项去掉.所以最终设定,如图:
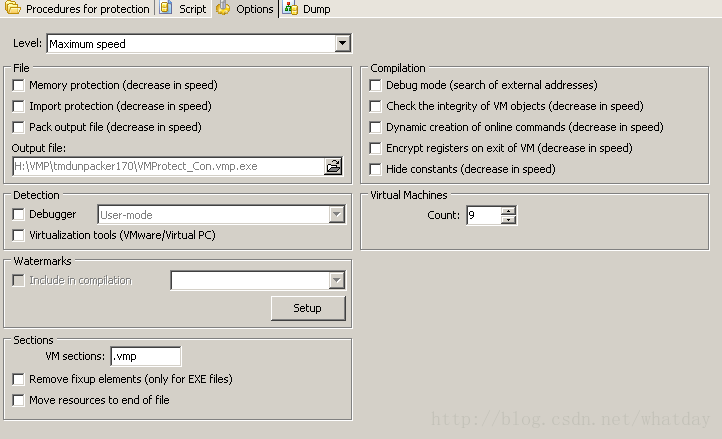
(注:如果你感觉解密测试的时候速度较慢,可以把虚拟机个数设置成1.)
VMP设定介绍完毕,以下每一个章节,将独立讨论每一个步骤的还原,最后一气呵成,还原出最终指令.为了阐述方便,我们首先设定一个实验环境.
打开RADASM,建立一个CONSOLE工程,并根据VMP的用法,引入头文件,添加要加密的指令和VM加密标记,编译生成EXE.附件ALL.Asm中就包含了我用来测试的所有指令,文章篇幅有限,就不粘贴了,这里我一开始使用了好几个指令作为例子,但是发现还原复杂度太高,讲解会浪费了太多描述不提,还经常造成我大脑打结.所以干脆只剩下一个指令,咱们循序渐进吧.最后再测试完整的例子,这份我加密后的exe,就是附件的test_vmp.exe,之后的截图,还是中间过程文件,都是以这个exe为主要例子:
.386
.MODEL FLAT ,STDCALL
.CODE
test_vmp proc
db 0EBh,10h,'VMProtect begin',0
xor eax,ebx;
db 0EBh,0Eh,'VMProtect end',0
ret
test_vmp endp
start:
calltest_vmp
ret
end start
接着用VMP打开这个EXE,根据上文所述环境设置,然后进行加密,生成EXE.(由于如果设定虚拟机个数为9,那么生成的代码体积硕大,不利于描述,所以暂时设定为1.)
用IDA打开这个EXE,如图所示,地址00401000处就是VMP的加密入口,我们这些代码就从这里开始.记下这个地址.到此为止,所有准备工作已经完成, 终于可以进入解密步骤了.
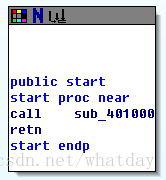

4. 开始还原 -- X86乱序整理.
从上一章节末尾的IDA截图来看,进入地址00401000之后,就是一个PUSH DWORD, 然后一个CALL进入了加密后的代码的执行.
这个PUSH DWORD的DWORD实际上是一个随机数,这个随机数不是无用的,恰恰相反,他起到一个非常重要的穿针引线的作用,简单的来说,这个DWORD就是一个KEY,他作用于如下多个地方:
1. 参与跳转的目标地址的计算.如果缺失这个DWORD,或者之前计算过程出错,那么你就永远也找不到下一段代码在何方了.
2. 参与立即数解密,我们用来加密的代码中,不可避免的包含这种那种的立即数,比如我们的测试例子中就有12345和23456,同样的,如果算错或者丢失了这个KEY,那么你最终得到的还原代码,失之毫厘差以千里.
这个KEY的值,在VM执行过程中不断的变化,且不只有一个KEY,因为VMP并不是把所有的指令都虚拟化了,只是把常见的指令(大体的说,就是intel手册上,OP为单个字节的指令,基本上都虚拟了,除了那些特权指令)给虚拟了,遇到没虚拟过的指令,VMP还原上下文,然后跳出虚拟机,以明文形式执行了这个”不认识”的指令之后,再次重入虚拟机.同样的情况有遇到CALL的时候.甚至VMP本身的加密代码,都可能自然的分成多个”模块”.
总之,当VMP出了虚拟机,再次进入虚拟机的时候,第一句代码都是一个KEY打头,然后是一个CALL指令,才是入口指针.
好了,光是一个PUSH DWORD就这么多说道,可见这个加密系统实在是有够麻烦,希望大家不要看不下去.大体上要弄懂VMP的精华,估计要前后多看几遍文章才行,盖因为我个人思维可能比较混乱,有时候概念遇到了就提前说明,大家看到的时候,可能对这些没有很直观的理解.
PUSH和CALL之后,跟着的就是一大串以JXX或者JMP或者是CALL或者是RET组成的代码乱流.
是的,你看到的所有的都是代码乱流,是毫无逻辑的,至于JXX,JMP,CALL,RET,这4种指令起的作用都是”衔接”.和逻辑无半毛钱关系.
(顺带提前说一句:VMP加密之后,所有原始的JXX,JMP,CALL,RET,都会被转为最终形式VM层的VM_JMP,所以你看到的所有X86的这些指令,都是衔接用的,一个真实的含义都没有).
(但是在只有混淆模式中,由于没有VM核心的参与,所以JXX,JMP,CALL,RET这些指令,可能是存在其本身含义的,所以这个时候要根据VMP加密后的指令段的范围,来判断目标地址是否是真实跳转,或者是用来衔接的跳转).
你可以想象,VMP把一整根香肠切成无数段,然后每一段贴上它原来下一段的地址,接着把无数段的香肠用撮麻将的手法洗成乱七八糟.最终,就是你看到的这些.
所以我们面对的第一个拦路虎就是乱序整理,也叫乱序重组.
乱序代码这个技术其实不新鲜,很多加密代码都有乱序的功能,把代码搞乱,搅合你的思维,打断你连续的逻辑建立,是个防止逆向分析很有效果的办法,以至于对付它也有成熟的理论.简单说就是牵着头,顺着JXX一直往下读就是了.
但是如果你遇到VMP的乱序代码,很不幸的,这个办法不奏效了.
盖因为VMP的乱序代码”衔接方式”中存在一种RET衔接, 我们在IDA中,顺着JXX和CALL双击下去,不用多久,就能找到一个RET衔接, 如下图.
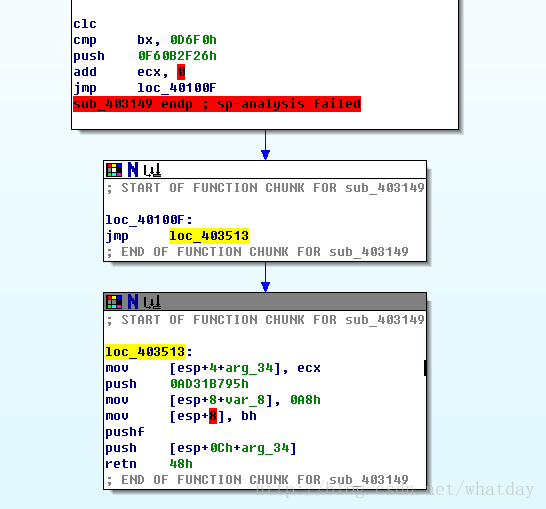
也就是说,本来是顺序的代码被分开之后,中间用一个RET指令作为衔接的.这个RET指令不是普通的PUSH IMM + RET,附近没有立即数可以确认RET的返回地址.也就是说,如果你用IDA分析到这,就基本上不知道接下来该去哪里了.(还记得之前的那个PUSH的KEY吗,这里的RET返回地址,就是从那个KEY计算而来的).
这是个很高明的办法,有效的阻止了逆向分析人员企图静态的读取指令完成乱序整理的目的.
(注:RET指令还有一个额外作用,为了平衡用CALL方式衔接或者是PUSH 垃圾指令带来的堆栈失衡.)
于是乎,VMP这种难度级别较高的乱序代码,要重组,必须用动态重组技术.简单说,就是写个虚拟机执行模块,把关键的RET的目标地址计算出来,配合静态读取,来完美的整理VMP的乱序代码.
文章写到这,有个问题出现了,写一个完美的虚拟机本身的工作量就是天文级,那我可能没等VMP逆向搞完可以直接去VMWARE工作了.所以基于节约劳动成本的角度考虑,我只能写个简单的虚拟机.
既然是简单的虚拟机系统,必然先将代码简化.那么现在是方案很清楚了,如下:
1. 静态读取当前地址开始,所有能读取到的代码,也就是一直读到RET为止,并且包含所有的JXX分支.直到所有的分支都被RET结束.
2. 开始对已经读取到的代码进行膨胀压缩.压缩到极限之后,计算出RET的返回地址.作为新的开始地址.
3. 跳到新的开始地址,重复步骤1.一直到所有的代码都处理结束.(最后一个RET的返回地址经过计算,已经跳出了VM的PE数据段).
方案确定了,很明显,这里涉及到膨胀压缩问题,由于膨胀压缩问题是第二章的范畴.如果只是读取目前所有能够读取的代码的话,乱序重组整体上而言难度不大.
在整个ZVM工程代码中,线程函数ReadInStatic是整个逆向过程的入口.
线程函数的Get_One_Segment函数,就是起出所有能够静态读取的指令列表.
如图,如果在185行下断点的话, list_InsCls变量就是读取了当前为止开始,所有能够读取的代码的列表,是个list):

如果把这个185行处的临时保存,改为全局保存,之后break出while,将会在”d:\\out.hex”处,生成到此为止获取到的指令(直接运行,out处填写0x00401024,然后点击read按钮).如下图:

下面这图就是保存出来的out.hex(在文档目录下的the-first.hex,以及同名的.idb文件)用ida打开之后的样子,可以看出是基本上已经顺序的获取到了ret之前的所有指令.如图:
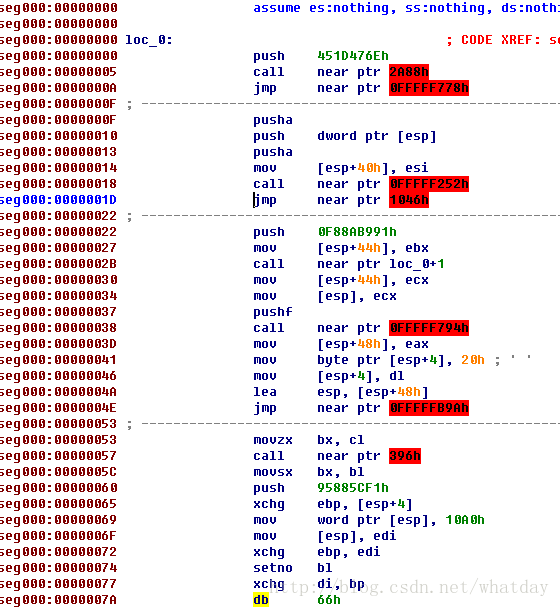
被函数Get_One_Segment处理之后的指令列表,其中的jmp函数基本上可以全部删除了.然后形成的是一条顺序的指令块,以方便后续处理, 附近函数内部的解释比较丰富,文章中也就不多说了,大家可以看看代码中是怎么处理的.用了STL,还自己实现了一个链表,可能看起来会感觉乱七八糟,见谅啊.-_-
185行往下一个while中,有函数PackInsList_UseRuleFuncs,这个函数就是压缩目前已经获取到的代码.这部分我们放在第二章说.
关于虚拟机的部分,第二章节结束后会说明,并且,到时候会举个例子作为实战,更好的理解VMP逆向到第二步的过程.
5. 开始还原 –X86膨胀压缩.
为了阐述的顺序性,和为了更好的调动大家的积极性,我先把效果展示一下,再仔细说明我是怎么做到的:
前一章,我们说到185行附近是读取一小块乱序指令,并将其整理.然后接下去的PackInsList_UseRuleFuncs函数,就是第一次应用规则压缩模式,进行指令压缩的模块.我们不妨先看下处理之后的效果,简单的办法就是,执行完成185行所在的if之后,立刻跳出循环,于是我们的代码修改如下:

在215行的时候,等待临时保存指令放入最终指令列表,然后跳出大while循环,并等待自动保存为”d:\out.hex”(文档目录下的the2.hex和the2.idb).
然后一样的,用ida打开这个hex,如下图:

这样一看,就有相当清晰的感觉.和the_first.hex对比一下,完全看不出是一样的代码,上图的代码,几乎已经是很可读的了.
(这里额外说一句,上图压缩解密出来的这一整个块的数据,实际上是相当于一个VM层的指令.下一个目标块,就是下一个VM指令的x86描述.)
这就是膨胀压缩的作用,把你首先获取到的代码,进行压缩之后,才能准确的分析下一步.然而你在代码中根本看不到下一步在什么地方.只是一个jmp ecx而已,当然不排除你实在很闲,手工计算过去.但是这种模块几乎可以说有几百万个.
要取到下一个指令块的地址,就必须动用虚拟机了.
之前我们第一章节曾经说过,工作量问题,所有的指令是无法全部虚拟的.我们的目的就是知道下一个块的地址,于是通过观察,不难发现,只要虚拟了几个逻辑计算指令,和一些内存读取指令,即可完成ecx的计算,也就能算出jmp ecx的目标.
虚拟机问题,放在最后再统一描述,因为虚拟机概念倒不是很难,这里开始重点的介绍,代码是怎么从the_first.hex变化到the2.hex的—指令膨胀压缩.
在讲述膨胀压缩过程之前,我想先普及一下指令膨胀这种技术的历史背景.
VMP所用到的指令膨胀技术,也不是一种新的技术,这种技术始于上个世纪80年代左右,第一个使用这种技术的是一款计算机病毒,所以这项技术有个很好听也很贴切的名字”多态变形指令引擎”(汽车人LOL…),这种病毒的终极技术原理就是,将某一条真实的指令所实现的功能,转变多条指令联合实现(或者反过来).其目的是为了对付杀毒软件的特征扫描.但是计算机病毒上的这种技术更为灵活一点,他们能做到动态变形.(即一条指令->多条,多条->一条,一条->多条….反复变形).关于多态变形的理论我并不想说太多,有兴趣的可以翻翻网上的文章,和去那个著名的病毒网站VX下载一些DEMO来玩.(注意安全,O(∩_∩)O~.)
VMP对这种技术的应用,可以说达到了炉火纯青的地步,因为VMP对于X86层,和他自己的VM指令层,都采用了膨胀指令技术.和病毒使用这项技术注重还原再膨胀不同.VMP只关注膨胀一个方向(这也是为什么我称其为膨胀,而不是变形),而且将膨胀这种行为应用到几乎就是不可逆的高度.因为VMP不仅仅对指令本身的行为进行高强度的拆分组合,更是融入了逻辑代数学上繁复的算法,对逻辑计算指令进行了数学上天花乱坠的分解化繁.
(注:有逻辑代数参与的指令膨胀,仅出现于VM指令层.X86层是不存在的,仅当1.70版本或者之前)
我们通过几个例子,来直观的说明一下指令膨胀的概念:
//pushGv
//ret
//=>
//jmp Gv
Gv的意思是32寄存器(同样的如果是Gb就表示8位寄存器,Gw表示16位),Gv这些标称取自Intel的IA32手册.没接触过的不妨下载一份观摩下,没时间的也无所谓,基本上之后的看见的部分,我都会讲解下意思.
两部分指令用”=>”符号隔开,上下是同样功能的指令(包括其对标志位,对上下文都一样).其中上面部分的指令,都是不太直观(或者叫故意膨胀,变形过的),而下面部分的指令,是我总结出来的精简指令.
所谓膨胀指令,就类似于这样,将一个Jmp Gv,膨胀为两条指令,多举几个例子:
//PushGv(A)
//PopGv(B)
//=>
//mov Gv(B), Gv(A)
//pushIbv
//popGv
//=>
//mov Gv, Ibv
这两个比较好理解Push+Pop实际上等于Mov. Ibv的意思是立即数,可能是8位(Ib))或者是32位(Iv)的.
//PopGv(A)
//PushGv(A)
//PopGv(A)
//=>
//delpop1
//del push
这个规则比较奇怪,如果POP,PUSH,POP三个连续,操作的都是同一个寄存器,可以删除前面两个指令.
实际上这几条指令并没有字面上的这么简单.或者说,VMP不一定会产生这样的膨胀,这些膨胀很可能是我压缩的过程中,产生的随机指令,但是产生这样的随机指令,然后二次压缩,比一次性压缩到位要好.(简单的说就是,你开车从北京到香港肯定很花时间的,但是如果有飞机,哪怕不是直达,飞两次,也比开车省事).
//push
//lea esp, [Gv]
//=>
//del push
//lea esp, [Gv]
这种是如果覆盖ESP,那么之前的PUSH都是无用的.
这么几个是ZVM引擎中摘录出来的,能代表膨胀的一些例子,这些是VMP使用的,但是你可以看到,这些例子非常少,并不是我找不到,事实上,我一开始找到了非常非常多的膨胀规律,然后写了非常非常多的压缩规则.但是越到后来,越发现一个问题.
当我用压缩规则挨个压缩VMP的膨胀代码的时候,压缩过程中,产生的新的代码,和旧的或者是新的代码,组合在一起,又生成了新的膨胀规则.
于是我意识到不能简单的看到一个膨胀规律,就企图将其压缩,我花了点时间,研究了VMP膨胀的所有手法.找出了其中的10几条明显的规律,总结为X86层压缩规则.(总共就用了10几条规则,把前 X86层给压缩的干干净净,这比一开始乱来要舒服的多了)
我们之前看到的几个,是仅有的几个明显带有压缩倾向的规则,实际上我设计的大部分压缩规则,都是替换和加工处理的.上面列出的规则,只是给大家理解膨胀代码有帮助.
这些规则都存在于引擎源代码 – Zvm_X86Pack.cpp中
不过在你马上打算阅读它之前,我得给你事先说明一下代码所用的编程思路.以及阅读之前要掌握的一些信息:
要分析VMP,必须有个很恰当的方法.通过前一章节,我们知道分析之前,要先把指令乱序整理,由于第一章还未完成,所以这里暂时当做我们已经完成了一部分指令的整理,现在手头拿到的,是一串顺序的VMP加密指令.
为了实现这个架构,我写了几个模块:
1. 必须有一套反编译系统.能够清晰的掌握每个指令的细节情况.
2. 连串指令的保存和遍历,删除,插入等操作.
3. 设计一套用于方便增减规则的模块.以方便规则的自定义.
上面的每一点,都稍微解释一下.
首先分析代码,肯定需要一个反编译引擎,这个反编译引擎不用很强大,只需要把给定地址的指令长度,以及OP和MODRM,SIB区分出来就行了.
我一开始选择用XDE引擎,这个引擎被很多乐忠于做多态分析,以及垃圾指令清扫的技术员喜欢.
关于这个引擎的功能细节也不在讨论范围内,我第一次得知这个引擎,是SoftWorm的文章.有兴趣的可以搜索下前辈的文章,有比较多的介绍.
XDE放编译引擎是在ADE引擎上修改来的,主要功能就是截断每条指令,并且分析指令所用的寄存器以及该指令的其他特性(比如是否设置标志位等),用一些DOWRD的ENUM值来直观的显示.相当于是在反编译的基础上,给每一条指令归结了属性,方便分析使用.
用XDE来分析和做代码处理.我很快发现了XDE的先天缺陷. ---- XDE太粗糙了.
并不是说XDE有错误(实际上bug也有,但是在ZVM引擎中附带的那一份XDE,其中的几个bug 我已经修复),而是XDE概括的指令属性,并不是非常完美,相反,如果依赖其归纳的属性来做分析,那反而会造成判断上的一些疏漏.(简单说,也就是反而需要考虑更多东西).
所以用粗糙来比喻,做VMP的X86指令还原,是绣花针的活,XDE则是一根鞋带.明显是不对付的.所以我就用了XDE指令中,对指令进行分块以及MODRM,SIB分解的功能.所有的指令属性(比如用了哪几个寄存器,多少位的),都是直接对比的.为此我研究了不少Intel的文档,并且在墙壁上贴满了图表和文档摘录(Prison break风格…).
例如:
bool Is_GvGv_ModrmAndSib(Ins_Cls * ins, unsigned charmodrm_reg,unsignedcharmodrm_rm)
{
if
(
GetModFromModrm(ins) ==MODRM_MOD(11)&&//直接寄存器模式
GetRegFromModrm(ins) ==modrm_reg&&//Gv用户指定
GetRmFromModrm(ins) ==modrm_rm//Ev用户指定
)
{
returntrue;
}
returnfalse;
}
这个函数实际上是对指令的MODRM和SIB做检测,判断其是否是Gv,Gv风格的指令,比如说 Mov Gv,Gv, Add Gv,Gv…..
bool Is_GvEv_ModrmAndSib(Ins_Cls * ins, unsigned charmodrm_rm)
{
if
(
GetModFromModrm(ins) !=MODRM_MOD(11)&&//除了直接寄存器模式
!(GetModFromModrm(ins) ==MODRM_MOD(00)&&GetRmFromModrm(ins) ==MODRM_RM(101))//不支持直接寻址[12345678]
)
{
if(GetRmFromModrm(ins)!=MODRM_RM(100) &&GetRmFromModrm(ins)==modrm_rm)returntrue;
if(GetRmFromModrm(ins)==MODRM_RM(100) &&ins->stk_InsXdeInfo.sib == (SIB(00,100,000)|modrm_rm))returntrue;
if(GetModFromModrm(ins)==MODRM_MOD(00) &&
GetRmFromModrm(ins) ==MODRM_RM(100) &&
ins->stk_InsXdeInfo.sib == (SIB(00,000,101)| (modrm_rm << 3)))
{
return true;
}
}
returnfalse;
}
而这个函数写的复杂点,其实功能是差不多,也是确定某个指令是否是Gv,Ev模式,比如Mov Gv, Ev, Add Gv,Ev.这里的Ev指的是[Exx + Iv]这种.
有了诸多这类的函数之后,就可以写指令判断函数,例如:
bool Is_PopEvAddIbv(Ins_Cls * ins, unsigned charmodrm_rm)
{
if
(
ins->stk_InsXdeInfo.p_66== 0 &&//无位模式
ins->stk_InsXdeInfo.opcode==OPCODE(POPEv,0x8F) &&
Is_GvEv_ModrmAndSib(ins,MODRM_REG(000),modrm_rm)
)
{
returntrue;
}
returnfalse;
}
该函数判断了某一条指令是否是 POP [Exx + iv]
这些是指令判断的基础,基于XDE引擎完成.
我采用一种叫做规则套用的办法进行压缩.就是:
1. 写多个规则;
2. 从第0个指令开始,以1个指令为递增,到规则库中,对所有的规则做硬性匹配,一旦某个指令串符合规则.就将这个指令串剔除(或者替换为相应的处理后的指令串).
3. 当一轮对比完成后,判断本轮是否是否有进行过处理,如果有,重复执行第二步,否则结束压缩.
这个办法的好处是,架构简单,编码容易,坏处就是计算量比较大.因为大量的重复匹配浪费了太多CPU时间.但是这是我能想到的最简单的办法.
由于一开始设计的时候,采用LUA脚本的方式来扩充所有的规则(Rule),但是后来发现效率极其容易成问题(就目前用纯粹C方式建立的规则调用,都是极为耗时).
但是由于C设计的规则模式对于扩充等没有太灵活的办法,所以我设计了一套从导出表来自动获取规则函数的办法.
也就是说,所有的规则函数,实际上都是特定名字的导出函数.由引擎加载之后,搜索自身的导出表,确定函数的类型,添加到规则处理函数库中去.
直接观察ZVM的exe,也可以看到导出表被清晰的分成了几个类型.这几个类型,实际上就是以规则扩充为原型的压缩办法的几个规则库.如下图,ZVM.exe的导出表:
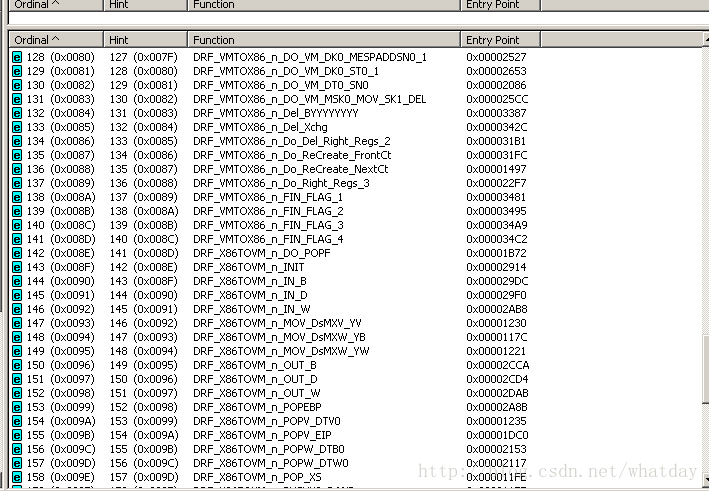
这样一来,我就不用频繁的修改引擎函数来对增加或者减少的规则做处理了.也能直接用C对规则进行扩充,速度和方便性都处于一个不错的平衡.
关于导出表管理规则的模块,具体的代码处于函数Get_All_DRF_Func和Get_DRF_FuncName中.
也就是一句话说 ---- ZVM压缩还原VMP,原理,其实就是建立在这套规则库的想法之上的.准确的说,一共有4套规则库,分别是:前X86层压缩规则库,前X86层翻译VM指令规则库,VM指令压缩规则库,VM指令翻译后X86规则库.
之前说过了,前X86压缩部分的规则库,存在于: Zvm_X86Pack.cpp文件中.
在该文件的573行左右,开头以” DRF_RULE_FUNCTION”定义的函数,均为前X86压缩规则函数,规则函数是个导出函数宏.有两个参数,第一个参数是个数字,用来表示规则的优先级(0-9,9最高级),第二个参数是描述了该规则的名称.不同的规则有不同的命名方式.用不同的宏来区别.
在573行之前,都是附带的一些支持函数,第二章上面的部分,描述了部分,其他可以自行理解.
这部分规则函数的调用和执行,在函数PackInsList_UseRuleFuncs统一进行.
6. 开始还原 –前X86(压缩后)转为Vm指令
这一章本来要说的是虚拟机部分的,但是我读了下代码,发现虚拟机部分实际上是和前X86指令转为VM指令配套的,所以这两个部分可以一起来写.放在稍后表述.
之前说到, GUI_ZVMDlg.cpp的185行左右,是处理读取一块(一条VM指令描述)指令,并且压缩的过程.那么在此处往下一点.215行,到236行部分,就是将压缩后的指令块,进行登记处理,以方便后续识别工作.
236行之后的代码,开始进行识别,看看这块指令到底是对应的什么VM指令.同时,对这块指令进行虚拟机运行.计算出下一块指令的地址.
这里识别实际上用到了我们第二套的规则库, X86ToVm_UseRuleFuncs,这个函数所管理的X86指令转为Vm指令的规则库.规则库的调用无任何好说的,直接跳到规则库的定义文件:Zvm_X86ToVm.cpp
这个文件的705行开始,开头是DRF_X86TOVM_FUNCTION(5, INIT)的函数,就是前X86转为VM指令规则库.其中DRF_X86TOVM_FUNCTION(5,INIT)比较典型,包含了比较多的信息.
这里可能要顺便介绍一下VMP的VM指令系统,我不知道其他VM软件是否和VMP一样,VMP定义了一套非常非常少的VM指令系统,如果认真的归结起来,把init,ret,encode等很少使用的指令都算上,只有18种,够精简的(详见Zvm_VMINS_VMP1_7.h文件的145行开始).所以前X86到VM指令的识别规则库,这部分代码不会很多,因为统共只要识别18个指令就够了.
(注:但是由此引申出的伪VM指令,却高达上百条.至于这些真假VM指令,是后续文章的概念,这里提前说明,让大家有个概念.)
整套VMP的虚拟机系统,和TMD差不多.
使用EBP作为VM_ESP指针.(堆栈指针).
使用ESI,作为VM_EIP指针.(指令指针).
使用EDI,作为VM_CONTEXT指针(所有VM机的寄存器都在类似于堆栈的内存中,靠这个指针访问).
于是我们再次观察the2.hex的ida显示.我对代码做出了如下的注释:
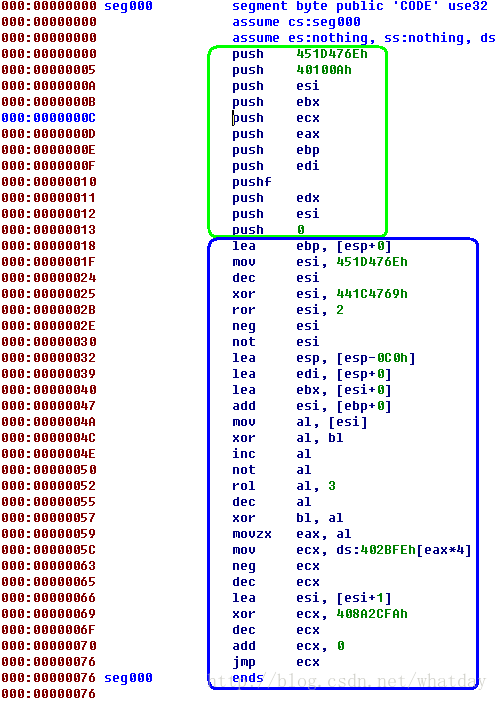
重点1:
图中蓝色部分的作用,是递增VM_EIP(注意,这里描述带了VM_开头,表示的是VM机使用的寄存器, 实际上是ESI寄存器,以下不再解释),在00000066处可以明显看到VM_EIP的递增.
至于之前0000001F处,也可以看出VM_EIP被赋值,然后通过解密,这里也能看到,VM_EIP实际上,就是从一开始的PUSHDWORD的那个KEY算得来的.
另外说明一下,每个块的末尾差不多都有这么一段类似的指令,用来递增VM_EIP,但是由于这是第一段指令,VM_INIT指令,所以这部分的动作更多点,但是大体上,处于蓝色部分之前的,都是指令本身的含义,蓝色部分,是VM_EIP递增,这个没错,首先要建立概念.
重点2:
依然是蓝色部分,00000018处,是设置VM_ESP,在所有外界寄存器入栈之后(VM的堆栈).马上把这个地址赋值给VM_ESP,这样就可以在堆栈中访问,并处理物理机器的寄存器了.
至于VM机自己也需要用到堆栈来处理一些代码,那么00000032处的代码,将物理机器的ESP寄存器,向上退了0xC0个字节,这个就是临时堆栈了,这个堆栈的大小可能会改变,取决于代码的复杂度.00000039处,这个内存的地址,马上就赋值给了VM_CONTEXT指针.
重点3:
绿色部分实际上是物理机器的一些寄存器进入VM机的堆栈,刚才已经说过了,这里要说的是:
VM机一共有15个寄存器(在下面的代码中,我将它们称作VR0-VRF,Virtual Register,另外还有个标志位寄存器是VFL),存在于VM_CONTEXT指针管理下.当绿色的这部分进入VM堆栈之后(个数不定,但是一般都是12-15个,因为物理机的寄存器数量是确定的,不会小于8个,加上固定的一些值后面会说到,和参与计算的指针等).接下来几个VM机指令,会挨个将VM堆栈中的数据弹出,放入到VM_CONTEXT中.这部分后面会说到.
说到这里,相信这个块大家已经有了个大概的理解,那么我们来看Zvm_X86ToVm.cpp的705行的函数DRF_X86TOVM_FUNCTION(5,INIT),就是用来识别这条VM指令的,这个VM指令我记为VM_INIT.VM_INIT仅存在于进入VM虚拟机的时候,执行一次,之后不会再有这条指令了,当VMP跳出自己的虚拟机,再次进入的时候,才会再次见到.
这条指令的识别规则是
//LeaVM_USE_ESP, [esp]
//movVM_USE_EIP, [esp]
//LeaVM_USE_CONTEXT, [esp]
//=>
//VM_INIT
这里的意思是,当顺序出现以上这三条指令(经过我们的压缩处理过后)的指令块,肯定就是VM_INIT无疑.
这个函数接下去的代码部分,就是做这些识别的具体操作的.
值得多说两句的是几个函数:
GetFront(),获取当前指令块内,第一个指令.(VM_INIT中,用来判断是否为PUSH立即数,因为VM_INIT肯定是以这个为开头的).
GetNextIns_UseSet(),获取当前指令块内,指定指令之后,含有指定属性的指令.(VM_INIT中,用来寻找第一个使用了VM_ESP的指令,是否为Lea VM_USE_ESP, [esp] .
弄懂了怎么识别出VM_INIT之后,可以继续的琢磨一下剩余的识别规则.这样,在读取到其他代码块的时候,就能有个比较直观的了解了.接下来进入重点.虚拟机执行.
终于到虚拟机执行了.依然是DRF_X86TOVM_FUNCTION(5, INIT)这个函数中,函数RunVMachineMini_UseRuleFuncs的作用是,将当前块,放入虚拟机执行,以便跑出下一条地址.
这里允许调用RunVMachineMini_UseRuleFuncs必须是已经识别出VM_INIT指令了,这样可以保证,无法虚拟的指令都清理干净了.
代码的目的差不多都已经明确.虚拟机原理,是存在于函数RunInVMachine部分,简单说就是,保存上下文,执行,然后获取执行之后的上下文,当然要对某些指令进行一些处理,比如读取内存的函数,因为毕竟是静态逆向,直接读取内存是当前exe的地址.而不是目标exe的地址.关于虚拟机部分的代码,我看着并不复杂,大家有兴趣可以多花点时间研究下.或者自己实现一个也是很容易的.
当虚拟机运行结束之后,会返回下一个指令块的开始地址.
于是我们可以重复的读下一个取指令块,然后压缩下一个指令块,压缩完成之后,识别下一个指令块,最后再次进入虚拟机.如此循环下去.一直到读取的文件,到达了设定的OUT(程序界面上的EDIT设定)标定的地址.整个读取工作,算是完成了.
到了此处,经过了虚拟机之后,基本上VMP逆向工程的第1,2两个步骤已经完成.写了20来页的WORD文档,其实只是稍稍揭开了VMP神秘的面纱.如果用比较确切的数字来衡量进度的话,大约是30%.
过了1,2两个步骤之后,我们就可以彻底的跳脱X86的防御,直接进入到VMP的核心,VM机指令层压缩的大幕即将拉开,VMP逆向中最为精彩的部分,我会逐一为大家呈现出来.要做好准备的是,进入下一章之后,最好在头脑中建立一个新的指令机器的逻辑空间,因为即将看到的任何描述和指令行为,都和现有的X86系统相差甚远.
7. 还原核心 – VM指令层.
同样的步骤,我先把一些软件应用的例子展示一下,然后再逐步的说明,其中包含的含义.已经本章要参数的概念.
首先我不知道大家拿到源代码之后,是否能够成功的编译出exe,我是用2008开发的这个GUI_ZVM工程.所以用2008编译比较好,基本上不需要改动什么.可以很顺利的编译出exe.连警告都被我干掉了.
唯独要注意的是,由于引擎用到了一个小虚拟机,代码是跑在变量中的,所以要关闭数据执行保护功能,才能正常运行,包括vc2008编译时生成的数据执行保护(DEP),和windows系统提供的数据执行保护(DEP).
然后你可以用Radasm照着我之前说过的方法,加密出一个目标exe.
接着打开gui_zvm.exe,填写目标exe的路径,以及要解密的vm代码的IN入口地址(如果你是按我说的方法加密的,那么这个地址通常就是test_vmp函数的地址,也就是0x00401000).OUT出口地址,暂时不用设置,因为我们暂时使用RUN方式测试,RUN会暂时读取到目前能够读取的所有代码.(有可能就直接读到出口地址了).这个区别取决于VMP的选项设置,是否要中途进行额外的处理.
设置完成之后,点击RUN按钮.经过几秒到几十秒(取决于机器速度)不等的时间,将弹出完成对话框,紧接着,大量数据填充了ZVM的调试器,截图如下:
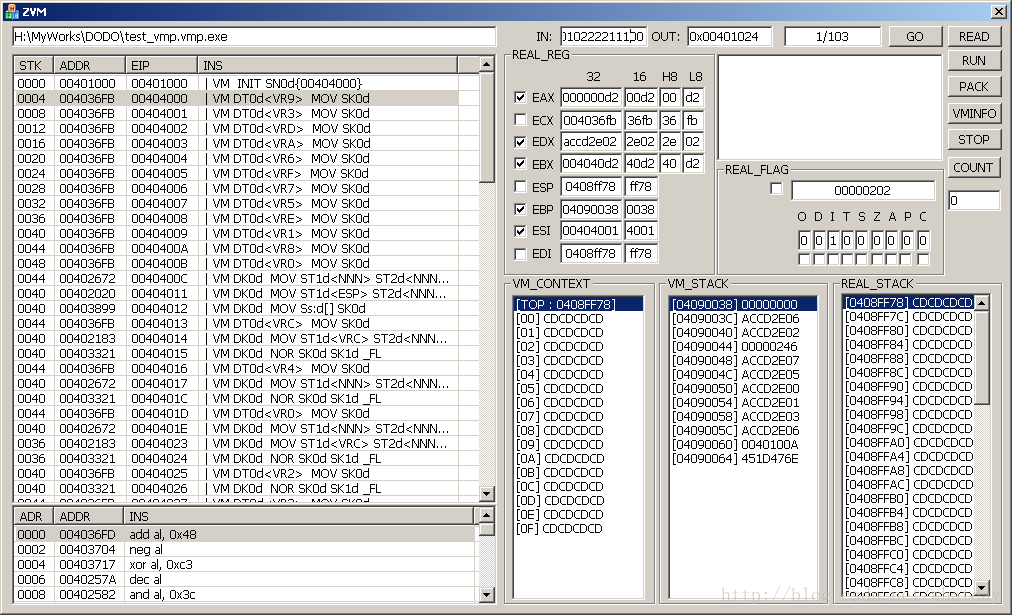
ZVM的主窗体界面,实际上是个调试器,这个调试器和一般调试器不同的地方在于,普通的调试器,一般只能够顺序调试,而ZVM的调试器,可以顺序和反序调试.也就是你可以反复的来回执行,来精确判断两条指令之间的细微差别.以达到精确分析的目的.这一点就是ZVM分析VMP的基础支持.
整个窗体界面分为左右两个部分.左边的窗体又分为上下两个部分.其中左边上面的部分,是ZVM识别出的VM指令的顺序列表.而左边下面的部分,是当选定某个VM指令的时候,这个VM指令的X86描述.
右边部分就是调试的数据输出的一些东西,其中寄存器和标志位,不多说了,都看的懂.唯一要解释的是多选控件,这个表示的是当前多选代表的数据,和之前一条指令相比,产生了变化(也就是OLLYDBG中寄存器变红的意思).
右边下面部分,三个列表,分别是,VM_CONTEXT上下文指针数据(TOP为堆栈开始地址,剩下的15个VM机寄存器),VM使用的堆栈数据,以及物理机器的堆栈数据.
在右边go按钮之前的edit框,表示了所有获取到的VM指令的个数,和当前VM指令所在的位置.
调试的办法,全部都是用键盘,没有鼠标操作.
(注意不要用鼠标,也不要把鼠标的焦点放在list中.最好把焦点,放在右边那个大白框里).
一共只有4个按键设置,分别是’1’,’2’,’上’,’下’.
其中’1’(向上),’2’(向下),是步进(步退)单个VM指令的作用(注意,单个步进VM指令的时候,寄存器和状态位,以及三个堆栈数据,表示的是该VM指令的第一条X86指令上的状态).
而’上’,’下’两个按钮,则用在,当你停留在某一条VM指令之上的时候,对该VM指令内的X86描述进行步进(步退)的操作.
除了这两个操作和调试器有关,还设置了’GO’按钮,可以直接的跳到某个VM指令的位置.
其他剩余的按钮,和当前调试行为无关,不要好奇去按他们,以免程序崩溃.(-_-)!
好了,介绍完一种ZVM的使用方法之后.暂时告一段落,大家可以试着先操作两下,熟悉下这么多古怪的数据是怎么回事,有个总体的概念之后,我开始解释.
前一章我们说到了,VM一共有18条虚拟机指令.分别是:
VM_INIT,
VM_RET,
VM_IRET,
VM_DK0_MOV_E,
VM_DT0_MOV_SK0,
VM_EIP_SK0,
VM_DK0_MOV_SMSK0,
VM_MOV_SK1_DMSK0,
VM_DK0_NOR_SK0_SK1_F,
VM_DK0_ADD_SK0_SK1_F,
VM_DK0_SHL_SK0_SK1_F,
VM_DK0_SHR_SK0_SK1_F,
VM_DK0_SHLD_SK0_SK1_SK2_F,
VM_DK0_SHRD_SK0_SK1_SK2_F,
VM_DK0_DK1_MUL_SK0_SK1_F,
VM_DK0_DK1_DIV_SK0_SK1_SK2_F,
VM_DK0_DK1_RAND,
VM_DK0_ENCODE_SK0_SK1,
这些定义在Zvm_VMINS_VMP1_7.h的145行开始的地方.这些名字很古怪,其实都是缩写.
这里有个总的概念:
VMP的VM指令,可能有多个源数据参与计算,这些源数据,可能是立即数(在代码中直接表示),可能是VM机堆栈数据,可能是VM机寄存器,也可能是VM机的flag.或者是他们的组合.
但是其目标数据,一般都只有一个(注意是一般情况,多个的也有,很少很少),要么是目标是VM机堆栈(把结果写入堆栈中),或者是VM机寄存器(把结果写入寄存器中),最多带有一个存储VM标志位的操作.
有了这个总的概念,我们解释下上面这18个原始指令中典型的例子:
VM_DT0_MOV_SK0: 该条指令,将VM机堆栈中的栈顶数据,弹出到VM寄存器中.
所有VM指令都和这条指令一样,用VM_前缀描述.
VM_前缀之后,跟着若干个下划线,每个下划线,表示一种独立的描述.
如果某个描述是以D字母打头的,那么这个描述实际上表示的是目标操作使用的资源,如果目标操是T字母的,一般表示寄存器,并且到指令翻译机时候会在此处标明,使用的是哪一个VM寄存器.如果目标操作是K字母的,那么表示是目标堆栈.
如果某个描述是以S打头的,那么这个描述表示源操作使用的资源,和目标操作一样,源操作使用的资源,也有T和K两种,除此之外,还多一种N资源,表示立即数(通常包含在x86代码中).
至于源操作资源,和目的操作资源的最后一个数字,没有什么明确的含义,大体上是表示先后出现的顺序,比如DK1_DK0,表示目标数据,第一个放入堆栈,第二个也放入堆栈的数据,并非是堆栈地址的1和0的位置.同理,ST0_ST1_ST2,表示第一个源操作是个VM寄存器,第二个,第三个源操作也是Vm寄存器.并非是VM寄存器的编号0,1,2.
所有带下划线的描述中间部分,就是指令主要功能的描述.例如该指令中的MOV.
VM_DK0_MOV_E : 该条指令的目标操作就是VM机堆栈,但是源操作是个E,这个E代表ST1_ST2_SN3三者联合的这种组合.
VM_DK0_NOR_SK0_SK1_F : 该条指令目标操作不解释了,源操作是两个VM机的堆栈数据, 并且这条指令末尾带着一个F,表示,该条指令计算的时候,需要用到之前计算后生成的标志位.(注,这条指令的目标操作并没有F设定,所以这条指令只是做逻辑计算,并不会产生目标标志).
VM_DK0_DK1_MUL_SK0_SK1_F :该条指令是比较典型的地方是,目标操作包含两个堆栈操作,由于两个32位的数字相乘会生成一个64位的大数(类似于x86中,结果是edx+eax),需要用到两个堆栈来保存数据.
介绍完几个比较典型的VM指令之后,要说的是,这些指令的名字,仅仅是为了方便编码而设定的,也就是名字本身并不严谨,不能完全诠释VM指令所包含的精确含义,于是在Zvm_VMINS_VMP1_7.h文件的424行之后,我借用了XDE引擎的设计思路,定义属性集合的方式,来比较精确的描述每个VM指令的含义.例如VM_DK0_MOV_E指令,定义如下:
{VM_DK0_MOV_E, "MOV", VMSET_K0|VMSET_STACK, VMSET_E|VMSET_STACK},
这条指令描述结构的第一个成员是指令名字的ENUM值.
第二个成员是字符串(用来显示到调试器上).
第三个成员是目标操作包含的内容,例子中这条指令,使用了堆栈K,并且只使用了1个堆栈,所以只有K0.凡是使用了VM机堆栈的,那么这条指令在该方向(目标或者是源)上,都将包含一个VMSET_STACK标记,用来作为记号.
第四个成员是源操作包含的标记.其中VMSET_E标记是几个标记的集合宏.
剩余的指令也是同类的处理方法,大家可以自行观察.
预备信息已经差不多完毕,这里之后将开始说明如何总结出这些指令的规律,以及另外一些VMP的VM机运行过程的原理.
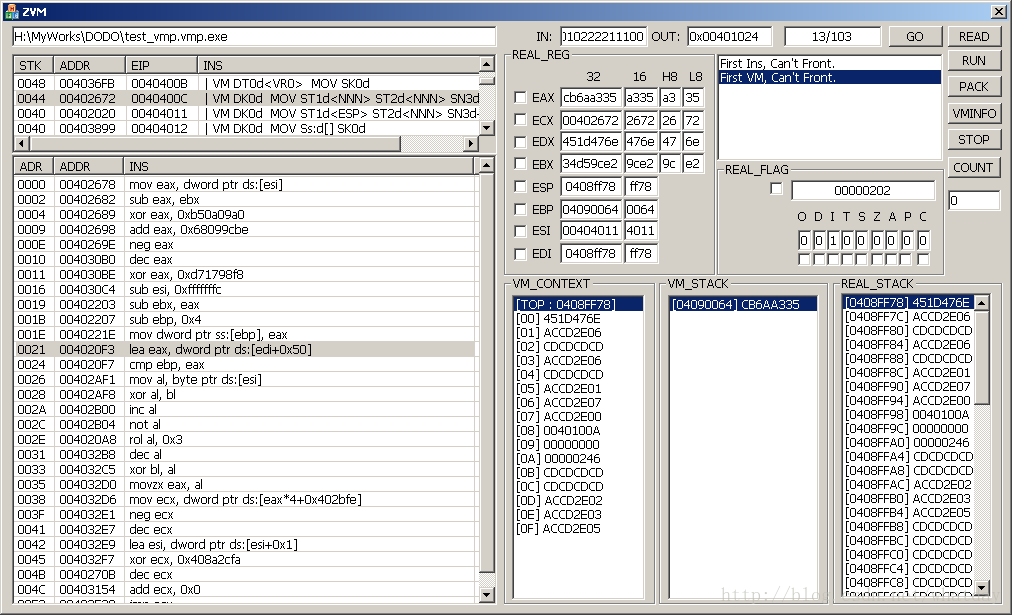
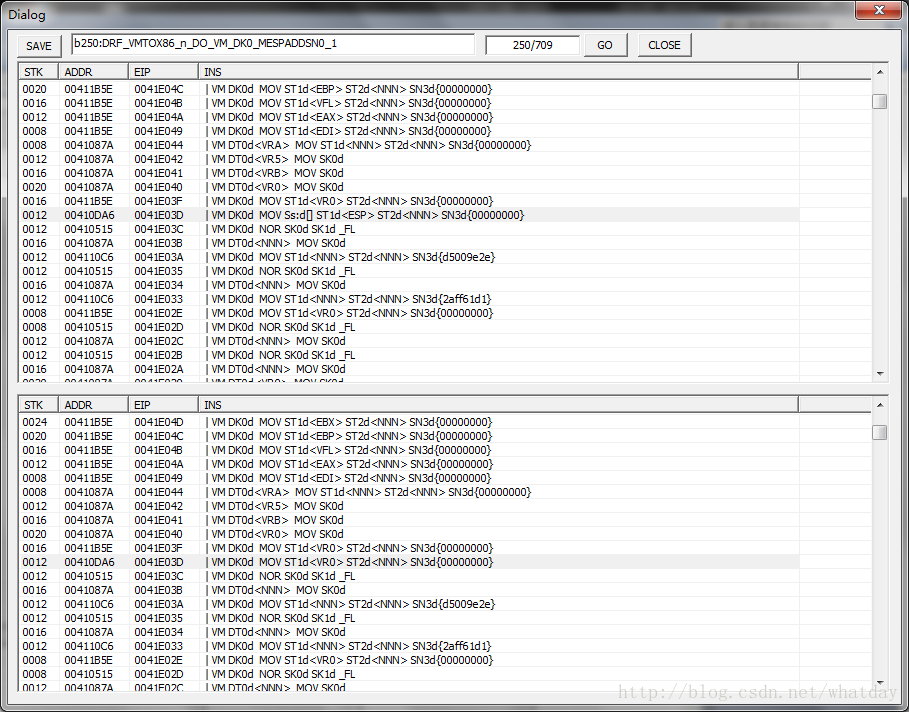
如果你是用我提供的exe进行分析的,那么你将看到的过程和我贴图和描述的过程是一样的,如果不是,大部分情况下是大同小异的.当我们”RUN”完成之后,会产生大约103个VM指令(这些指令有可能是我们测试用的那个asm的xor的全部指令,也有可能只是一小部分目前能够获取到的指令).这个时候按’1’.将执行VM_INIT指令,可以看到VM机堆栈数据已经被物理机器的寄存器等数据填满
由于这些物理机器的寄存器数据都是通过ZVM内部虚拟机模拟出来的,所以物理寄存器数据被设定为0xACCD2E0X,X代表了Exx寄存器对应的数字编号,物理标志位被设定为0x0000024,有兴趣的可以去观察VM_INIT,找出对应编号.
好,跳过了VM_INIT指令之后,是一条VM_DT0_MOV_SK0指令,但是在调试器上显示的有所不同,区别在原先3个字符表示的操作助记符(ST0,DK1等)改为了4个字符,这最后一个字符,实际上是大小的表示,(b=byte,w=word,d=dwrod).另外就是,在某些助记符之后带有<>框住的内容,为具体应用到的某些项,比如当前VM_DT0_MOV_SK0这条指令的DT0使用的是第9个寄存器,记做VR9.
继续这条指令,停在这条指令之上的时候,可以通过’上’,’下’按键,对该指令的x86描述,进行详细的查看.如上图所示.我们可以通过调试,把当前位置停在000E的地方.这条指令是add,ebp,4.
我们之前说过,VM_ESP寄存器,实际上就是物理机器的ebp寄存器.
所以仔细观察000E之前的一条指令,是MOV tmpreg, [VM_ESP],这是个弹出堆栈的操作.
000E的位置的指令,是退栈操作.
000E之后的那条指令,是mov, [VM_REG], tmpreg, 是把刚才弹出栈的数据,放入到VM机的虚拟寄存器.但是VMP这里耍了点猫腻,这个指令的EAX是经过计算的.所以我VM指令显示的地方那个VR9,是通过虚拟机运行而得到的数值(0x24 / 4).(注意,如果本来显示VR9这些的地方,显示了NNN的话.那么实际上就表示,没有使用到这个资源.)
再多看一条指令:
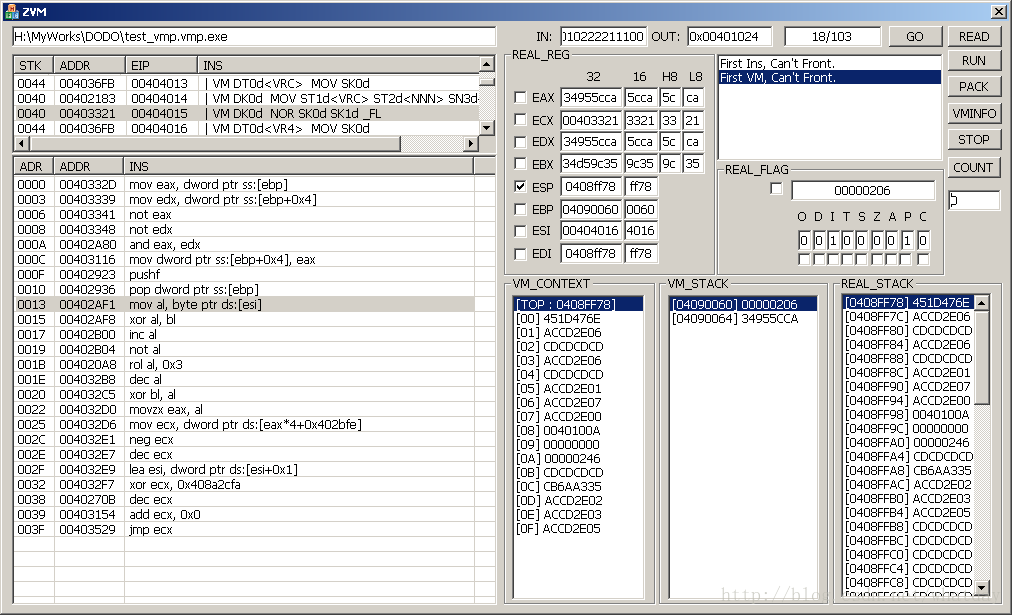
VM指令list部分,00402672指向的指令是VM_DK0_MOV_E,详细的输出是:

这个指令其实是把一个立即数入栈的操作,两个NNN表示前面两个ST资源都没有使用到,而SN却是有数据的.
我之所以把这个入栈的操作,定义为MOV操作,是因为这样将会减少非常多额外的定义(以至于只剩下18个原始指令),以方便今后的VM层指令压缩工作的简化(其实还是很麻烦…先天性的工作量大).
当这条指令运行完成之后(其实运行到x86描述的0021位置就可以看出了),立即数CB6AA335被压入到VM_STACK部分list的区域内.当然这些立即数,也都是通过虚拟机计算出来的,X86描述中不会直接的给出.
再来一条比较典型的指令:
VM列表中,00403321处的这条指令是NOR,在今天早先时候有个朋友在问我VMP相关问题的时候,说到NOR和NAND概念,但是我都以及忘记的差不多了,这里复习了下,顺便一起说明下,这些逻辑操作是x86没有的,但是在逻辑电路学中,应该都会有教到,其原理是NOR电路和NAND电路的硬件实现(与门非门这些搭配),远比xor来的简单(不知道是否是这样,就我所知,xor实现起来是非常麻烦的).
由于VMP的逻辑计算中,除了参加的AND(衍生指令),NOT(衍生指令),OR(衍生指令),XOR(衍生指令)之外,包含了NOR(原始指令),NAND(衍生指令),XNOR(衍生指令),所以其逻辑计算变得异常复杂!
但是有一点要注意,上面也说明了,就原始指令而言,VMP只有NOR一个操作,这点和TMD非常类似,至于为什么这些VM机都喜欢用NOR来作为组成逻辑计算的基础,这可能就要去看看逻辑代数(布尔代数)方面的文章了.如河蟹请爬墙.
在wiki百科上可以简单的查询到逻辑代数方面的一些公式.
我举出的这条指令的意义有两个.一个在于.NOR的实现方式,NOR = (~A) & (~B);
具体在x86描述中,可以清晰的看见,第1,2条指令,起初前一个指令留在VM堆栈中的两个数据,进行NOT,最后进行AND操作,写入到第二个堆栈中,并同时把计算后的标志位,写入到第一个堆栈中.所以可以看出,VM堆栈的操作,实际上并不是有顺序的,这只是对于x86描述层是这样.
这条指令的第二个意义是说明REAL_STACK,既真实机器的堆栈,使用到的地方就是在x86描述的0010地址处,这里借用了真实机器的堆栈,进行了操作处理.
你可以通过这条指令理解多个VMP的VM机操作的习惯.
如此,这些指令便解释了ZVM的运行原理以及操作方式,大家可以照着我阐述的过程,理解一下其他几条原始指令的行为,以及他们造成的效果.
当你动手理解了一会儿ZVM之后,下面我开始重点的说明一个全局性的概念.
首先,在ZVM经过RUN分析之后的103条VM指令,实际上只做一件事---那就是我们在radasm中写的XOR eax, ebx这一条x86指令的行为.
好吧.不要现在就惊讶,目前你看到的是最最简单的情况,因为我们在VMP的options页面,已经清空了右边多个选项(并且虚拟机个数还是1),这些选项的加入,将会对VM指令流造成天翻地覆变化.
阐述这些变化的概念,以及如何压缩这些VM指令流,我打算放在下一章进行讲述,但是由于本章的概念已经极其丰富,并且接下来的章节,对于逻辑思考和逆向能力都有很高的要求,考虑到不会有多人继续看下去,所以今后的章节,大体上成了一种学术范围的探讨.在彻底进入这种枯燥的,纯粹学术范围探讨之前,我希望把ZVM最精彩的一面–怎么还原告诉大家.
如果你已经学会了之前RUN方式使用ZVM的话,那么接下来的教学应该不难理解.
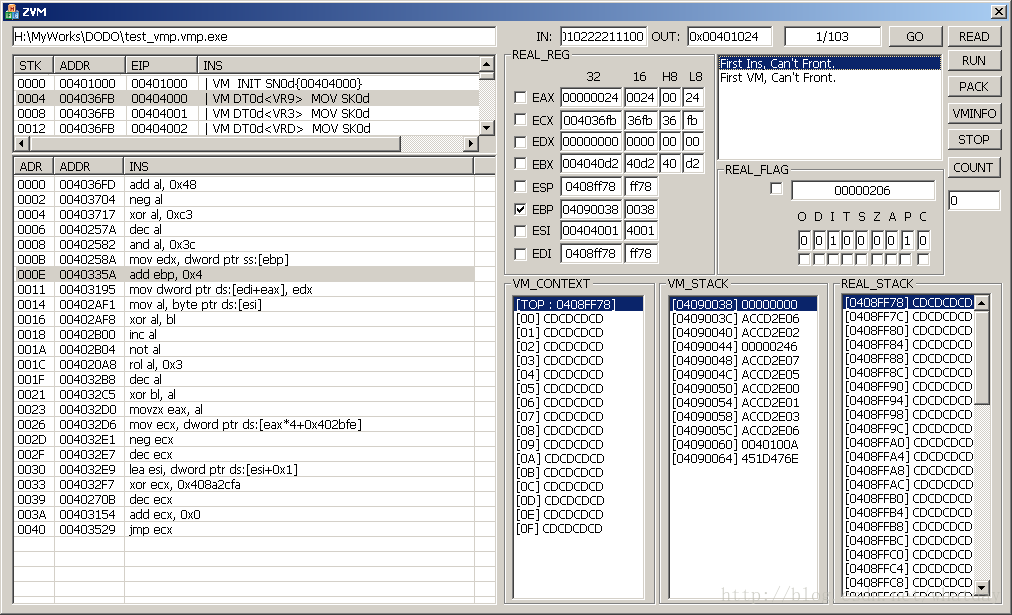
首先,关闭ZVM,打开ZVM,按照之前RUN方式的设定,一样的设定.OUT处,标定代码的出口地址(用本文档自带的test_vmp.vmp.exe的话,是0x00401024)接着,不是点击RUN按钮,是点击”READ”按钮,如果不出意外,将会出现如下图提示对话框:
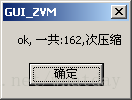
点掉这个对话框,ZVM界面毫无变化,因为使用模式,是解密模式.所以不会提供细节调试,只提供压缩过程的步骤显示.
当你完成READ操作之后,点击VMINFO按钮,将跳出另外一个对话框.如下图:
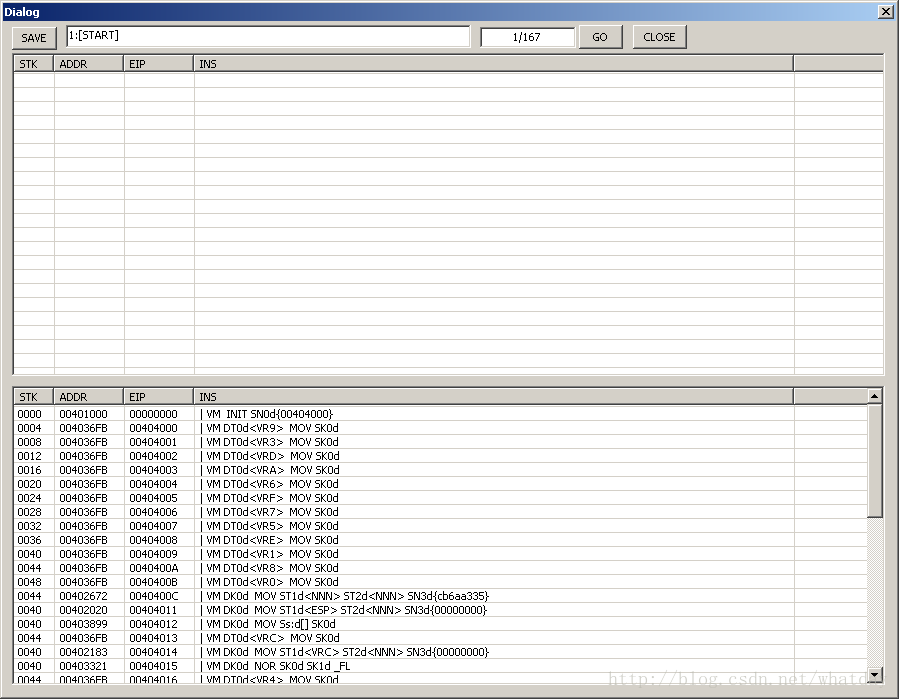
这个对话框分为上下两个部分,上面的部分,其中最上面,存在一条栏,其中,GO按钮之前有个EDIT,显示的是一共进行了多少个压缩步骤(可能和之前对话框弹出的不一样,并且可能会变化,这个是我代码处理不够严谨,但是无关紧要).
这里的167说明了,刚才那103个VM指令流,经过了167个压缩步骤,那么他到底被压缩成什么了呢,你可以通过按键’1’,’2’来每一步的观察,每个步骤,光标停留的地方,就是当前步骤压缩的地方,并且在SAVE右边的那个很长的EDIT中,将显示,使用的是哪一个规则.
如果你没有耐心观察,或者只想知道答案的,将GO之前的那个EDIT清空,输入167,然后点击GO,直接去到最后一个压缩步骤.这里显示的,就是最后一步压缩的结果,如果是正确的,说明VMP加密的代码,还原结束,否则,就说明软件存在BUG,无法通用处理.
当你停留在步骤167的时候,可以点击界面上的save按钮,将会在D盘根目录生成AFT_和BEF_两个标识开头的VMT文件.用记事本打开,就是当前窗体对应的两个LIST框内的内容,如下图
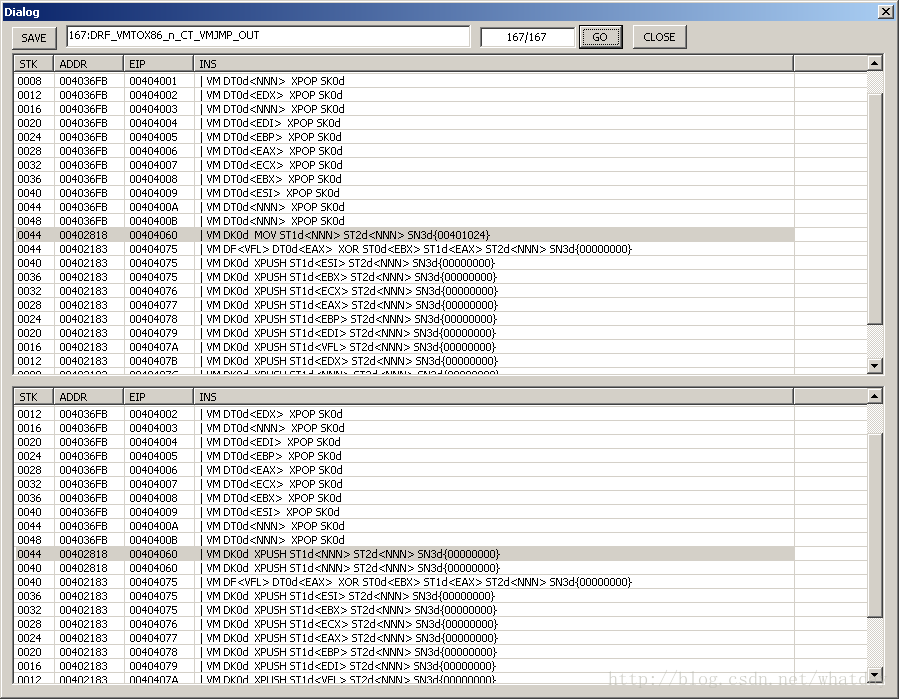
AFT_开头的文件是最终解密数据,打开之后,除去X开头的指令(XOR不算X开头,XXOR才算,但是没有XXOR),是上下文保存用,以及初始化和返回用的,整理后的代码如下数据如下:
0040 00402183 00404075 |VM DF<VFL> DT0d<EAX> XORST0d<EBX> ST1d<EAX> ST2d<NNN> SN3d{00000000}
漫漫长路到此终于拨开云雾,不知道你们看到这条指令的心情,和我当初第一次见到它的时候,是否一样.我很激动.但是今天将他呈现在世人眼前,我的心情又是另外一番不能言表的感觉.
当VMP第一次被我擒服的时候,那种成功的喜悦有点让我对自己的能力产生了过分的高估,以至于我陆续投入了半年多时间进行改良,最终还是没有弄出完整版.这一点是我的遗憾.
说跑偏了,呵呵,这条指令就是最终解密出的指令,它告诉你,这是一条XOR指令,并且参与计算的是两个寄存器,EBX,EAX(先后顺序颠倒没关系,目标寄存器会告诉你,哪个在前),都是32位的(因为资源标记的第四个字符是小写的d),并且目标操作数是EAX,带有DF位表示更新了标志位.所以这条指令,就是清晰无比,任何细节都已经关注到的:
Xor eax, ebx
指令!!
8. 终章 – VM还原的核心秘密
上一章结尾描述了一个最为简单的ZVM解密程序的范例.就如同上述说说,最简单的情况没有任何意义.但却是必须经过的一个过程.我们必须通过一个更为复杂,甚至是最强的加密步骤,进一步的对VM解密这种技术做一个深入的讨论,以达到我将其展示核心细节的目的.
在解释之前,按照惯例,先对VMP最强的加密模式进行一个介绍.我们继续用上述的原始EXE作为子.
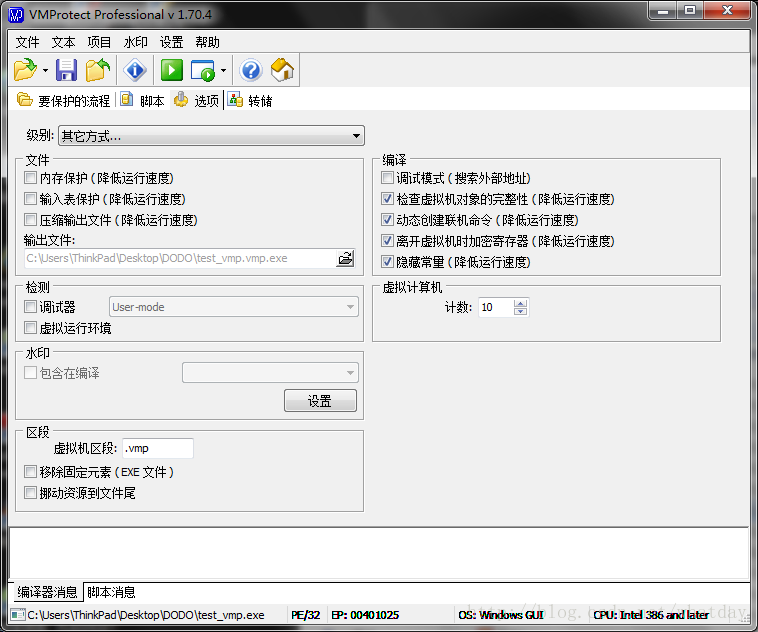
可以见到左边关于加壳的部分,可以全部不用勾选,右边加密部分除了调试模式,其他都可以设定,最后将虚拟机个数设置为10.如此加密后的目标代码,将会生成比上一章描述的10倍的VM指令(并且由于虚拟机设置为10,还将继续增大).目标程序的大小应该在90-140K之间.(文档目录下的test_vmp.vmp.all.exe就是,下述描述,均以这个exe为准)
而且如此加密之后,VMP对于其OPCODE层的加密,已经复杂至令人发指的地步,所有的技巧性应用,比如寄存器轮转,跨段计算,跳转的生成逻辑计算等,全部都在这里.开启ZVM引擎之后,用上一章的流程进行还原,可以很快得到结果(1分钟内, 取决于机器速度).
本章,就这些额外的反逆向措施,一一做一个简单的介绍:
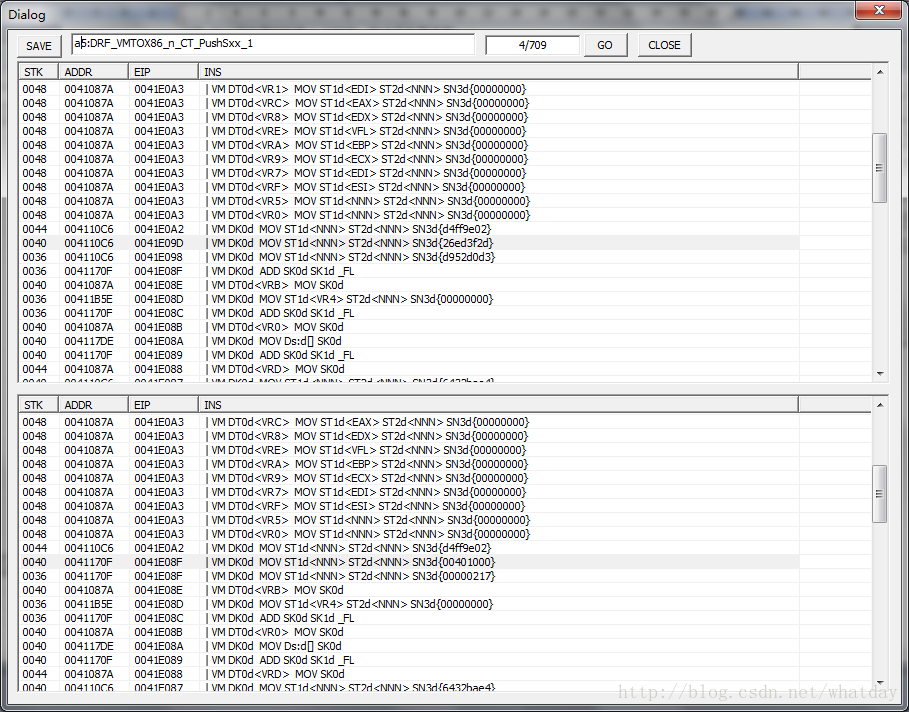
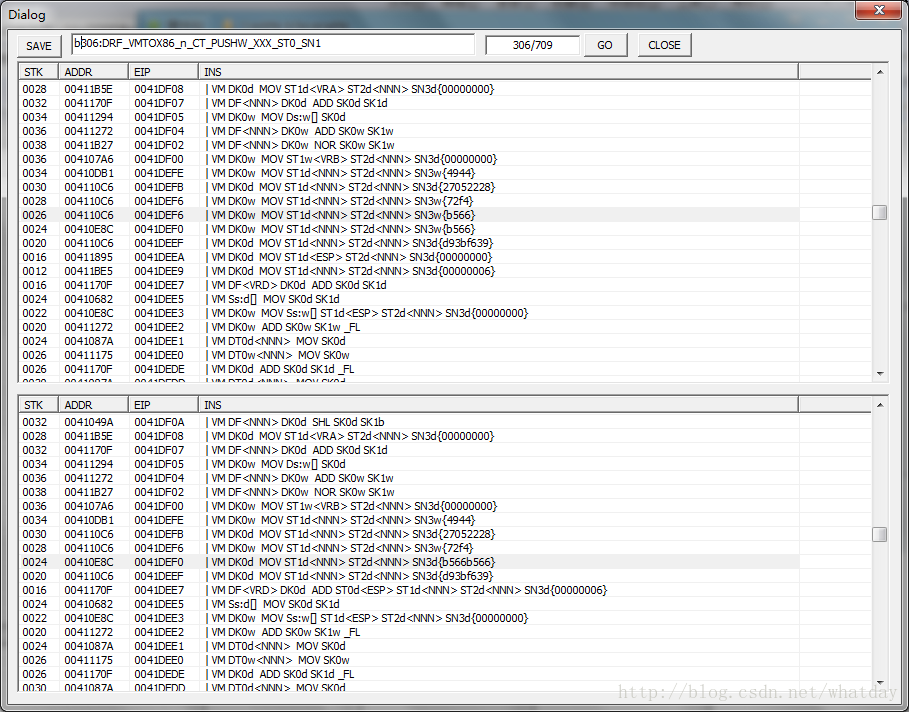
首先是看第4(或者是5)个压缩规则,注意高亮显示的两行,应用规则DRF_VMTOX86_n_CT_PushSxx_1反映了VMP对于计算和标志位的处理,当两个VM指令:
0040004110C6 0041E09D | VM DK0d MOV ST1d<NNN>ST2d<NNN> SN3d{26ed3f2d}
0036004110C6 0041E098 | VM DK0d MOV ST1d<NNN>ST2d<NNN> SN3d{d952d0d3}
00360041170F 0041E08F | VM DK0d ADD SK0dSK1d _FL
将两个立即数压入堆栈之后(堆栈中存在两个数),并开始计算两个堆栈数的和.放入第一个堆栈然后将产生的标志位压入堆栈.
这条规则经过处理之后,事先计算了两个立即数的值,并且将产生的标志位,一起压入堆栈,形成如下的指令:
00400041170F 0041E08F | VM DK0d MOV ST1d<NNN>ST2d<NNN> SN3d{00401000}
00360041170F 0041E08F | VM DK0d MOVST1d<NNN> ST2d<NNN> SN3d{00000217}
这点可以从调试模式窗口看出来:

继续下一个规则:
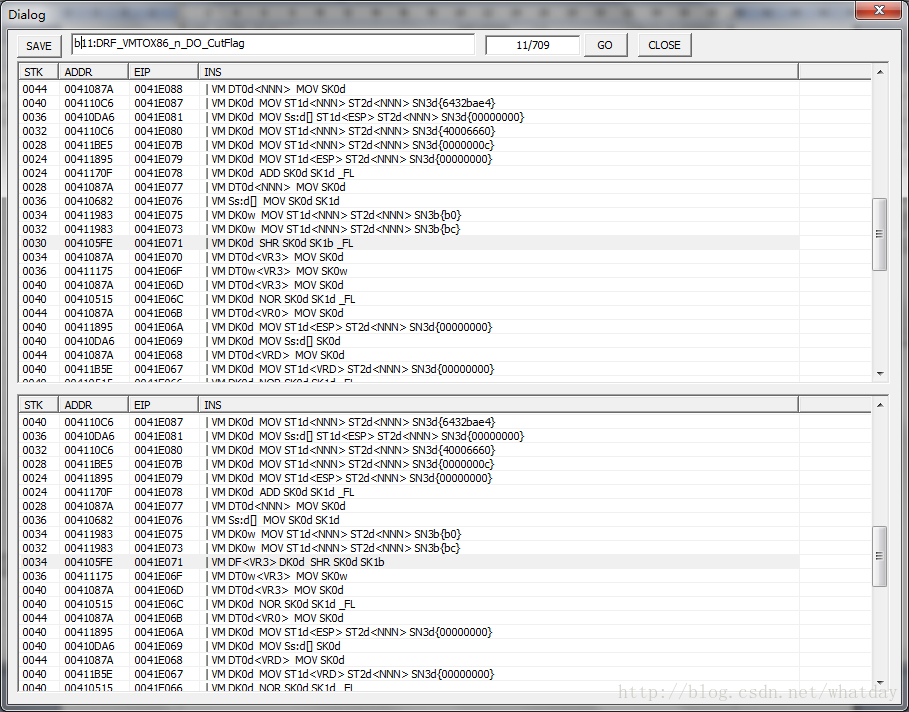
这条规则比较特别,解释下,把VR3整合为了DF(目的标志位).
继续:
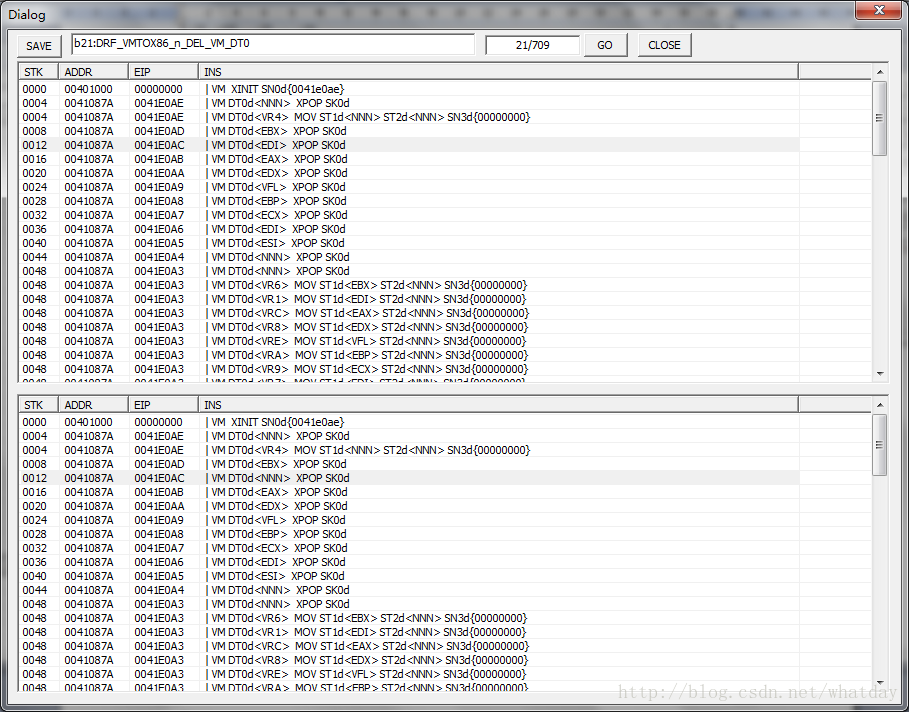
前一章说过,init指令是将所有的物理机器的堆栈压入到VM堆栈中,紧接着就是这些XPOP指令,把VM堆栈中的物理寄存器,弹出到VM寄存器中.但是我这里是直接把物理机器的寄存器给弹出了.可以看见XPOP的指令实际上目标寄存器用的是EXX.这样做的原因是,我可以通过直接带入物理寄存器的方式,压缩的最终结果,就是和X86非常类似的指令,而不需要再去做VM指令->X86指令的翻译过程.
值得说明的是,这里几个物理寄存器,是除了ESP之外的.ESP参与到VM机的工作中,在最终的时候得以还原,而不是用这种方式保存和还原的,这点和X86的PUSHAD和POPAD工作方式类似.
继续:
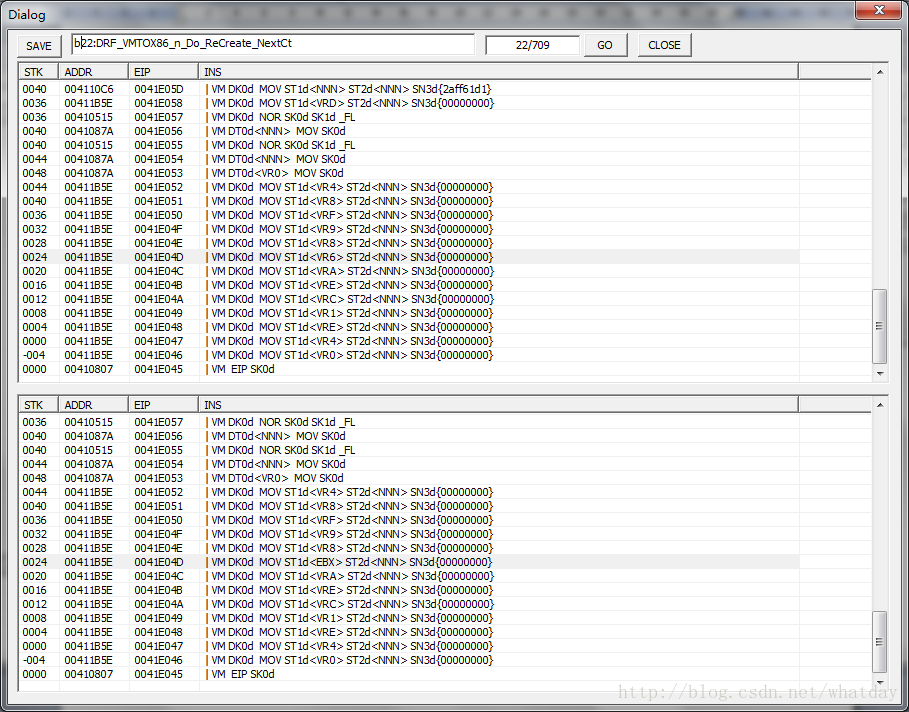
这条指令是接上面那个规则说的,你可以看到,被带入的物理机器的寄存器EBX,直接被带入到了这里.覆盖了VM寄存器的VR6.也正是因为如此阴差阳错的办法,ZVM引擎直接pass了寄存器轮转这个问题.
这条指令还有另外一个需要重点说明的地方,如图所示,你可以看到,最后一条指令是VM_EIP_SK0d,然而这里显示的并不是全部的VM指令.
相对上一章,我们不勾选任何反逆向措施的还原步骤来说,这里明显出现了个难题.这个难题似曾相识.
没错了,在你勾选了那些反还原措施之后,将会把VM指令流分块,而不是完整的给你.
这就形成了和我们之前处理混淆遇到的相同问题 – 你必须计算出到这里为止.下一步(或者是下一块)指令的EIP,否则,不能继续.
继续:
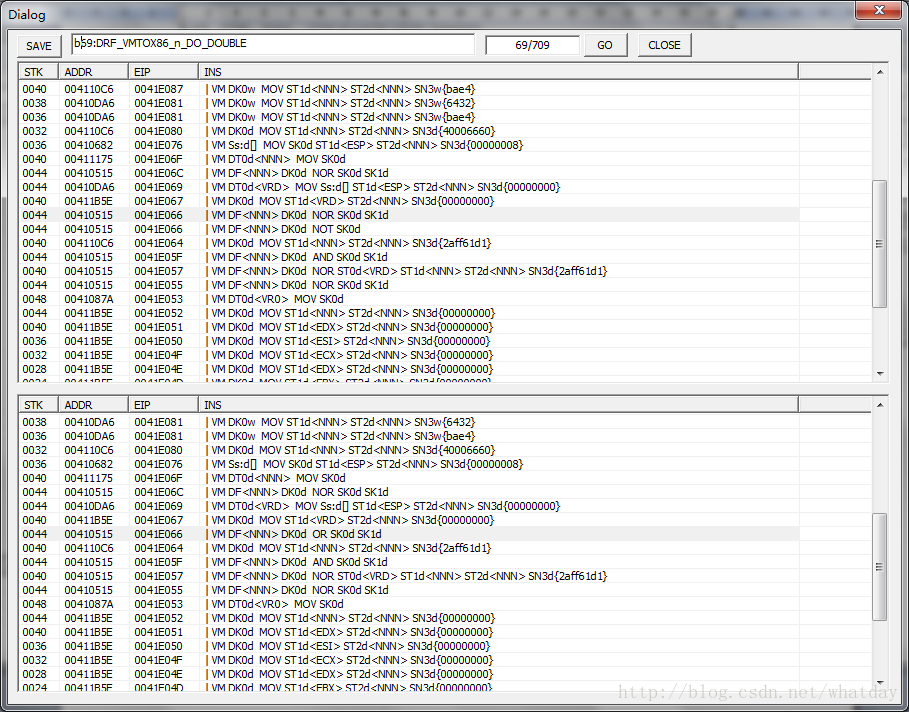
这条指令列出来的重点有两个,第一,这是个逻辑计算,在ZVM对付VMP的过程中,大量存在的逻辑计算,比如这个规则的高亮处两条指令分别是:
004400410515 0041E066 | VM DF<NNN> DK0d NOR SK0d SK1d
004400410515 0041E066 | VM DF<NNN> DK0d NOT SK0d
NOR+ NOT 很明显 =OR
第二个重点是,还原VMP比较难受的地方,也就是把指令上下移动,但是在移动的过程中,必须清晰的了解指令和指令之间的交叉冲突,在确认不影响的情况下,才能移动或者是进行规则处理,如果一旦有遗漏,错一个地方,就将影响全盘的还原结果.这些难受的地方中,以堆栈尤为难受,你可以看见本例中两个指令以及上下文中的几个VM指令,几乎都是堆栈操作.非常烦人.
继续:
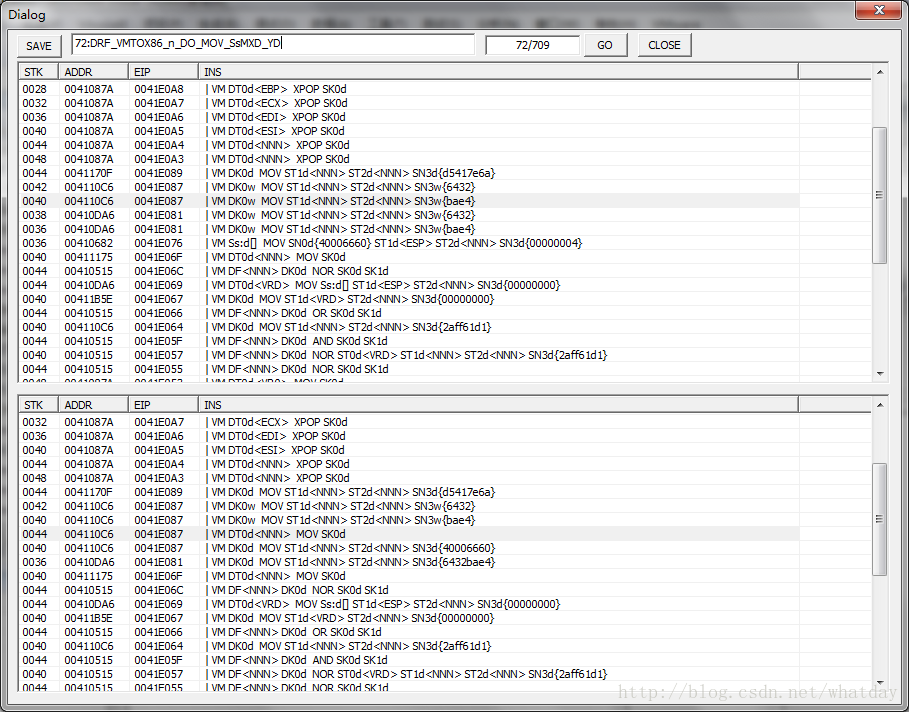
这条指令比较复杂,首先,在EIP = 0041E076位置上,是一个没见过的MOV指令.
这个MOV指令实际上是VM_MOV_SN0_DME.这条指令名字写的不好,实际上应该写为VM_DME_MOV_SN0.更可读.
意思就是,把SN0的数据,移动到DME中,所谓的DME指的是内存寻址一个目标,也就是[E].所谓的E,之前说过了,指的是ST1+ST2+SN3的组合
所以这条指令实际上是:
[ST1 + ST2 + SN3] <= SN0
又由于这条指令的ST1d是ESP(是VM_ESP),所以写入的目标是堆栈[VM_ESP+4]的地方.
所以这条指令和之前的两个PUSHW:
003800410DA6 0041E081 | VM DK0w MOV ST1d<NNN>ST2d<NNN> SN3w{6432}
003600410DA6 0041E081 | VM DK0w MOVST1d<NNN> ST2d<NNN> SN3w{bae4}
003600410682 0041E076 | VM Ss:d[] MOVSN0d{40006660} ST1d<ESP> ST2d<NNN> SN3d{00000004}
生成如下指令:
0044004110C6 0041E087 | VM DT0d<NNN> MOV SK0d
0040004110C6 0041E087 | VM DK0d MOVST1d<NNN> ST2d<NNN> SN3d{40006660} 这个先入栈
003600410DA6 0041E081 | VM DK0d MOVST1d<NNN> ST2d<NNN> SN3d{6432bae4}
后面两条我相信不需要解释,由于覆盖了[VM_ESP+4]的数据,所以这个堆栈的数据已经无效了,所以添加一条指令
0044 004110C6 0041E087 | VMDT0d<NNN> MOV SK0d
用来结束堆栈中的这个数据.(对之前的代码而言).
继续:
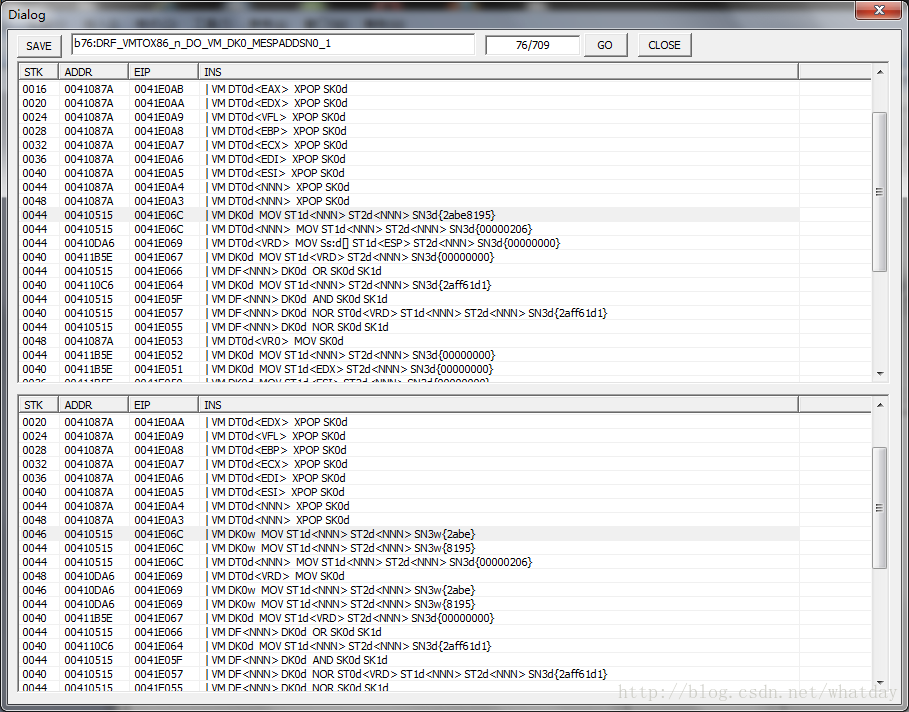
这个规则比较有意思,为了兼容不同位数的操作数的指令还原,比如BYTE,WORD,DWORD,我把大部分32位的操作都拆分为16位操作,如图所示.这样保证了处理过程的顺畅,从而避免了如下情况:
PUSHW
PUSHD
PUSHW
的出现.因为这种情况实际上应该是:
PUSHD
PUSHD
但是被VM强行的拆开,进行穿插结合.从而加大了还原难度.又因为BYTE和WORD在VMP中都是16位操作,所以我统一的把32位操作解为16位,以方便后续处理.
PUSHW+ PUSHW + PUSHW + PUSHW
继续:
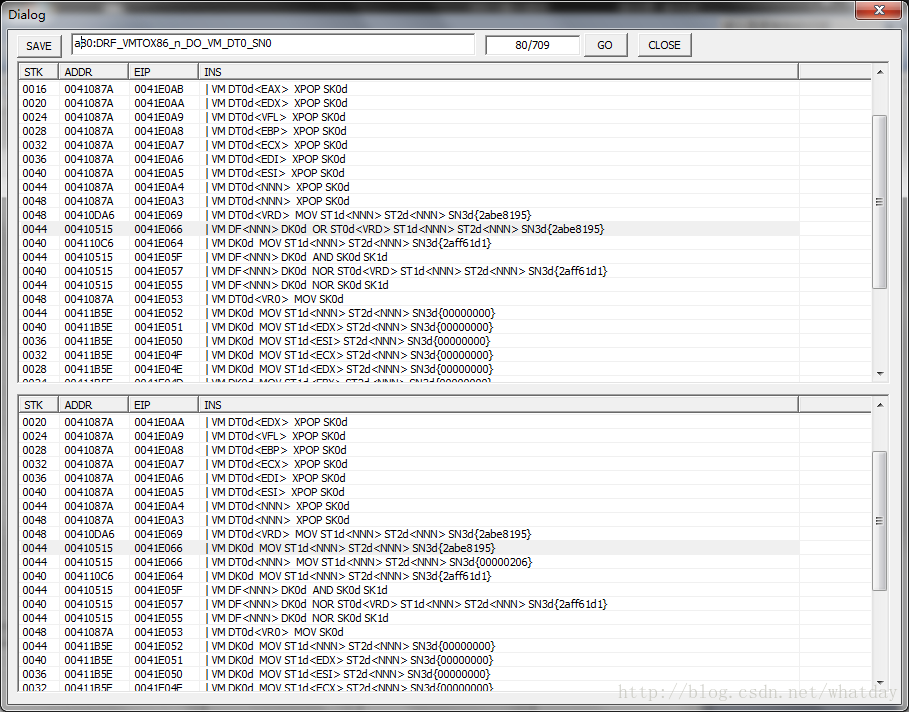
这个界面显示的中间部分,大量逻辑计算指令的部分,和原始指令没有任何关系.
这些都是在计算下一个VM指令块的EIP地址.在最高难度模式的VM指令流中,必须像这样每一块都计算出下一块的地址,才能继续读取.比混淆层的计算要难的多的多.
看到这里似乎感觉很恶心,原始指令就仅仅是一条XOR而已.犯得着搞的这么复杂吗,不过这侧面反映出,想要通过加密后的指令,肉眼看出执行逻辑,实际上是非常不可思议的事情.
继续:
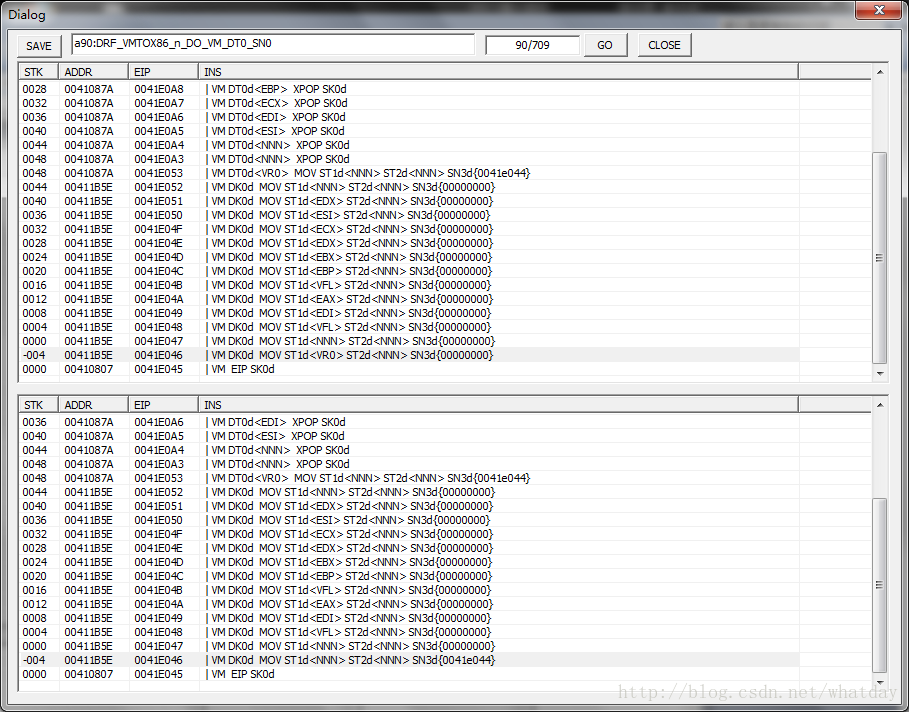
到了这里总算是算出了下一个VM指令快的地址了,41e044是保存在VR0寄存器中过来的,最后一个XPUSH指令压入后,被VM_EIP_SK0d取出并转为VM_JMP指令,继续下一个指令块.
继续:
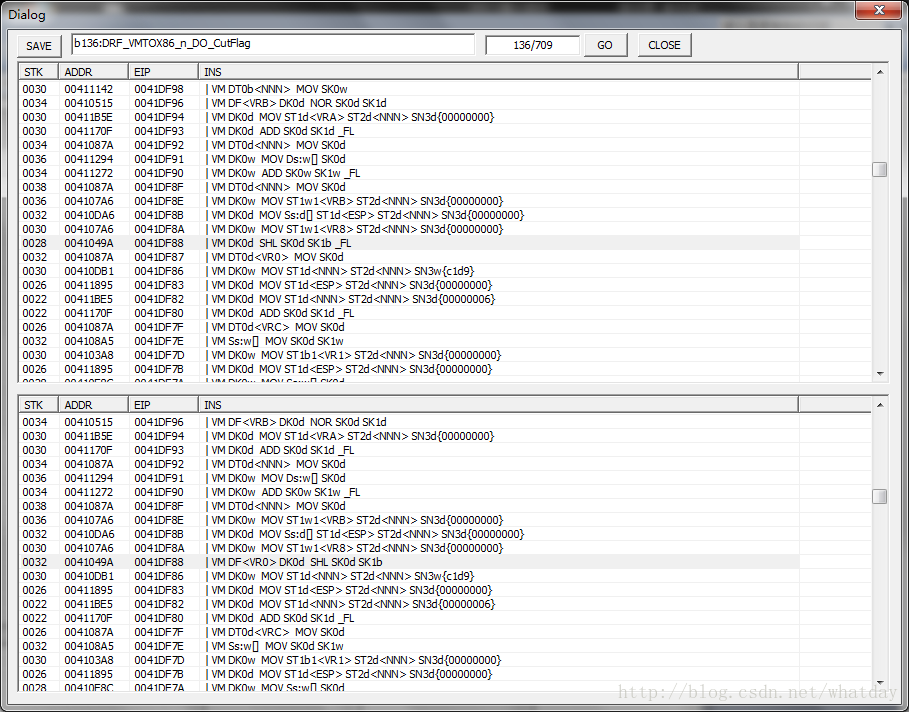
这条规则可能之前出现过,没看见,这里看见了就顺便解释下,规则名字叫做CUTFLAG,顾名思义,就是消除VM指令之后的_FL标志,因为一旦是带了_FL标志,表示堆栈将会额外的压入一个标志位到VM堆栈.这个概念,对于处理规则并不方便.所以所有带_FL的指令,都将会优先处理,把标志位设定到带DF<>的指令中.
继续:
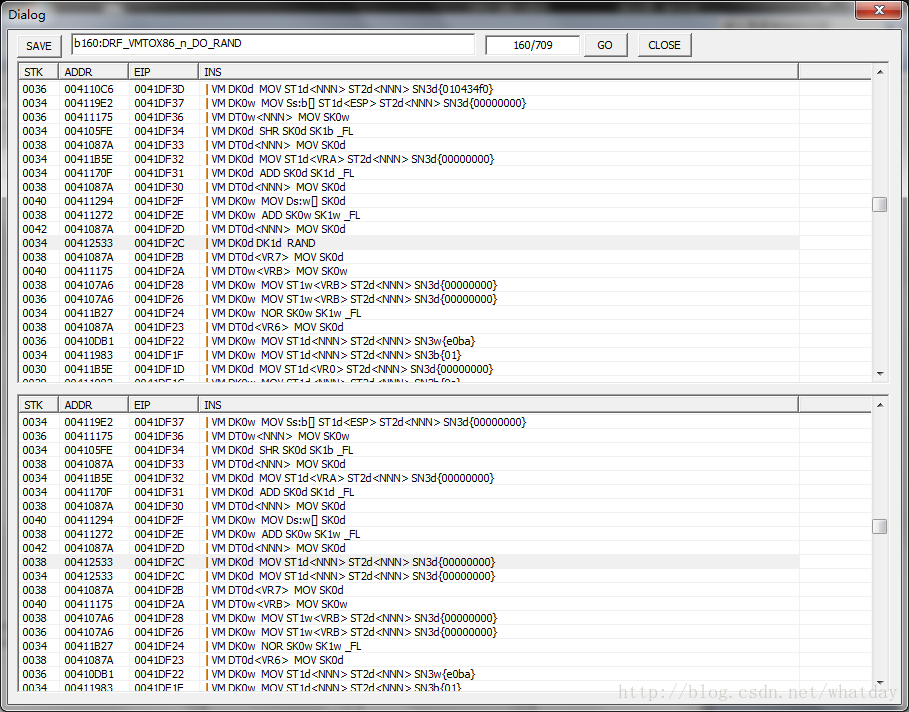
这个RAND实际上就是rdtsc指令,反调试和反虚拟机用的,对于静态还原,他并不起什么作用,所以我这里直接用两个0代替了它的结果.
继续:
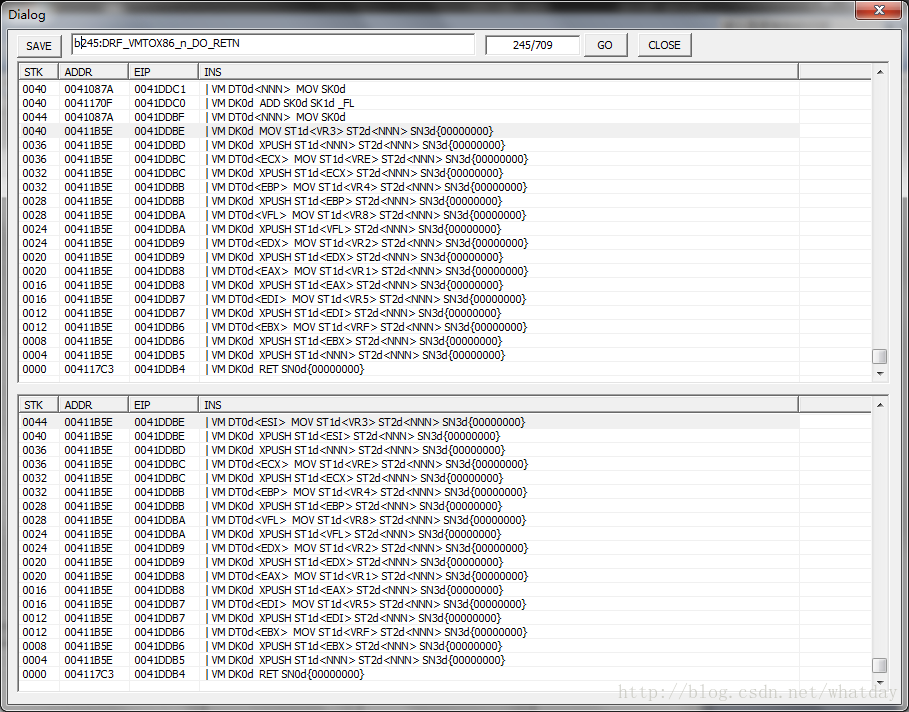
这里对于RET指令进行了一些分析,并从RET指令之中,起出了某些数据,对于RET指令之前的XPUSH进行了补充,以方便对之前的数据进行还原.
这个规则不是决定性的,因为很多时候,加密的结果复杂的情况下,你无法获取到RET指令.也就无法应用这个规则,进行反方向的还原.
继续:
这条比较简单,就是一个堆栈的COPY.
继续:

这条规则,由于PUSH本身占用了一个堆栈,所以合成之后的指令的堆栈偏移是+8
如果是顺序颠倒的
这样的就不需要调整偏移了.
继续:
最后一个例子,我想给出一个跳转的例子,于是ASM的代码要换了:
.686
.MODELFLAT ,STDCALL
.CODE
test_vmpproc
db 0EBh,10h,'VMProtect begin',0
cmp eax, eax
jge@f ;(zf == 0 and sf = of)
xorecx, edx
@@:
xoredx, eax
db0EBh,0Eh,'VMProtect end', 0
ret
test_vmpendp
start:
call test_vmp
ret
endstart
这份代码就属于比较复杂的了,ZVM出错了一次.所以不保证正常压缩.这份代码加密后,ZVM解密出的代码是:
000000401000 00000000 | VM XINITSN0d{0041de75}
0004004059E4 0041DE75 | VM DT0d<NNN> XPOP SK0d
0008004059E4 0041DE76 | VM DT0d<NNN> XPOP SK0d
0012004059E4 0041DE77 | VM DT0d<EAX> XPOP SK0d
0016004059E4 0041DE78 | VM DT0d<NNN> XPOP SK0d
0020004059E4 0041DE79 | VM DT0d<EBX> XPOP SK0d
0024004059E4 0041DE7A | VM DT0d<EDX> XPOP SK0d
0028004059E4 0041DE7B | VM DT0d<ESI> XPOP SK0d
0032004059E4 0041DE7C | VM DT0d<EBP> XPOP SK0d
0036004059E4 0041DE7D | VM DT0d<ECX> XPOP SK0d
0040004059E4 0041DE7E | VM DT0d<EDI> XPOP SK0d
0044004059E4 0041DE7F | VM DT0d<NNN> XPOP SK0d
0048004059E4 0041DE80 | VM DT0d<NNN> XPOP SK0d
004800406F5B 0041D99F | VM DF<VRF> DT0d<NNN> SUB ST0d<EAX> ST1d<EAX>ST2d<NNN> SN3d{00000000}
004800405043 0041DAEC | VM SF_EQ_OFST0d<VRF>
004400405164 0041DB0E | VM DK0d XPUSH ST1d<NNN>ST2d<NNN> SN3d{00000000}
004000405164 0041DB0F | VM DK0d XPUSH ST1d<NNN>ST2d<NNN> SN3d{00000000}
003600405164 0041DB10 | VM DK0d XPUSH ST1d<ESI>ST2d<NNN> SN3d{00000000}
003200405164 0041DB11 | VM DK0d XPUSH ST1d<EDI>ST2d<NNN> SN3d{00000000}
002800405164 0041DB12 | VM DK0d XPUSH ST1d<EDX>ST2d<NNN> SN3d{00000000}
002400405164 0041DB13 | VM DK0d XPUSH ST1d<EBP>ST2d<NNN> SN3d{00000000}
002000405164 0041DB14 | VM DK0d XPUSH ST1d<NNN>ST2d<NNN> SN3d{00000000}
001600405164 0041DB15 | VM DK0d XPUSH ST1d<EBX>ST2d<NNN> SN3d{00000000}
001200405164 0041DB16 | VM DK0d XPUSH ST1d<ECX>ST2d<NNN> SN3d{00000000}
000800405164 0041DB17 | VM DK0d XPUSH ST1d<EAX>ST2d<NNN> SN3d{00000000}
000400405164 0041DB18 | VM DK0d XPUSH ST1d<NNN>ST2d<NNN> SN3d{00000000}
000000405164 0041DB19 | VM DK0d XPUSHST1d<NNN> ST2d<NNN> SN3d{00000000}
000000404FA7 0041DB1B <-VM JOKSN0d{0041db9a}
000000404FA7 0041DB1B <-VM JMPSN0d{0041db1c}
0004004059E4 0041DB1C ->VM DT0d<NNN> XPOP SK0d
0008004059E4 0041DB1D | VM DT0d<NNN> XPOP SK0d
0012004059E4 0041DB1E | VM DT0d<EAX> XPOP SK0d
0016004059E4 0041DB1F | VM DT0d<ECX> XPOP SK0d
0020004059E4 0041DB20 | VM DT0d<EBX> XPOP SK0d
0024004059E4 0041DB21 | VM DT0d<NNN> XPOP SK0d
0028004059E4 0041DB38 | VM DT0d<EBP> XPOP SK0d
0032004059E4 0041DB39 | VM DT0d<EDX> XPOP SK0d
0036004059E4 0041DB3A | VM DT0d<EDI> XPOP SK0d
0040004059E4 0041DB3B | VM DT0d<ESI> XPOP SK0d
0044004059E4 0041DB3C | VM DT0d<NNN> XPOP SK0d
0048004059E4 0041DB3D | VM DT0d<NNN> XPOP SK0d
004800405043 0041DB4D | VM DF<NNN> DT0d<ECX> XOR ST0d<EDX> ST1d<ECX>ST2d<NNN> SN3d{00000000}
004400406F5B 0041DB75 | VM DK0d XPUSH ST1d<NNN>ST2d<NNN> SN3d{00000000}
004000405164 0041DB77 | VM DK0d XPUSH ST1d<NNN>ST2d<NNN> SN3d{00000000}
003600405164 0041DB78 | VM DK0d XPUSH ST1d<ESI>ST2d<NNN> SN3d{00000000}
003200405164 0041DB79 | VM DK0d XPUSH ST1d<EDI>ST2d<NNN> SN3d{00000000}
002800405164 0041DB7A | VM DK0d XPUSH ST1d<EDX>ST2d<NNN> SN3d{00000000}
002400405164 0041DB7B | VM DK0d XPUSHST1d<EBP> ST2d<NNN> SN3d{00000000}
002000405043 0041DB93 | VM DK0d XPUSH ST1d<NNN>ST2d<NNN> SN3d{00000000}
001600405164 0041DB95 | VM DK0d XPUSH ST1d<EBX>ST2d<NNN> SN3d{00000000}
001200405164 0041DB96 | VM DK0d XPUSH ST1d<ECX>ST2d<NNN> SN3d{00000000}
000800405164 0041DB97 | VM DK0d XPUSH ST1d<EAX>ST2d<NNN> SN3d{00000000}
000400405164 0041DB98 | VM DK0d XPUSH ST1d<NNN>ST2d<NNN> SN3d{00000000}
000000405164 0041DB99 | VM DK0d XPUSH ST1d<NNN>ST2d<NNN> SN3d{00000000}
000000405164 0041DB99 <-VM JMPSN0d{0041db9a}
0004004059E4 0041DB9A ->VM DT0d<NNN> XPOP SK0d
0008004059E4 0041DB9B | VM DT0d<NNN> XPOP SK0d
0012004059E4 0041DB9C | VM DT0d<EAX> XPOP SK0d
0016004059E4 0041DB9D | VM DT0d<ECX> XPOP SK0d
0020004059E4 0041DB9E | VM DT0d<EBX> XPOP SK0d
0024004059E4 0041DB9F | VM DT0d<NNN> XPOP SK0d
0028004059E4 0041DBB6 | VM DT0d<EBP> XPOP SK0d
0032004059E4 0041DBB7 | VM DT0d<EDX> XPOP SK0d
0036004059E4 0041DBB8 | VM DT0d<EDI> XPOP SK0d
0040004059E4 0041DBB9 | VM DT0d<ESI> XPOP SK0d
0044004059E4 0041DBBA | VM DT0d<NNN> XPOP SK0d
0048004059E4 0041DBBB | VM DT0d<NNN> XPOP SK0d
004800405164 0041DE71 | VM DF<VFL> DT0d<EDX> XOR ST0d<EAX> ST1d<EDX>ST2d<NNN> SN3d{00000000}
004400405164 0041DE71 | VM DK0d XPUSH ST1d<NNN>ST2d<NNN> SN3d{00000000}
004000405164 0041DE71 | VM DK0d XPUSH ST1d<NNN>ST2d<NNN> SN3d{00000000}
003600405164 0041DE71 | VM DK0d XPUSH ST1d<EDI>ST2d<NNN> SN3d{00000000}
003200405164 0041DE71 | VM DK0d XPUSHST1d<ECX> ST2d<NNN> SN3d{00000000}
002800405164 0041DE71 | VM DK0d XPUSH ST1d<EBP>ST2d<NNN> SN3d{00000000}
002400405164 0041DE71 | VM DK0d XPUSH ST1d<ESI>ST2d<NNN> SN3d{00000000}
002000405164 0041DE71 | VM DK0d XPUSH ST1d<EDX>ST2d<NNN> SN3d{00000000}
001600405164 0041DE71 | VM DK0d XPUSH ST1d<NNN>ST2d<NNN> SN3d{00000000}
001200405164 0041DE71 | VM DK0d XPUSH ST1d<EBX>ST2d<NNN> SN3d{00000000}
000800405164 0041DE71 | VM DK0d XPUSH ST1d<EAX>ST2d<NNN> SN3d{00000000}
000400405164 0041DE72 | VM DK0d XPUSH ST1d<VFL>ST2d<NNN> SN3d{00000000}
000000405164 0041DE73 | VM DK0d XPUSH ST1d<NNN>ST2d<NNN> SN3d{00000000}
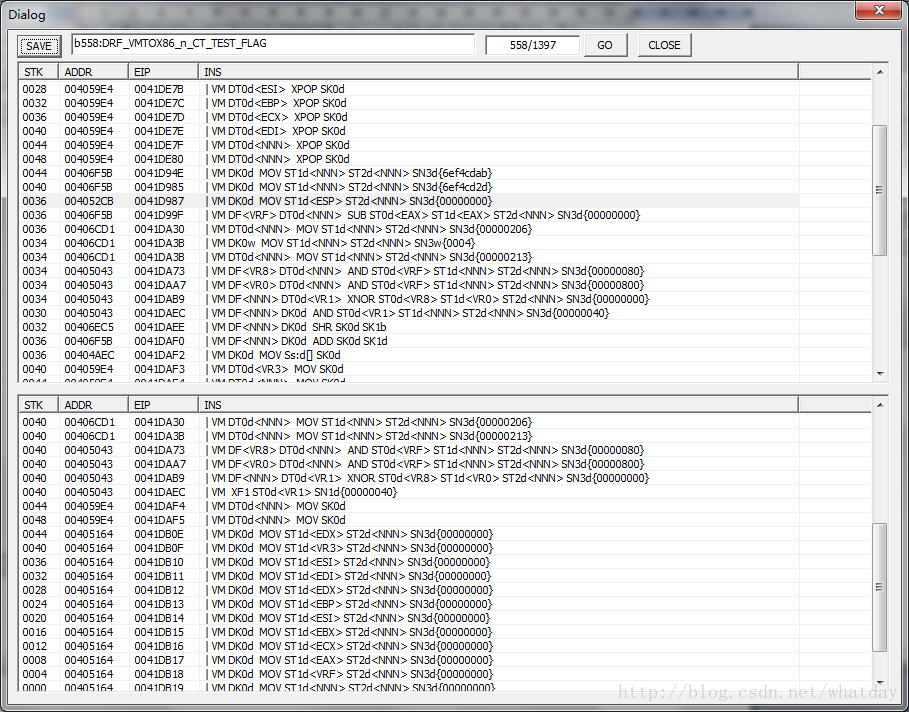
000000406E96 0041DE74 | VM RRETSN0d{0040102a} SN1d{00000000}
由于VM指令流段和段之间存在太多寄存器轮转留下的X开头的栈代码,所以可以精简为以下部分:
004800406F5B 0041D99F | VM DF<VRF> DT0d<NNN> SUB ST0d<EAX> ST1d<EAX>ST2d<NNN> SN3d{00000000}
004800405043 0041DAEC | VM SF_EQ_OFST0d<VRF>
000000404FA7 0041DB1B <-VM JOKSN0d{0041db9a}
000000404FA7 0041DB1B <-VM JMPSN0d{0041db1c}
0004004059E4 0041DB1C ->
004800405043 0041DB4D | VM DF<NNN> DT0d<ECX> XOR ST0d<EDX> ST1d<ECX>ST2d<NNN> SN3d{00000000}
000000405164 0041DB99 <-VM JMPSN0d{0041db9a}
0004004059E4 0041DB9A ->
004800405164 0041DE71 | VM DF<VFL> DT0d<EDX> XOR ST0d<EAX> ST1d<EDX>ST2d<NNN> SN3d{00000000}
000000406E96 0041DE74 | VM RRETSN0d{0040102a} SN1d{00000000}
代码中我还是保留了额外两个可以删除的VM_JMP指令,这就比较可读了.
第一行是对比,CMP指令实际上就是SUB指令,只不过是不影响标志位的,这里的VM_SUB指令,将标志位设置到VM的标志位寄存器VRF中,然后通过SF_EQ_OF(JNL/JGE SF=OF Not Less/Greater or Equal)来判断,查询intel指令表,可得这里就是JGE跳转.
如果符合条件,则用VM_JOK指令,跳转到0041DB9A地址,否则跳转入下一条指令地址0041DB1C.代码比较清晰.
跳转的还原过程,大概就是这样了,本章重点说明下跳转的实现,也就是指令VM_JOK的构成:
首先截图的部分,就是生成JOK和VM_SF_EQ_OF部分的指令处理规则.这部份我摘录出来,如下:
000000401000 00000000 | VM XINITSN0d{0041de75}
0004004059E4 0041DE75 | VM DT0d<NNN> XPOP SK0d
0008004059E4 0041DE76 | VM DT0d<NNN> XPOP SK0d
0012004059E4 0041DE77 | VM DT0d<EAX> XPOP SK0d
0016004059E4 0041DE78 | VM DT0d<NNN> XPOP SK0d
0020004059E4 0041DE79 | VM DT0d<EBX> XPOP SK0d
0024004059E4 0041DE7A | VM DT0d<EDX> XPOP SK0d
0028004059E4 0041DE7B | VM DT0d<ESI> XPOP SK0d
0032004059E4 0041DE7C | VM DT0d<EBP> XPOP SK0d
0036004059E4 0041DE7D | VM DT0d<ECX> XPOP SK0d
0040004059E4 0041DE7E | VM DT0d<EDI> XPOP SK0d
0044004059E4 0041DE7F | VM DT0d<NNN> XPOP SK0d
0048004059E4 0041DE80 | VM DT0d<NNN> XPOP SK0d
以下两行,实际上就是跳转目标地址了,但是是加密的,取出之后,经过解密(比如xor之流),然后直接JMP到目标地址.
值得注意的是,这里的两个是顺序压入到VM堆栈中的,所以他们在内存中的位置,实际上是[ESP]和[ESP+4]这点先牢记.
004400406F5B 0041D94E | VM DK0d MOV ST1d<NNN>ST2d<NNN> SN3d{6ef4cdab}
004000406F5B 0041D985 | VM DK0d MOVST1d<NNN> ST2d<NNN> SN3d{6ef4cd2d}
以下这行,这里的代码将VM_ESP本身也放入堆栈了.
0036004052CB 0041D987 | VM DK0d MOVST1d<ESP> ST2d<NNN> SN3d{00000000}
以下行是CMP指令变体SUB指令(它没有目的操作寄存器),注意生成了VRF供后面操作,其他不需要关心,为了顺序起见,我没有删除.
003600406F5B 0041D99F | VM DF<VRF> DT0d<NNN> SUB ST0d<EAX> ST1d<EAX>ST2d<NNN> SN3d{00000000}
003600406CD1 0041DA30 | VM DT0d<NNN> MOV ST1d<NNN> ST2d<NNN> SN3d{00000206}
这个指令压入一个WORD的值4,记住,压入了一个4.
003400406CD1 0041DA3B | VM DK0w MOVST1d<NNN> ST2d<NNN> SN3w{0004}
这个指令没用.
003400406CD1 0041DA3B | VM DT0d<NNN> MOV ST1d<NNN> ST2d<NNN> SN3d{00000213}
以下几行的作用比较明显了,首先,VRF是上面CMP指令的变体SUB指令算出的,然后通过两个AND相应的位(SF和OF),算出两个FLAG值,最后这两个FLAG值,通过XNOR,算出两个FLAG的ZF位是否相同,存放入VR1.
003400405043 0041DA73 | VM DF<VR8> DT0d<NNN> AND ST0d<VRF> ST1d<NNN>ST2d<NNN> SN3d{00000080}
003400405043 0041DAA7 | VM DF<VR0> DT0d<NNN> AND ST0d<VRF> ST1d<NNN>ST2d<NNN> SN3d{00000800}
003400405043 0041DAB9 | VM DF<NNN> DT0d<VR1> XNOR ST0d<VR8> ST1d<VR0>ST2d<NNN> SN3d{00000000}
以下指令通过刚才算出的VR1的ZF位,做对比,得出一个值,这个值要么是0x00000040,要么是0x00000000
然后这个值SHR也就是右移动4位.这个4是上面压入的.
最后得到一个值,要么是0x00000004要么是0x00000000
这个值最终通过ADD指令,和VM_ESP相加.得到我们之前说过的那个值[ESP]或者是[ESP+4]
然后取出这个值.放入VR3
003000405043 0041DAEC | VM DF<NNN> DK0d AND ST0d<VR1> ST1d<NNN> ST2d<NNN> SN3d{00000040}
003200406EC5 0041DAEE | VM DF<NNN> DK0d SHR SK0d SK1b
003600406F5B 0041DAF0 | VM DF<NNN> DK0d ADD SK0d SK1d
003600404AEC 0041DAF2 | VM DK0d MOV Ss:d[]SK0d
0040004059E4 0041DAF3 | VM DT0d<VR3> MOV SK0d
以下两个指令无用
0044004059E4 0041DAF4 | VM DT0d<NNN> MOV SK0d
0048004059E4 0041DAF5 | VM DT0d<NNN> MOV SK0d
这个指令解密了VR3中存放的数据,放入VR8中
004800405043 0041DB0B | VM DF<NNN> DT0d<VR8> XOR ST0d<VR3> ST1d<NNN>ST2d<NNN> SN3d{6eb51631}
以下指令无用
004400405164 0041DB0E | VM DK0d MOV ST1d<EDX>ST2d<NNN> SN3d{00000000}
004000405164 0041DB0F | VM DK0d MOV ST1d<VR3>ST2d<NNN> SN3d{00000000}
003600405164 0041DB10 | VM DK0d MOV ST1d<ESI>ST2d<NNN> SN3d{00000000}
003200405164 0041DB11 | VM DK0d MOV ST1d<EDI>ST2d<NNN> SN3d{00000000}
002800405164 0041DB12 | VM DK0d MOV ST1d<EDX>ST2d<NNN> SN3d{00000000}
002400405164 0041DB13 | VM DK0d MOV ST1d<EBP>ST2d<NNN> SN3d{00000000}
002000405164 0041DB14 | VM DK0d MOV ST1d<ESI>ST2d<NNN> SN3d{00000000}
001600405164 0041DB15 | VM DK0d MOV ST1d<EBX>ST2d<NNN> SN3d{00000000}
001200405164 0041DB16 | VM DK0d MOVST1d<ECX> ST2d<NNN> SN3d{00000000}
000800405164 0041DB17 | VM DK0d MOV ST1d<EAX>ST2d<NNN> SN3d{00000000}
000400405164 0041DB18 | VM DK0d MOV ST1d<VRF>ST2d<NNN> SN3d{00000000}
000000405164 0041DB19 | VM DK0d MOV ST1d<NNN>ST2d<NNN> SN3d{00000000}
VR8的数据入栈并且弹出送给VM_EIP指令,从而完成了一个跳转.不明白的可以多看几次.
-00400405164 0041DB1A | VM DK0d MOV ST1d<VR8>ST2d<NNN> SN3d{00000000}
000000404FA7 0041DB1B | VM EIP SK0d
文仍未完.待续………














 2998
2998











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









