







数据表分割策略和实现:
为什么要对数据表进行分割?就是因为随着数据量的不断激增,某张的表的记录数也飞速增长,这就给数据表操作造成性能影响。虽然,实际中会对数据表进行索引和查询等相关优化或者是做数据库集群和分区等优化,但是不论怎么优化,数据量的增加势必会导致数据表的操作受到影响,所以针对大数据表有必要进行分表。另外,分表可以按照业务紧密度和单表进行分割,前者属于垂直分割数据表,就是将业务紧密度高并且增长速度快的多张表划入到同一个数据库(此中分割往往会破坏表间关联关系),而后者是将一张或几张大数据量表中的数据分到若干个小表中,做到分摊大表数据压力的目的,这里介绍后者的设计,至于根据业务分表在后续分库中介绍说明。
· 原理
· 策略
· 实施
· 注意
一、原理
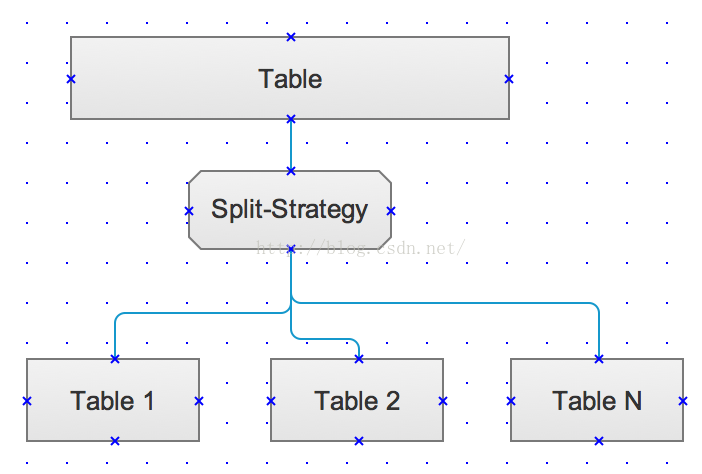
如上图所示,其实单表的分割比较简单,就是将当前的一张大数据表中的数据,按照约定的分割规则,将数据均摊到多张小的数据表,目的只是为日后表的CURD操作IO压力更小所设计的。对于Split-Strategy为分割表的策略,具体介绍在下面第二部分,而表分割的前提条件无疑是必须有一张大数据量的表Table,并将其根据分割算法,划分为Table1、Table2及TableN。
二、策略
目前数据表的分割没有同意标准的做法,不过有几种比较常用的策略,当然你也可以自行定义规则,也可以使用MyISAM引擎的MERGE实现分表(此中分表可以保持外间、事物及其它关联关系),具体如下:
1、取模
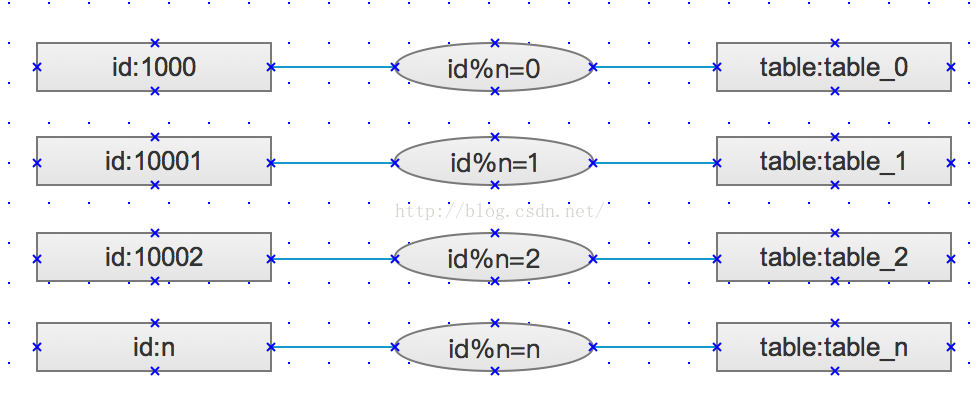
使用insert select组合完成从大数据表中select的值,并插入insert到分表中,分割规则不匹配的数据,保持在原表中不做分离,表的名字格式:tablesuffix_n。此种分割策略比较适合用在数据均分灵活且数据分散的需求。
2、时间
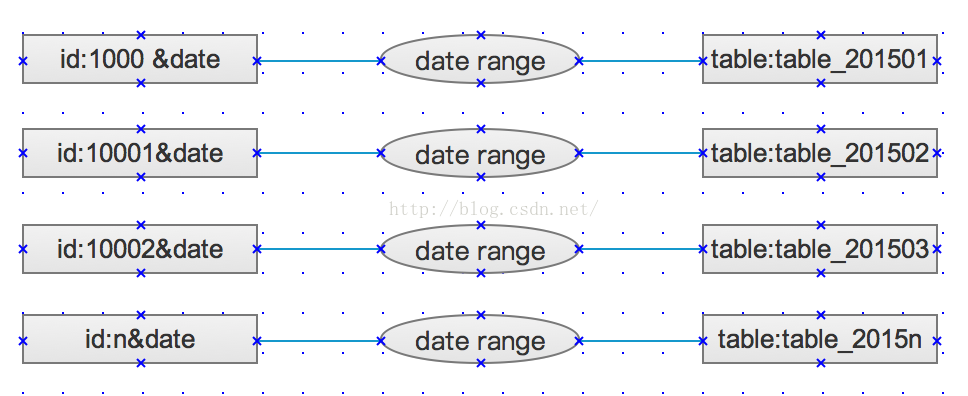
使用insert select组合完成从大数据表中select的值,并插入insert到分表中,分割规则不匹配的数据,保持在原表中不做分离,表的名字格式:tablesuffix_date。
date range代表条件日期的范围,比如:201503~201504。
3、哈希
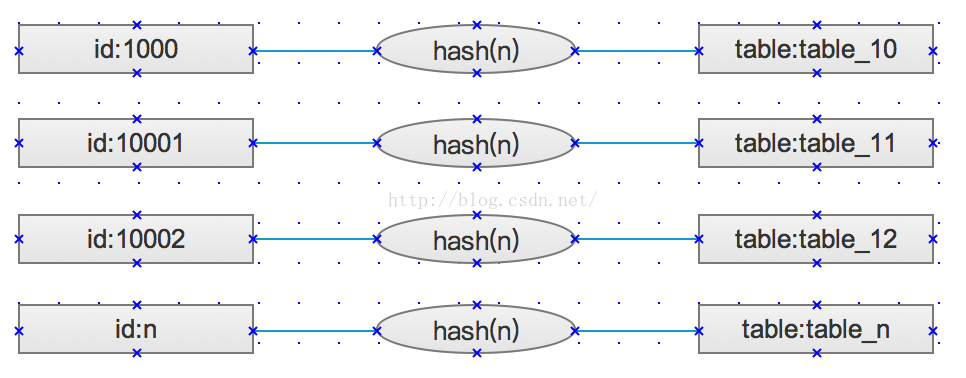
使用insert select组合完成从大数据表中select的值,并插入insert到分表中,分割规则不匹配的数据,保持在原表中不做分离,表的名字格式:tablesuffix_hash。
hash(n)代表获得根据ID生成的hash值的n位字符串,使用它来作为表名的一部分。
4、区域
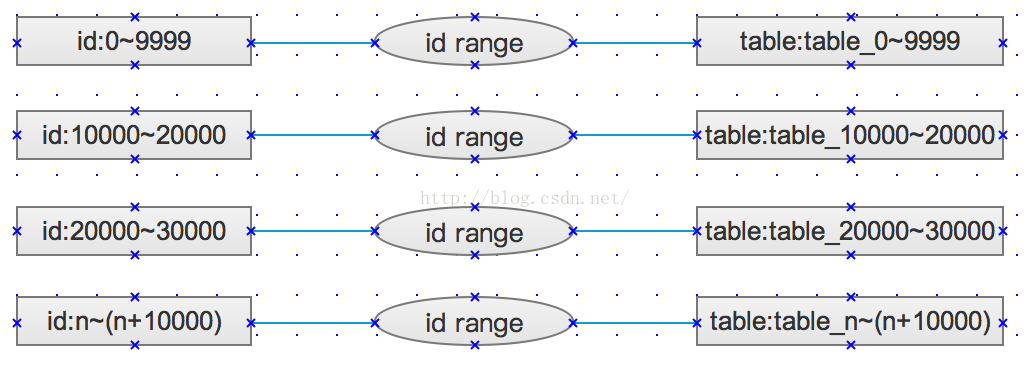
使用insert select组合完成从大数据表中select的值,并插入insert到分表中,分割规则不匹配的数据,保持在原表中不做分离,表的名字格式:tablesuffix_n~(n+x)。
id range代表当前记录ID的大小范围,比如:0~9999。
5、引擎
可以使用Mysql的MyISAM存储引擎,因为其支持MERAGE类型,结合UNION来实现数据表的分割和数据同步。这种的方式的优点就是可以保留表的外键、事物以及其它表属性,但是缺点是查询性能比较低,同步也不够灵活,所以大多不推荐这种方式实现分表。
三、实施
一般情况下,对数据的分割需要手动根据规则创建数据表的分表,也可以自动化实现数据分表的创建,不过这里介绍手动分表的实现,选择取模分割策略,具体如下:
1、创建10张分表
CREATE TABLE t_user_info_n (
id int(10) not null,
account varchar(15) not null,
password varchar(32) not null,
nickname varchar(50) not null,
email varchar(30) not null,
address varchar(50) not null,
primary key(id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
NOTE:
请自行改变t_user_info_后的数字n(0~9)重复执行10次即可创建10张分表了,当然你也可以使用存储过程调用这个SQL语句。
2、新旧表数据复制
insert into t_user_info_n select id,account,password,
nickname,email,address fromt_user_info where id mod 10 = 1;
NOTE:
A、请自行改变t_user_info_后的数字n(0~9)重复执行10次即可创建10张分表了,当然你也可以使用存储过程调用这个SQL语句。
B、原来大表的总数据量为160万多,分割为10张表之后,每张表大概在16万多条记录,所以已经实现了均分数据了。
3、修改记录
这里修改ID为100003,如果不使用分表,那么修改时首先从160万条数据中检索这个id,然后在修改,而使用了分表之后,我们可以直接定位到t_user_info_3这张表,因为我们根据分割规则,就可以知道这条记录在这张表中,所以定位到这表之后,我们就只需要从16万多的数据表直接检索,缩小的了检索的反问,具体如下:
A、SQL
首先,先搜索下,看这条记录是否在t_user_info_3中:
SELECT id,account,nickname,email,address FROM t_user_info_3 where id=100003
执行结果:

现在我们切换一张表中查询:
SELECT id,account,nickname,email,address FROM t_user_info_4 where id=100003
执行结果:

从上面的查询中,我们已经认证了id=100003的记录只在分表t_user_info_3中。
其次,直接针对t_user_info_3修改该条数据:
update t_user_info_3 SET nickname='Jakves' WHERE id = 100003
执行结果:

最后,我们可查看下该条记录是否修改成功:
SELECT id,account,nickname,email,address FROM t_user_info_3 where id=100003
执行结果:

NOTE:
分表之后,修改数据可以大大提高效率,因为我们可以直接定位到分表进行修改,不需要再对整张大数据表检索了。
4、查询或删除记录
查询或删除记录与修改记录的过程是一样的,我们只需要通过ID的编号,来定位到指定的分表之后,如果我们要删除ID=100003这条记录,通过执行如下语句即可:
DELETE FROM t_user_info_3 WHERE id=100003
SELLECT * FROM t_user_info_3
因为实现过程和方法,与修改数据相同,这里不再赘述。
5、查询多条记录
查询多条记录也就是跨多张分表的查询,因为在查询前我们不确定要查询的数据的ID号,所以我们必须关联多张分表,但是有人会说这与全表的查询没有什么区别,其实不然。在分表中,多条记录的查询分为两种情况:
情况1:知道多条记录的ID
思路:
与上面的修改、删除及单条查询相同,先通过这些ID定位到多张分表,然后分别查询这些分表,最后将所有的结果UNION返回即可。
情况2:不知道任何记录ID
思路A:
如果数据表不是很多的时候,可以UNOIN多个分表,当然,需要对各个分表进行索引和查询优化,如果实现了数据库集群,结果会更好。
思路B:
通过建立一张字典表,该表主要记录了查询条件关键字与所属分表的对应关系,这样当输入关键字查询时,先通过关键字从该表中检索出涉及的分表,然后再针对这些分表进行查询,并返货UNION结果即可,这总办法相对A的办法更加彻底和具有可行性。
四、注意
1、主键ID号
在分表的时候,需要保证源表和多张分表的唯一ID不同,因为分表只是实现了将大表数据分摊到多个小表中,其数据必须保持一致,所以一般需要自定义一套主键生成策略(这个在后续文章介绍),不能使用自动增长的ID生成,这里暂时保证ID唯一,不使用自动增长。
2、分割策略
如何选择分割规则?答案是,需要根据实际业务的需求而定,上面介绍的几种分割策略都可以实现数据表的分割,只不过不同的分割策略的维护性和是否符合实际业务对接是很重要的,比如:有个需求,就是要根据日期进行数据的查询,此时就可以使用日期分割规则来分割数据表了。
3、自动分表
自动分表指的是有程序来实现自动化分表,而不是手动来实现分表,目前在一些语言框架中也已经出现自动分表的程序工具,不过不是很稳定,如果您有知道的稳定的类似这样的工具,请不吝分享下。
4、新增数据
因为一般情况下,分表是根据主表的ID进行分表,保证数据的不重复,所以在分表时需要先知道参与分表的记录的ID号,但是新增数据之后,才会生成ID,此时如果先在主表中生成记录,然后再同步该数据到分表中也可行,但限于小数据量,因为频繁的插入会让系统吃不消的,这里建议后台写个定时脚本来定时同步数据到分表中。
技术讨论群:
276592700(新)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











