






本文是11年Dan C.Ciresan的作品,主要贡献是提供了一种快速,全GPU部署的CNN计算框架,通过快速的GPU计算可以让作者尝试相对以前的神经网络更深的CNN,而且是仅仅使用监督学习的方式。
本来不想写本文的总结的,但是最近看了ImageNet上取得好成绩的网络,都是通过GPU(caffe,convnet)部署,仅仅通过监督学习的方式来训练更加深的CNN,所以打算总结一下本文,作为在GPU上通过监督学习来训练深度CNN的开篇(Dan不是第一个使用GPU计算CNN的,个人见解)。
一,介绍
……尽管在硬件上的进步,计算速度仍然是限制CNN发展的一个主要瓶颈。为了系统性地测试各种结构的影响,本文提供了一种快速GPU部署CNN框架。之前的GPU部署CNN都是为了满足GPU硬件的限制,或者使用一般的函数库,然而我们的GPU部署比较灵活而且是on-line的权值学习方式。我们的部署允许训练CNN时间是以天为单位,而不是月;这样我们可以探索更大的参数空间,研究各种结构的影响。
二.CNN
2.1卷积层
C层的参数=f(特征图大小,特征图个数,filter尺寸,跳跃间隔因子,连接表)
采用valid的卷积方式,卷积后特征图大小关系,如下式:
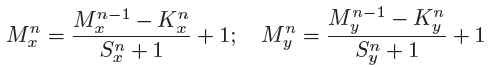
n代表层数,M代表每层特征个数,x,y分别代表特征图的长宽。K代表filter,S代表跳跃间隔数。(貌似上面公式并不具有普遍性,因为自己在后面的一些论文用此公式是map的尺寸和公式的结果不一样,估计可能是和Stride的定义有关,再有就是填充像素的原因)
2.2 max-Pooling层
相比mean-Pooling,max-Pooling能够较快的收敛,选择更加具有不变性的特征,而且还能够增加泛化能力。Max-Pooling能够在更大的局域上具有不变性,下采样(降维)特征图按照Kx和Ky倍数。
2.3 分类层
需要选择Filter尺寸,max-pooling局域尺寸形状和跳跃间隔来使得最后一个卷基层的输出为1像素,然后通过全连接连接到分类器。
三 GPU部署
最新一代的NVIDIVA GPU,400或者500系列(作者使用GTX480和580),新一代的GPU可以快速编程和简化编码,实验中,仅仅是利用更快的GPU就可以使实验提速两到三倍。
人工优化CUDA代码是非常耗时而且容易出错;依靠L2缓存多个设备的内存互联,我们优化新的结构,而不是使用分享内存;这种优化策略代码运行很快。我们使用以下的优化方法:
预计算表达式,打开模板核内的循环,跳跃矩阵去获得联合的内存互联,regiser where possible(说实话上面说的暂时一个都不白)。
3.1数据结构3.2前馈传播3.3反向传播
上面的部分看了好几遍,只了解个大意,通过特征图的方式来前馈计算和反馈误差传播,连接方式通过一个连接矩阵来决定,矩阵的每一个列为没层间的连接关系。在具体计算上,涉及到一些线程的东西,不太明白就不具体介绍了(以后在研究,暂时只研究结构)。
四 实验
采用on-line梯度更新方式,训练集同时也作为验证集。如果使用图像“污染”的图像增溢技术,仅仅在训练阶段使用。
权值初始化:W初始值为在区间[-0.05,0.05]内的均与分布
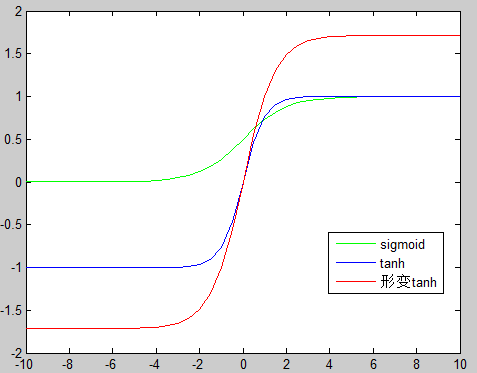
激活函数使用缩放的正切tanh函数:y=1.7159tanh(0.66666a),这个不明白为啥,从下图来看,形变tanh有更宽(x轴)的更长(y轴)等,这样可以允许有更大的数据变换空间。
4.1在MNIST上实验
数据增益:平移,旋转,尺寸缩放,水平翻转和弹性形变
学习率:迭代500次,持续缩减从1E-3到3*5E-5
M代表卷积阶段特征个数,N代表全连接层的神经元个数
全连接的卷基层会导致过多的filter和连接,使得训练大型和深度CNN网络,在GPU上有些不合理。部分链接可以消除这个问题,并且部分链接更符合生物特征;本文通过随机连接的方式来确定卷积层之间的连接方式。

上表列出了2到7个卷基层,通过随机的方式确定层间连接的卷积网络。网络越深(计算越复杂)获得的准确率越大;此外,深的网络需要更多的计算时间来完成一次迭代;但同时深的网络需要更少的迭代次数就可以达到很好的准确率。上表中最深的7层网络在迭代1次,3次,17次时分别达到了2.42%,1.58%和0.68%的准确率;而4层网络在迭代1,3,17次之后达到了4.71%,1.58%和0.68%的准确率;并且在34不之后获得了0.5%的准确率。
这个结果证明深度网络可以通过监督学习来达到很好准确率(不用先使用无监督预训练),尽管深度网络有更多的自由参数,但是深度网络学习的更快。这个结论和上一篇博文中随机权值的CNN网络具有天然的特征提取能力很像,而且深度越深这种提取能力越强;此外在很少的迭代次数就达到了很好结果,还和MNIST数据集本身形变相对较小有关;在增加深度的同时,参数增多,很容易使网络过拟合,对于样本的需求量也比较大,所以本文的数据增益技术也是训练深度网络的一个因素,此外由于本文利用GPU可以快速计算,可以很快地计算大量的数据。所以本文计算速度,网络结构,大的数据是关键。
4.2 在NORB数据集上实验
NORB包含3D的物体,所以输入有两张图片。旋转,缩放和弹性形变等数据增益技术在泛化能力上有负面影响。这些数据增益技术是2D图像本身具有的提升识别准确率的技术,但是貌似不适合3D图像。
最初在NORB上的实验CNN网络在迭代3到6步就达到了验证数据集0误差率,这让作者实验更大的网络结构,每层有更多的maps。
所以作者提出了一个新的结构框架:
300F(6,6,1) →max-P(2,2,0) →500F(4,4,0) →max-P(4,4,0) →500fc →Classifer
学习率:初始为0.001;每次除以0.95
下表展示了在在使用和不使用图像平移和数据预处理(Image processing)情况下和不同迭代次数下的实验结果。
在NORB数据集上最好的结果是2.87%,通过使用CNN同时,加上原始图像的边缘信息;这个促使我们使用图像处理技术(固定的filter),例如sobel(计算机视觉领域的一种重要处理方法。主要用于获得数字图像的一阶梯度,常见的应用和物理意义是边缘检测),scharr等,实际上最好的结果是使用21*21的墨西哥帽子filter;作者使用两种filter(一个是同轴同心感受野用来提取在亮度上的正向对比,另一个是同轴不同心的来提取负向对比)。这样一个2个原始图像经过filter处理后就变成了6个图像,输入到网络中训练。

结果分析:
1,使用5%的平移增益时,结果达到了4.71%,说明CNN固有的平移不变性是有限度的;
2,使用IP的情况下,准确率提升很多在IP技术上融合平移增益得到了state-of-the-art的结果。
和其他数据集的实验对比,NORB是一个很不寻常的数据集,训练集的每个种类只有5个实例;这让网络学习很快,但是泛化能力很差;NORB是唯一的一个数据集从IP中获得提升到;对于MNIST和CIFAR,这种IP技术对分类结果几乎没有什么提升,此外NORB数据集分类结果的标准差比比其他的数据集要大,相同的网络,在不同的初始化情况下结果不同。
4.3在CIFAR-10实验
CIFAR-10是一个32*32的彩色自然图片,包涵10各类别,每个类别有5000个训练集和1000个测试集。每个类别的图片具有很大的变化,物体不一定在中心,可能只包涵物体的一个部分,各种各样的背景。由于CIFAR图片很小,所以采用较小的filter尺寸。
网络结构:100F(3,3,0) →max-P(3,3,0) →100F(3,3,0) →max-P(2,2,0) → 100F(3,3,0) →max-P(2,2,0)→300fc →100fc →Classifer
参数设置:初始学习率0.001,没次迭代缩减0.993

结果分析:
1,不使用平移增益的情况下,实验结果不会低于20%,说明CNN具有的平移不变形是有限度的,IP对于CIFAR数据集作用不明显
2,在使用更多的特征个数,时间大幅增加同时,实验结果也有提升;但是更大的网络(400个特征图)结果反而下降,说明网络过大也是不适合的,这可能是由于网络过大,参数增多;需要更多的数据来防止过拟合。
4.4G GPU编码速度提升
小网络提升10倍,大网络提升近似60倍相对于CPU版本。
五,结论
1,提供了GPU版本的CNN训练方法,不仅快速,而且具有很大的灵活性
2,通过大量的实验证明目前CNN是最好的图像分类器。
六,一些困惑和理解
从CNN训练方式发展过程来看,先前在CIFAR和MNIST这种数据机上,各种深度模型都热衷于先unsupervised pretraining + fineturning 的学习方式;本文在GPU上快速灵活的基础上,直接利用CNN建立深度模型进行监督学习,在快速基础上使用数据增益技术来增大数据量,防止过拟合,证明了CNN单单凭借监督学习就可以达到很好的结果;使得研究的方向调转回来监督学习上,通过调节网络结构来获得好的结果(个人见解);例如12年的Alex—net就是在ImageNet上监督学习的深度CNN,以及13年,14年ILSVR上的各种net;都是在监督学习基础上,通过GPU和大的数据集,来调整自己的网络结构,获得好的结果。
本文成功的关键在于利用GPU的灵活快速计算,使得各种深度网络和数据增益技术可以快速的实验,从而达到了很好的结果,刷新了多个数据集;对比近两年的文章,作者本文并没有强调网络结构的重要性,例如filter尺寸,map的个数等。














 975
975











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









