






该算法由西南交通大学段凡丁老师提出,提出的时间比较早,1992年还是1993年。我应一个朋友的要求把这个算法实现了,并跟快速排序算法作了比较,发现确实是要比快速排序快。
我们都知道快速排序算法的时间复杂度是O(N*log2 N),据段老师论文中的描述,超快速排序算法可达到O(N)的效率。
我们先来看看算法的核心思想:
利用hash地址散列原理,设计散列函数H:R->S,使R[1:n]中的各个元素按照其自身的序列及分布规律快速地映射在S[1:m]空间。采用冲突元素预留地址区间法,解决重复冲突和散列失效的问题。
我按照论文的算法描述,用C++将超快速算法封装成了一个类。具体代码如下所示。
#ifndef __SupperSort_H__
#define __SypperSort_H__#include "MyTimer.h"
#include <iostream.h>template <typename T>
class SupperSort
{
public:
long g_costTime;protected:
T *m_array, *m_addr,*m_point;
int size;
public:
// 构造函数:分配相关内存空间,初始化变量
SupperSort(T *num,int n)
{
this->size = n;
this->m_array = new T[size];
memcpy(this->m_array,(void *)num,n*sizeof(T));
this->m_addr = new T[size];
memset(this->m_addr,0,size*sizeof(T));
this->m_point = new T[size];
memset(this->m_point,0,size*sizeof(T));
g_costTime = 0;
}// 核心算法:超快速排序
int Sort()
{
int i;
MyTimer timer;
timer.Start();
// 取得数组中的最大值和最小值
GetMaxMin();
if( m_max == m_min )
{
cout<< "End SupperSort" << endl;
return 1;
}
// 对冲突元素进行分组计算
for(i=1;i<size;i++)
{
int j=(m_array[i]-m_min)*(size-2)/(m_max-m_min)+1;
m_addr[j] = m_addr[j]+1;
}// 找出每个元素的散列地址区间,即散列末地址
for(i=2;i<size;i++)
m_addr[i] += m_addr[i-1];// k从n到1,依次计算源数组的散列地址区间,若该地址的m_point指针为空,说明无冲突,则将k放入m_point指针;
// 若m_point指针不空,则将k前推用插入的方法直接插入到m_point指针
for(i=size-1;i>0;i--)
{
int k=i;
int g=m_addr[(m_array[k]-m_min)*(size-2)/(m_max-m_min)+1];
while(m_point[g]!=0)
{
if( m_array[k]>m_array[m_point[g]] )
{
int t = k;
k = m_point[g];
m_point[g] = t;
}
g = g-1;
}
m_point[g] = k;
}timer.End();
g_costTime = timer.costTime;cout << "End SuperSort! Costs Time:" << g_costTime << endl;
return 0;
}// 输出最后的排序结果
void OutResult()
{
for(int i=1;i<size;i++)
{
cout << m_array[m_point[i]] << " ";
}
cout << endl;
}// 析构函数:释放相关内存
virtual ~SupperSort()
{
if( m_array )
{
delete []m_array;
m_array = NULL;
}
if( m_addr )
{
delete []m_addr;
m_addr = NULL;
}
if( m_point )
{
delete []m_point;
m_point = NULL;
}
}private:
T m_max,m_min;// 获取数组的最大值和最小值
void GetMaxMin()
{
m_max = 0;
m_min = 100000000;
for(int i=1;i<size;i++)
{
if( this->m_array[i] > m_max )
m_max = m_array[i];
if( this->m_array[i] < m_min )
m_min = m_array[i];
}
}
};#endif
上面的代码注意两点:
(1)红色的部分有可能出现问题。当数组的规模size很大,并且数也很大时,有可能超出整型描述的范围,因此在测试的时候要控制好;
(2)代码中的MyTimer类是自己写的一个计时类,可精确到微妙级别。该类的代码如下:
| #ifndef __MyTimer_H_ #include <windows.h> class MyTimer public: public: void Start() // 开始计时 void End() // 结束计时 void Reset() // 计时清0 #endif |
与超快速排序相比较的快速排序算法我也封装成了一个类,具体如下:
| #ifndef __QuickSort_H__ #include "MyTimer.h" template <typename T> public: public: // 进行快速排序 timer.Start(); timer.End(); // 输出最后的排序结果 // 析构函数:释放内存 private: // 具体实现 #endif |
具体的测试程序如下:
| #include "MyTimer.h" #define M_Size 100001 int main() QuickSort<int> qs(num,M_Size,1,M_Size-1); cout<< "-----------------------------------" << endl; SupperSort<int> ss(num,M_Size); return 0; |
注意:数组的规模为M_Size,数组元素最大值为9999。在超快速排序中,冲突元素的个数跟数据规模和数据的最大值有关系。当规模大,而最大值小时,冲突元素多,超快速排序花费时间多。
------------------------------------------- 其实我就是分割线 ----------------------------------------------------
我的机子的配置是:
CPU:Intel(R) Core(TM)2 Duo 2.0GHZ
内存:2G
系统:Windows XP
下面是具体的测试结果:
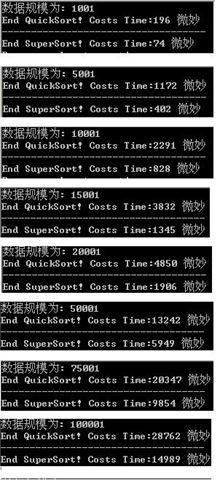















 608
608

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









