








如果配置好分词,它会智能分词,对于一些特殊的词句,可能不会分成你想要的词
比如这么一句话,“清池街办新庄村”,配置好分词后,会有如下的结果:
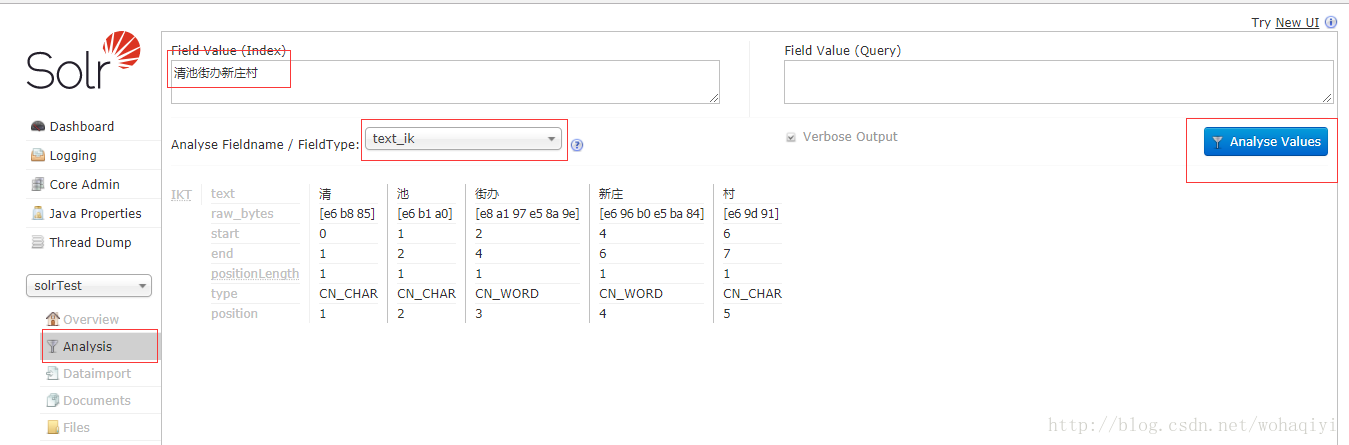
分词后的结果,并没有你想要的“清池街办新庄村”的这个词,这种情况就需要配置自定义的扩展词库了。
扩展词库的配置很简单,具体步骤如下:
1.前提是你要先配置好分词,分词的配置在上一篇博客中写到搜索引擎solr系列—solr分词配置
2.然后找到你的运行solr的tomcat,找到它下边的webapps/solr/WEB-INF/classes文件夹,打开里边应该已经有了一个log4j.properties(当然如果你在以前,把log4j.properties文件放到了lib文件夹中,那需要新建一个classes文件夹,放进去)在classes 文件夹中新建三个文件,命名分别为IKAnalyzer.cfg.xml 、ext.dic、stopword.dic 具体的下载地址三个配置文件的下载位置
IKAnalyzer.cfg.xml 文件即配置ext.dic和stopword.dic两个字典库的位置。具体配置如下:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典,多个以分号隔开 -->
<entry key="ext_dict">ext.dic;</entry>
<!--用户可以在这里配置自己的扩展停止词字典,多个以分号隔开-->
<entry key="ext_stopwords">stopword.dic;</entry>
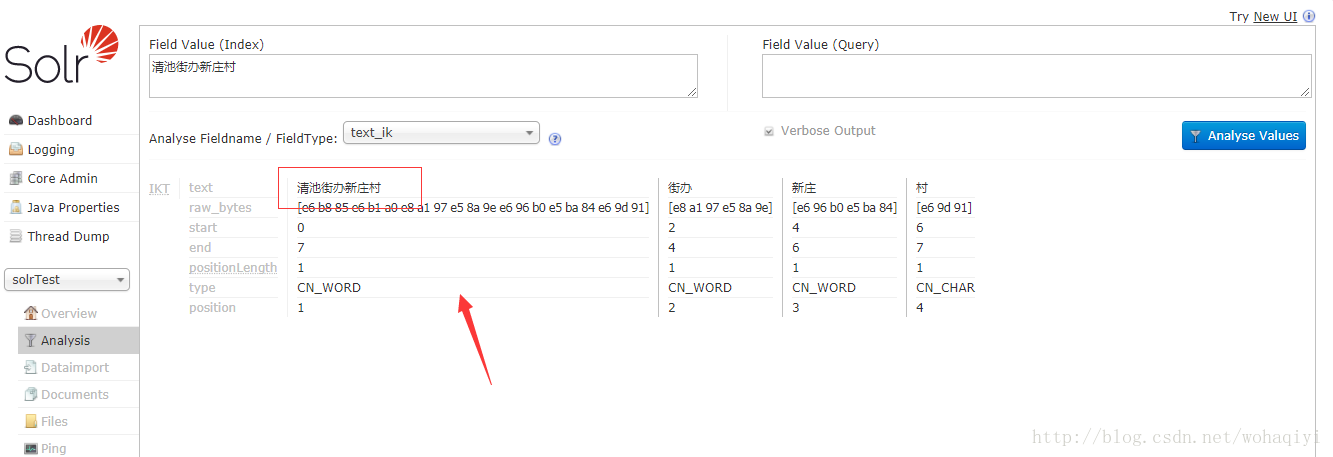
</properties>ext.dic即扩展词库的存储文件,比如我打算建立一个词“清池街办新庄村”这样一个词,那打开该文件,在里边新添一个即可:
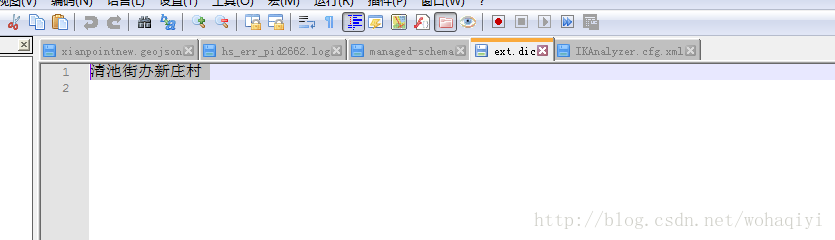
添加的每个词都自己占一行就可以的。
stopword.dic停止词字典的配置,你可以将空格什么的填进去,这里不用这个字典配置。















 158
158











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











