







我是在单机环境下修改下配置完成的集群模式
单机安装查看:http://blog.csdn.net/wind520/article/details/43458925
参考官网配置:http://spark.apache.org/docs/latest/spark-standalone.html
1:修改slaves配置
[jifeng@jifeng01 conf]$ cp slaves.template slaves
[jifeng@jifeng01 conf]$ vi slaves
# A Spark Worker will be started on each of the machines listed below.
jifeng02.sohudo.com
jifeng03.sohudo.com
jifeng04.sohudo.com
"slaves" 4L, 131C 已写入
[jifeng@jifeng01 conf]$ cat slaves
# A Spark Worker will be started on each of the machines listed below.
jifeng02.sohudo.com
jifeng03.sohudo.com
jifeng04.sohudo.com2:复制文件到其它节点
[jifeng@jifeng01 hadoop]$ scp -r ./spark-1.2.0-bin-hadoop1 jifeng@jifeng02.sohudo.com:/home/jifeng/hadoop/
[jifeng@jifeng01 hadoop]$ scp -r ./spark-1.2.0-bin-hadoop1 jifeng@jifeng03.sohudo.com:/home/jifeng/hadoop/
[jifeng@jifeng01 hadoop]$ scp -r ./spark-1.2.0-bin-hadoop1 jifeng@jifeng04.sohudo.com:/home/jifeng/hadoop/
[jifeng@jifeng01 hadoop]$ scp -r ./scala-2.11.4 jifeng@jifeng02.sohudo.com:/home/jifeng/hadoop/
[jifeng@jifeng01 hadoop]$ scp -r ./scala-2.11.4 jifeng@jifeng03.sohudo.com:/home/jifeng/hadoop/
[jifeng@jifeng01 hadoop]$ scp -r ./scala-2.11.4 jifeng@jifeng04.sohudo.com:/home/jifeng/hadoop/3:启动
sbin/start-all.sh- Starts both a master and a number of slaves as described above.
[jifeng@jifeng01 spark-1.2.0-bin-hadoop1]$ sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /home/jifeng/hadoop/spark-1.2.0-bin-hadoop1/sbin/../logs/spark-jifeng-org.apache.spark.deploy.master.Master-1-jifeng01.sohudo.com.out
jifeng04.sohudo.com: starting org.apache.spark.deploy.worker.Worker, logging to /home/jifeng/hadoop/spark-1.2.0-bin-hadoop1/sbin/../logs/spark-jifeng-org.apache.spark.deploy.worker.Worker-1-jifeng04.sohudo.com.out
jifeng02.sohudo.com: starting org.apache.spark.deploy.worker.Worker, logging to /home/jifeng/hadoop/spark-1.2.0-bin-hadoop1/sbin/../logs/spark-jifeng-org.apache.spark.deploy.worker.Worker-1-jifeng02.sohudo.com.out
jifeng03.sohudo.com: starting org.apache.spark.deploy.worker.Worker, logging to /home/jifeng/hadoop/spark-1.2.0-bin-hadoop1/sbin/../logs/spark-jifeng-org.apache.spark.deploy.worker.Worker-1-jifeng03.sohudo.com.out
[jifeng@jifeng01 spark-1.2.0-bin-hadoop1]$
spark集群的web管理页面访问:http://jifeng01.sohudo.com:8080/

5:启动spark-shell控制台
./spark-shell
[jifeng@jifeng01 spark-1.2.0-bin-hadoop1]$ cd bin
[jifeng@jifeng01 bin]$ ./spark-shell
Spark assembly has been built with Hive, including Datanucleus jars on classpath
15/02/04 22:11:10 INFO spark.SecurityManager: Changing view acls to: jifeng
15/02/04 22:11:10 INFO spark.SecurityManager: Changing modify acls to: jifeng
15/02/04 22:11:10 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(jifeng); users with modify permissions: Set(jifeng)
15/02/04 22:11:10 INFO spark.HttpServer: Starting HTTP Server
15/02/04 22:11:10 INFO server.Server: jetty-8.y.z-SNAPSHOT
15/02/04 22:11:10 INFO server.AbstractConnector: Started SocketConnector@0.0.0.0:57780
15/02/04 22:11:10 INFO util.Utils: Successfully started service 'HTTP class server' on port 57780.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.2.0
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_45)
Type in expressions to have them evaluated.
Type :help for more information.
15/02/04 22:11:15 INFO spark.SecurityManager: Changing view acls to: jifeng
15/02/04 22:11:15 INFO spark.SecurityManager: Changing modify acls to: jifeng
15/02/04 22:11:15 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(jifeng); users with modify permissions: Set(jifeng)
15/02/04 22:11:15 INFO slf4j.Slf4jLogger: Slf4jLogger started
15/02/04 22:11:15 INFO Remoting: Starting remoting
15/02/04 22:11:15 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkDriver@jifeng01.sohudo.com:48769]
15/02/04 22:11:15 INFO util.Utils: Successfully started service 'sparkDriver' on port 48769.
15/02/04 22:11:15 INFO spark.SparkEnv: Registering MapOutputTracker
15/02/04 22:11:15 INFO spark.SparkEnv: Registering BlockManagerMaster
15/02/04 22:11:15 INFO storage.DiskBlockManager: Created local directory at /tmp/spark-local-20150204221115-20b0
15/02/04 22:11:15 INFO storage.MemoryStore: MemoryStore started with capacity 265.4 MB
15/02/04 22:11:15 INFO spark.HttpFileServer: HTTP File server directory is /tmp/spark-6d24f541-4ce1-4e12-9be2-4296791bd73f
15/02/04 22:11:15 INFO spark.HttpServer: Starting HTTP Server
15/02/04 22:11:15 INFO server.Server: jetty-8.y.z-SNAPSHOT
15/02/04 22:11:15 INFO server.AbstractConnector: Started SocketConnector@0.0.0.0:42647
15/02/04 22:11:15 INFO util.Utils: Successfully started service 'HTTP file server' on port 42647.
15/02/04 22:11:16 INFO server.Server: jetty-8.y.z-SNAPSHOT
15/02/04 22:11:16 INFO server.AbstractConnector: Started SelectChannelConnector@0.0.0.0:4040
15/02/04 22:11:16 INFO util.Utils: Successfully started service 'SparkUI' on port 4040.
15/02/04 22:11:16 INFO ui.SparkUI: Started SparkUI at http://jifeng01.sohudo.com:4040
15/02/04 22:11:16 INFO executor.Executor: Using REPL class URI: http://10.5.4.54:57780
15/02/04 22:11:16 INFO util.AkkaUtils: Connecting to HeartbeatReceiver: akka.tcp://sparkDriver@jifeng01.sohudo.com:48769/user/HeartbeatReceiver
15/02/04 22:11:16 INFO netty.NettyBlockTransferService: Server created on 58669
15/02/04 22:11:16 INFO storage.BlockManagerMaster: Trying to register BlockManager
15/02/04 22:11:16 INFO storage.BlockManagerMasterActor: Registering block manager localhost:58669 with 265.4 MB RAM, BlockManagerId(<driver>, localhost, 58669)
15/02/04 22:11:16 INFO storage.BlockManagerMaster: Registered BlockManager
15/02/04 22:11:16 INFO repl.SparkILoop: Created spark context..
Spark context available as sc.
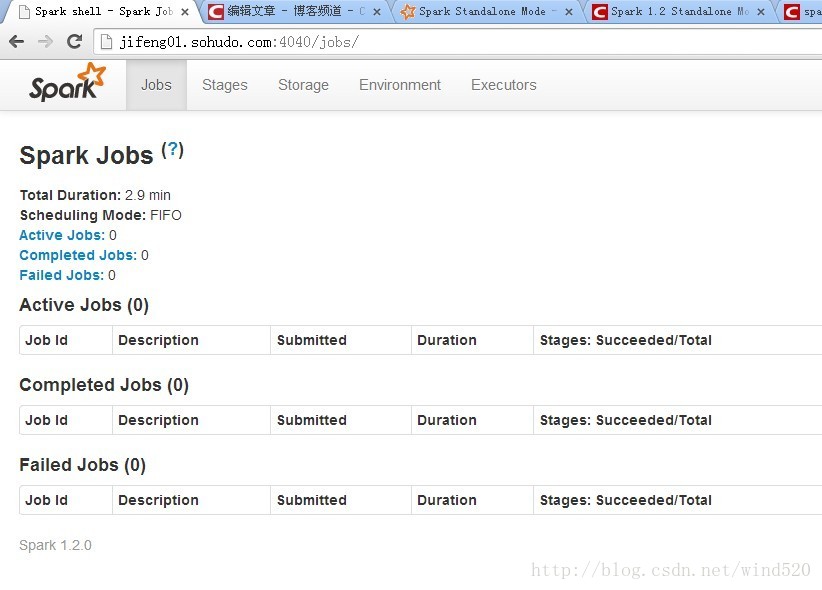
scala>6:Spark shell管理页面
进入后还可打开访问web控制页面,访问http://jifeng01.sohudo.com:4040/
7:测试
输入命令:
val file=sc.textFile("hdfs://jifeng01.sohudo.com:9000/user/jifeng/in/test1.txt")
读取文件
val count=file.flatMap(line=>line.split(" ")).map(word=>(word,1)).reduceByKey(_+_)
统计单词数量
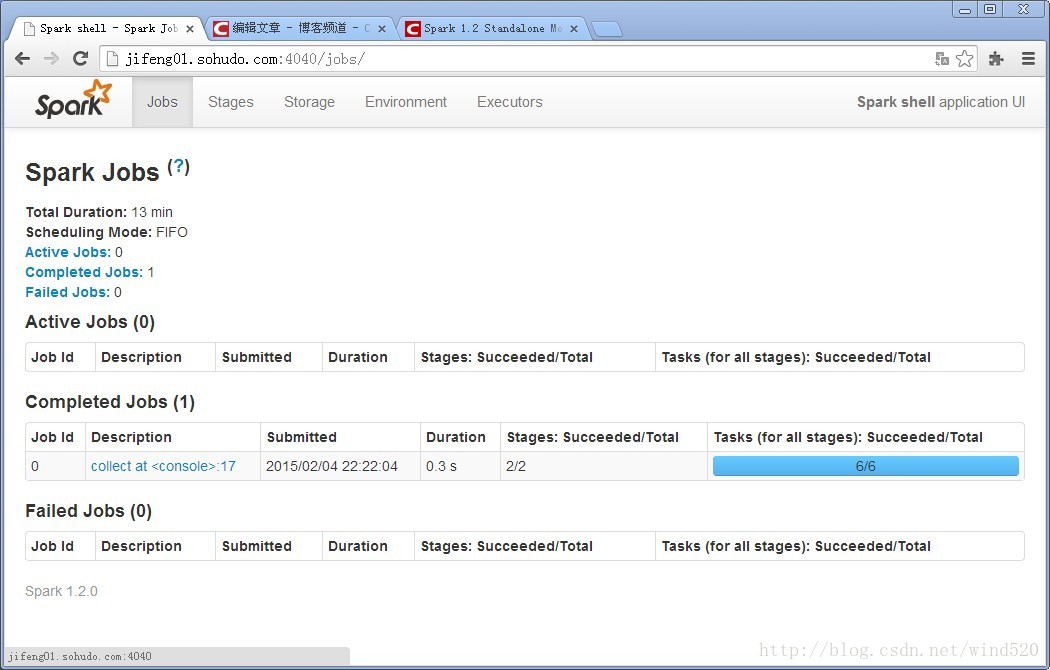
count.collect()
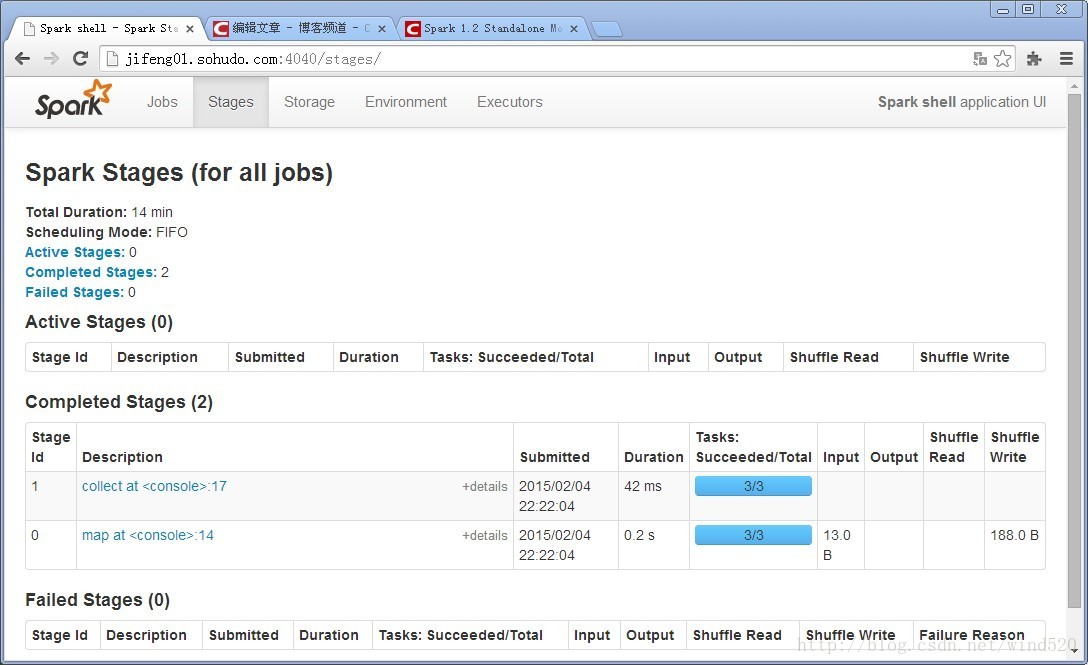
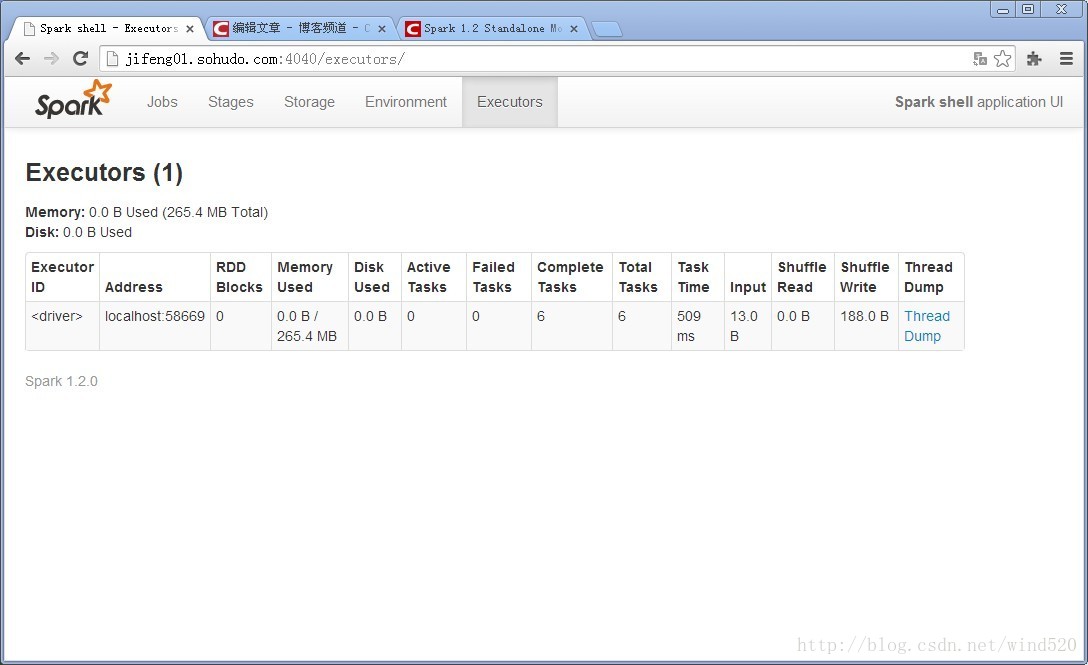
8:查看执行结果
9:退出shell
:quit
scala> :quit
Stopping spark context.
15/02/04 22:28:51 INFO handler.ContextHandler: stopped o.e.j.s.ServletContextHandler{/stages/stage/kill,null}
15/02/04 22:28:51 INFO handler.ContextHandler: stopped o.e.j.s.ServletContextHandler{/,null}
15/02/04 22:28:51 INFO handler.ContextHandler: stopped o.e.j.s.ServletContextHandler{/static,null}
15/02/04 22:28:51 INFO handler.ContextHandler: stopped o.e.j.s.ServletContextHandler{/executors/threadDump/json,null}
15/02/04 22:28:51 INFO handler.ContextHandler: stopped o.e.j.s.ServletContextHandler{/executors/threadDump,null}
15/02/04 22:28:51 INFO handler.ContextHandler: stopped o.e.j.s.ServletContextHandler{/executors/json,null}
15/02/04 22:28:51 INFO handler.ContextHandler: stopped o.e.j.s.ServletContextHandler{/executors,null}
15/02/04 22:28:51 INFO handler.ContextHandler: stopped o.e.j.s.ServletContextHandler{/environment/json,null}
15/02/04 22:28:51 INFO handler.ContextHandler: stopped o.e.j.s.ServletContextHandler{/environment,null}
15/02/04 22:28:51 INFO handler.ContextHandler: stopped o.e.j.s.ServletContextHandler{/storage/rdd/json,null}
15/02/04 22:28:51 INFO handler.ContextHandler: stopped o.e.j.s.ServletContextHandler{/storage/rdd,null}
15/02/04 22:28:51 INFO handler.ContextHandler: stopped o.e.j.s.ServletContextHandler{/storage/json,null}
15/02/04 22:28:51 INFO handler.ContextHandler: stopped o.e.j.s.ServletContextHandler{/storage,null}
15/02/04 22:28:51 INFO handler.ContextHandler: stopped o.e.j.s.ServletContextHandler{/stages/pool/json,null}
15/02/04 22:28:51 INFO handler.ContextHandler: stopped o.e.j.s.ServletContextHandler{/stages/pool,null}
15/02/04 22:28:51 INFO handler.ContextHandler: stopped o.e.j.s.ServletContextHandler{/stages/stage/json,null}
15/02/04 22:28:51 INFO handler.ContextHandler: stopped o.e.j.s.ServletContextHandler{/stages/stage,null}
15/02/04 22:28:51 INFO handler.ContextHandler: stopped o.e.j.s.ServletContextHandler{/stages/json,null}
15/02/04 22:28:51 INFO handler.ContextHandler: stopped o.e.j.s.ServletContextHandler{/stages,null}
15/02/04 22:28:51 INFO handler.ContextHandler: stopped o.e.j.s.ServletContextHandler{/jobs/job/json,null}
15/02/04 22:28:51 INFO handler.ContextHandler: stopped o.e.j.s.ServletContextHandler{/jobs/job,null}
15/02/04 22:28:51 INFO handler.ContextHandler: stopped o.e.j.s.ServletContextHandler{/jobs/json,null}
15/02/04 22:28:51 INFO handler.ContextHandler: stopped o.e.j.s.ServletContextHandler{/jobs,null}
15/02/04 22:28:51 INFO ui.SparkUI: Stopped Spark web UI at http://jifeng01.sohudo.com:4040
15/02/04 22:28:51 INFO scheduler.DAGScheduler: Stopping DAGScheduler
15/02/04 22:28:52 INFO spark.MapOutputTrackerMasterActor: MapOutputTrackerActor stopped!
15/02/04 22:28:52 INFO storage.MemoryStore: MemoryStore cleared
15/02/04 22:28:52 INFO storage.BlockManager: BlockManager stopped
15/02/04 22:28:52 INFO storage.BlockManagerMaster: BlockManagerMaster stopped
15/02/04 22:28:52 INFO spark.SparkContext: Successfully stopped SparkContext
15/02/04 22:28:52 INFO remote.RemoteActorRefProvider$RemotingTerminator: Shutting down remote daemon.
15/02/04 22:28:52 INFO remote.RemoteActorRefProvider$RemotingTerminator: Remote daemon shut down; proceeding with flushing remote transports.
15/02/04 22:28:52 INFO remote.RemoteActorRefProvider$RemotingTerminator: Remoting shut down.
[jifeng@jifeng01 bin]$ 10:停止集群
sbin/stop-all.sh














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









