在做机器学习 的各种应用中,文本分类是比较典型的一种。比如,微博的分类,电商中商品评价的好坏分类,新闻的分类等等。同时,文本作为一种重要的特征,也在CTR预估,推荐等应用中起着作用。就文本分类这个应用而言,通常的做法是基于词袋模型和词向量模型来进行。基于词袋(Bag of Words)的模型的话,一般走一步TF-IDF再结合朴素贝叶斯就可以做个模型了,当然如果词很多,存在高维的问题,就用SVD/PCA做降维或者卡方特征抽取也行,然后再扔到某个分类器中。如果是基于词向量来做,那么一般就是用深度学习 的模型来进行。下面就简单说下基于开源库Deeplearning4j来进行文本情感分类的一个例子,例子在Spark1.5.2上测试 通过。10轮训练过后,准确率在92%左右。可以供相关同学参考。另外,特别说明下,本文中的语料数据来自于博客:http://spaces.ac.cn/archives/3414/。所以非常感谢链接中博客作者的数据分享。
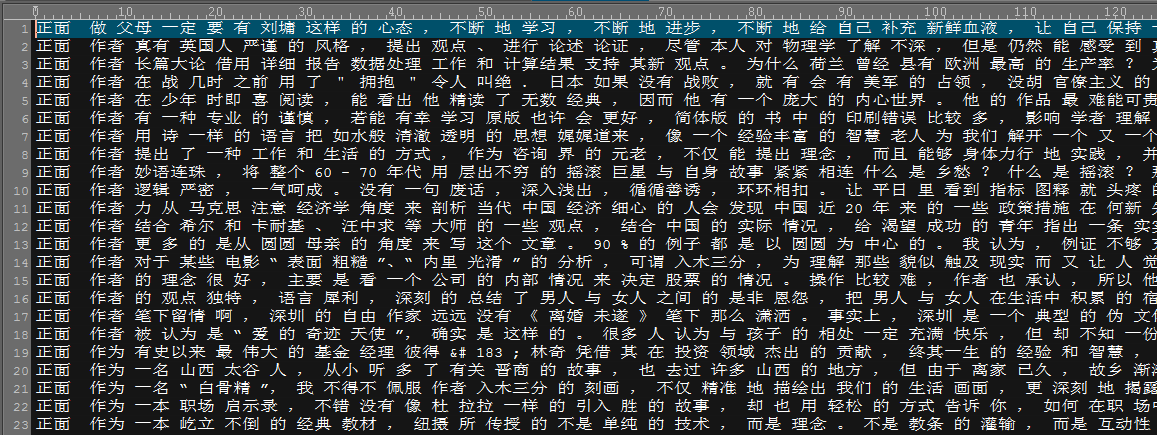
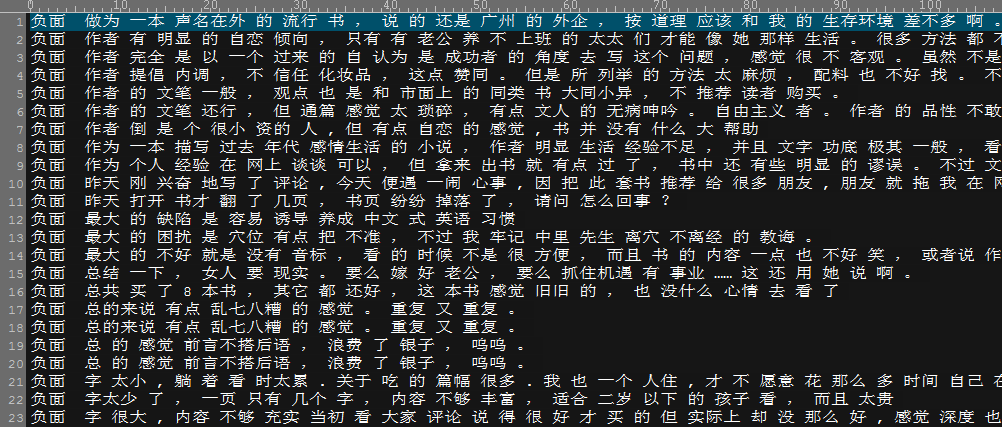
首先说下语料的处理。http://spaces.ac.cn/archives/3414/链接中的语料主要分为正、反两方面的评价文本。分别以excel文件的形式存储。从之前说的链接上down下来语料后,对正反评价的文本用jieba分词器进行分词。这里就不具体贴出处理的代码,分词器可以任意选择一个开源的。不过需要注意的是,词与词之间用空格隔开。处理的语料结果如下截图:
正面评价预料:第一列为标注
负面评价预料:第一列为标注
在处理好语料之后,就可以开始建立分类模型了。这里主要采用Embedding+LSTM的结构。优化算法 选择SGD。其他超参数如下所示:
MultiLayerConfiguration netconf = new NeuralNetConfiguration.Builder() .seed(1234 ) .iterations(1 ) .learningRate(0.1 ) .learningRateScoreBasedDecayRate(0.5 ) .optimizationAlgo(OptimizationAlgorithm.STOCHASTIC_GRADIENT_DESCENT) .regularization(true ) .l2(5 * 1e- 4 ) .updater(Updater.ADAM) .list() .layer(0 , new EmbeddingLayer.Builder().nIn(VOCAB_SIZE).nOut( 512 ).activation( "identity" ).build()) .layer(1 , new GravesLSTM.Builder().nIn( 512 ).nOut( 512 ).activation( "softsign" ).build()) .layer(2 , new RnnOutputLayer.Builder(LossFunctions.LossFunction.MCXENT) .activation("softmax" ).nIn( 512 ).nOut( 2 ).build()) .pretrain(false ).backprop( true ) .setInputType(InputType.recurrent(VOCAB_SIZE)) .build();
这里面学习率设为0.1,可以看需要调整,其他正则化项还有ADAM的更新机制也是属于可调范围的超参数。需要说明的是VOCAB_SIZE。顾名思义,就是词表的维度。由于Embedding的输入其实是一个one-hot向量,所以这个向量的维度最好和VOCAB_SIZE的差不多。Embedding输出的向量维度是自己定的,一般256,512,1024都可以试试。理论上,编码向量越长,表达能力越强,当然也耗内存。LSTM这里放了一层,当然可以根据需求做几层的堆叠,或者双向的LSTM在Deeplearning4j中也是支持的。
Map<String, Object> TokenizerVarMap = new HashMap<>(); TokenizerVarMap.put("numWords" , 1 ); TokenizerVarMap.put("nGrams" , 1 ); TokenizerVarMap.put("tokenizer" , DefaultTokenizerFactory. class .getName()); TokenizerVarMap.put("tokenPreprocessor" , CommonPreprocessor. class .getName()); TokenizerVarMap.put("useUnk" , true ); TokenizerVarMap.put("vectorsConfiguration" , new VectorsConfiguration()); TokenizerVarMap.put("stopWords" , new ArrayList<String>()); Broadcast<Map<String, Object>> broadcasTokenizerVarMap = jsc.broadcast(TokenizerVarMap); TextPipeline textPipeLineCorpus = new TextPipeline(javaRDDCorpus, broadcasTokenizerVarMap); JavaRDD<List<String>> javaRDDCorpusToken = textPipeLineCorpus.tokenize(); textPipeLineCorpus.buildVocabCache(); textPipeLineCorpus.buildVocabWordListRDD(); Broadcast<VocabCache<VocabWord>> vocabCorpus = textPipeLineCorpus.getBroadCastVocabCache(); JavaRDD<List<VocabWord>> javaRDDVocabCorpus = textPipeLineCorpus.getVocabWordListRDD();
上面这段代码需要做些说明。其实对于文本的预处理这块,Deeplearning4j是通过文本的Pipeline来支持的。当然也可以自己去处理文本,不过显然用内置的pipeline会方便很多。首先看到,我们需要定义一个TokenizerVarMap,这个是定义文本处理的各种属性,包括词最小的出现次数,分词器,未登录词等等。定义好后,通过广播变量发送到worker节点上,然后调用包装好的接口进行分词、停用词过滤等处理,最终生成的是VocabWord的RDD数据。因此通过以上pipeline的处理,就将原始文本预处理完了。另外需要说明的一点是,我是先把文本分好词传到HDFS,默认是用空格隔开,所以我分好词后也是用空格隔开的。
这里,我们只是对语料进行了处理,类似的,可以用pipeline对标注也进行处理。这里就不再赘述了。
在处理完后,我们将分词数据和语料以DataSet的形式进行包装,具体如下:
JavaRDD<DataSet> javaRDDTrainData = javaPairRDDVocabLabel.map( new Function<Tuple2<List<VocabWord>,VocabWord>, DataSet>() { @Override public DataSet call(Tuple2<List<VocabWord>, VocabWord> tuple) throws Exception { List<VocabWord> listWords = tuple._1; VocabWord labelWord = tuple._2; INDArray features = Nd4j.create(1 , 1 , maxCorpusLength); INDArray labels = Nd4j.create(1 , ( int )numLabel, maxCorpusLength); INDArray featuresMask = Nd4j.zeros(1 , maxCorpusLength); INDArray labelsMask = Nd4j.zeros(1 , maxCorpusLength); int [] origin = new int [ 3 ]; int [] mask = new int [ 2 ]; origin[0 ] = 0 ; mask[0 ] = 0 ; int j = 0 ; for (VocabWord vw : listWords) { origin[2 ] = j; features.putScalar(origin, vw.getIndex()); mask[1 ] = j; featuresMask.putScalar(mask, 1.0 ); ++j; } int lastIdx = listWords.size(); int idx = labelWord.getIndex(); labels.putScalar(new int []{ 0 ,idx,lastIdx- 1 }, 1.0 ); labelsMask.putScalar(new int []{ 0 ,lastIdx- 1 }, 1.0 ); return new DataSet(features, labels, featuresMask, labelsMask); } });
JavaRDD<DataSet>是最终的训练数据形式。这里需要说明的是,虽然理论上模型是可以处理变长的数据,但是其实在实际落地的时候,都是将所有的文本语料以最长的那条语料的长度作为每条语料的长度,然后用maskArray的方法来标注实际的有效长度。即,1为有效,默认为0,无效。以此来实现所谓的变长语料的支持。基于以上理论和之前预处理的结果,我们就构造了训练数据。
ParameterAveragingTrainingMaster trainMaster = new ParameterAveragingTrainingMaster.Builder(batchSize) .workerPrefetchNumBatches(0 ) .saveUpdater(true ) .averagingFrequency(5 ) .batchSizePerWorker(batchSize) .build(); SparkDl4jMultiLayer sparknet = new SparkDl4jMultiLayer(jsc, netconf, trainMaster); sparknet.setListeners(Collections.<IterationListener>singletonList(new ScoreIterationListener( 1 ))); for ( int numEpoch = 0 ; numEpoch < totalEpoch; ++numEpoch){ sparknet.fit(javaRDDTrainData); Evaluation evaluation = sparknet.evaluate(javaRDDTrainData); double accuracy = evaluation.accuracy(); System.out.println("====================================================================" ); System.out.println("Epoch " + numEpoch + " Has Finished" ); System.out.println("Accuracy: " + accuracy); System.out.println("====================================================================" ); } MultiLayerNetwork network = sparknet.getNetwork(); FileSystem hdfs = FileSystem.get(jsc.hadoopConfiguration()); Path hdfsPath = new Path(modelSavePath); if ( hdfs.exists(hdfsPath) ){ hdfs.delete(hdfsPath, true ); } FSDataOutputStream outputStream = hdfs.create(hdfsPath); ModelSerializer.writeModel(network, outputStream, true ); VocabCache<VocabWord> saveVocabCorpus = vocabCorpus.getValue(); VocabCache<VocabWord> saveVocabLabel = vocabLabel.getValue(); SparkUtils.writeObjectToFile(VocabCorpusPath, saveVocabCorpus, jsc); SparkUtils.writeObjectToFile(VocabLabelPath, saveVocabLabel, jsc);
这一部分是在Spark上训练以及模型的保存。具体的都在之前的文章中提及了,这里就不再赘述了。
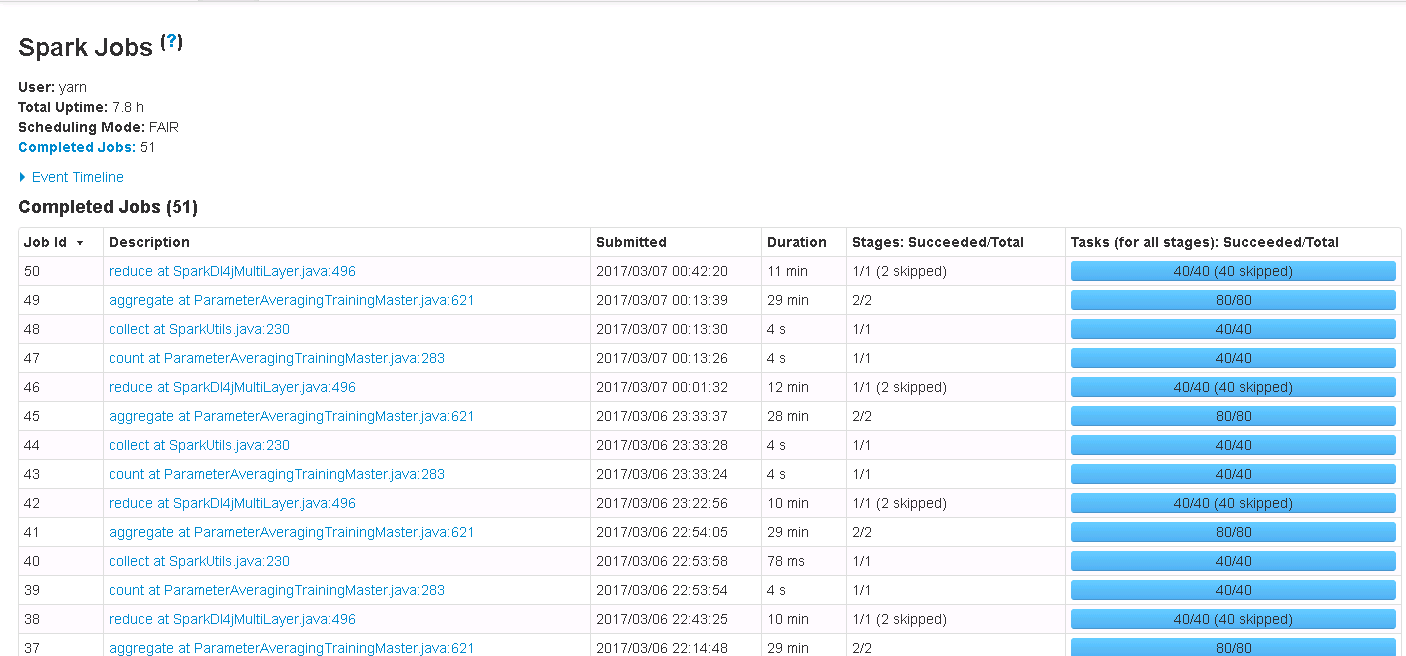
下面几张图,是具体的训练过程和结果。可以看到经过10轮左右的训练,准确率可以到达92%左右了。
最后做下小结:
我们用深度学习尝试对文本进行分类的工作,语料选择之前贴的链接里的正反评价语料,训练完的模型可以对用于的评价做出情感上的识别或者说分类判断。从本质上来讲,文本的分类也可以是多分类问题,这里我们只是以二分类为例。另外,值得一说的是,直接用字作为单元进行模型训练最终也可以取得几乎同样的效果。而且维度更低,消耗内存以及训练时间更短。当然,由于这是短文本,用字应该问题不大,但如果是长文本,那么用词应该是更合理的。
最后,再次感谢http://spaces.ac.cn/archives/3414/这篇博客的作者分享的资料和数据!

























 1665
1665











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









