







用的版本是BeautifulSoup4,用起来的确要比 re 好用一些,不用一个个的去写正则表达式,这样还是挺方便的。
比如我要获取高匿代理IP页面上的IP和端口,网址这里:点击打开链接,它的组织方式是这样的,如下图:
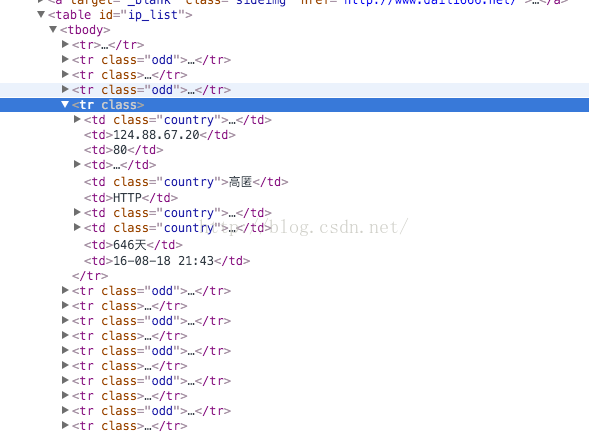
IP和端口 tr.td 标签里面,tr有class属性,属性有两种情况的值,对于这点我们可以用正则表达式来匹配下。当提取某一个标签里的具体内容时,可以用bs的 .string属性,注意:用 .string 属性来提取标签里的内容时,该标签应该是只有单个节点的。比如上面的 td 标签那样。下面直接上代码了。
import requests
from bs4 import BeautifulSoup
import re
import os.path
user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5)'
headers = {'User-Agent': user_agent}
session = requests.session()
page = session.get("http://www.xicidaili.com/nn/1", headers=headers)
soup = BeautifulSoup(page.text,'lxml') #这里没有装lxml的话,把它去掉用默认的就好
#匹配带有class属性的tr标签
taglist = soup.find_all('tr', attrs={'class': re.compile("(odd)|()")})
for trtag in taglist:
tdlist = trtag.find_all('td') #在每个tr标签下,查找所有的td标签
print tdlist[1].string #这里提取IP值
print tdlist[2].string #这里提取端口值结果如下:
124.88.67.24
80
61.224.239.71
8080
113.3.78.124
8118
61.227.228.141
8080
222.130.171.58
8118
123.57.190.51
7777
183.61.71.112
8888
120.25.171.183
8080
1.164.146.91
8080
101.201.235.141
8000
121.193.143.249
80
118.180.15.152
8102
124.88.67.19
80
。
。
。
。
。
。
。














 2608
2608











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









