







 本文介绍了数据预处理的基本步骤,包括导入Python的numpy、pandas和matplotlib库,读取数据,处理缺失值,进行数据明确化(如热编码),数据分割以及数据缩放。特别强调了在处理缺失值时,通常选择填充而不是直接删除。同时,文章提供了Python的完整代码示例,并指出R语言的实现类似。
本文介绍了数据预处理的基本步骤,包括导入Python的numpy、pandas和matplotlib库,读取数据,处理缺失值,进行数据明确化(如热编码),数据分割以及数据缩放。特别强调了在处理缺失值时,通常选择填充而不是直接删除。同时,文章提供了Python的完整代码示例,并指出R语言的实现类似。
前言
对于数据的预处理,没有固定的步骤。
下文写的仅仅的常规的一些小步骤。
具体的预处理,还需要根据数据以及需求来自行处理。
====================================
Python
STEP1、导入依赖包
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd把np作为numpy的缩写,后面可以直接使用np来调用各种方法。
==>
numpy系统是python的一种开源的数值计算扩展。
这种工具可用来存储和处理大型矩阵,比python自身的嵌套列表结构要高效的多。
你可以理解为凡是和矩阵有关的都用numpy这个库。
==>
matplotlib.pyplot是用来做数据的展示。也就是数据的可视化。
==>
pandas该工具是为了解决数据分析任务而创建的。pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。
pandas提供了大量能使我们快速便捷地处理数据的函数和方法。它是使python成为强大而高效的数据分析环境的重要因素之一。
========
选择好这三行代码,敲下shift+return组合键。
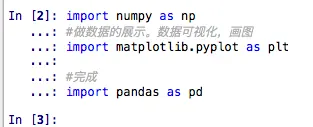
如果结果如下,说明库已经导入了。
我们的环境配置也完全没有问题。
如果环境的配置有问题,参考博客:
http://blog.csdn.net/wiki_su/article/details/78404808
STEP2、读取数据
原始数据在云盘,有需要的自行下载吧。
链接:http://pan.baidu.com/s/1eRHXACU
密码:4q8c
在Spyder中,设置好文件路径。千万不要忘了。
输入下面的代码。然后选择这行代码,敲下shift+return组合键。
#import dataset
dataset = pd.read_csv('Data.csv')我们在explorer中会看到我们命名的dataset。
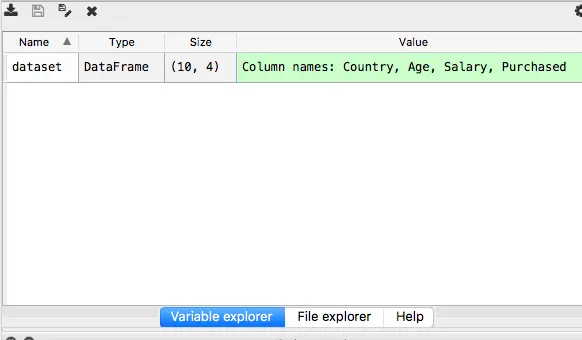
双击打开
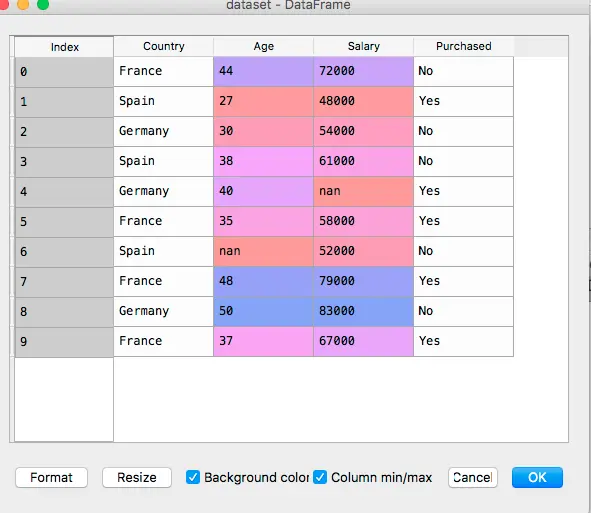
根据上面的dataset的那个图我们可以看出,我们的目的是想要通过地区,年龄,薪资来看购买力。
那我们把country,age,salary作为X,purchased作为Y。
得到二者之间的关系,就得到了country,age,salary和purchased之间的某种关系。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 821
821

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









