







http://blog.csdn.net/u013970991/article/details/73195907
其中微服务的数据去中心化核心要点是:
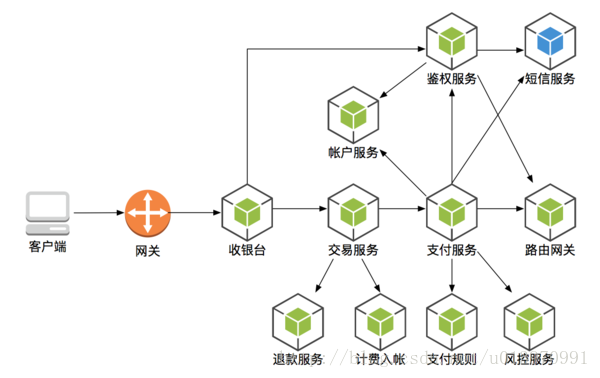
- 每个微服务有自己私有的数据库持久化业务数据。
- 每个微服务只能访问自己的数据库,而不能访问其它服务的数据库。
- 某些业务场景下,需要在一个事务中更新多个数据库。这种情况也不能直接访问其它微服务的数据库,而是通过对于微服务进行操作。
- 数据的去中心化,进一步降低了微服务之间的耦合度。
1、以前团队一共就10个人只负责一二个项目,现在突然增加到平均每人维护二三个项目,上线还是采用由运维手工打war包上线,如果有修改的配置文件,则运维同学一台一台的进行修改,不仅容易上线出错,而且每次上线都会搞到半夜。
2、根据上面提到的数据去中心化原则,数据库拆分出来了,一个服务一个数据库实例,但是对后台统计系统来说就是恶梦,数据库拆分出来了统计工作、报表工作该怎么办呢?这部分工作还做不做呢?有人说可以分开统计啊,一个库一个库的来,可是这样的工作量将是巨大的。
3、机房的双活问题,对于金融公司来说双活还是很关键的一项技术指标,对于应用双活来说,其实还是比较容易实现,但是对于数据库来说确是一个技术问题了,对于oracle数据库来说,用oracle官方提供的OGG(Oracle GoldenGate)来进行数据同步的话,根据论坛上面查看的资料可以看出,OGG坑非常多,而且也容易丢数据,更重要的是贵。。。采用oracle的logminer来进行同步,同步的数据将不是实时的,会有一定延时而且在定时读取方面的工作上还需要自己进行开发,采用oracle的DataGuard也只能做主从同步,却不能做主主双活。于是通过调研过后,最终还是决定自己独立开发。
4、使用Dubbo或者Spring cloud就是微服务了吗?好吧,使用了Dubbo以后发现还有非常多的工作需要做,Dubbo只是一个服务治理框架而已,还需要开发分布式调用监控系统、统一配置管理中心,统一定时调度,还要在每个服务中做防重幂等,还要做并发限流,缓存也要根据不同的服务做隔离等等工作。。。
那我们用Spring cloud做一个大一统的整合可以吗?于是看到Spring cloud原来有这些坑啊:
- 注册IP问题
早期的Spring Cloud Eureka在注册获取网卡IP时,不能区分外网网卡和内网网卡,如果安装了虚拟机和docker也不能区分虚拟网卡,每次启动注册的IP都有可能不一样,如果要注册为外网网卡IP,那运行带宽就不够,这个bug应该说是比较严重的问题,因此重写了网卡IP获取的逻辑来解决,同时也反馈给了spring cloud团队,再后期的版本中添加了网卡接口排序和通过名称过滤的功能来得到解决。
- HealthCheck的问题
在一些极小概率的情况下,会导致Eureka Server 下线微服务实例,出现“Remote status from Eureka server is down”的问题,即便是重启微服务也无济于事,不过已经有码友在spring cloud 官方github贴出了解决方法的issue。
- Feign使用不当带来的性能问题
其他的小坑也就忍了,大坑却不能。。。。于是去各大社区讨论发现原来大家都对Cloud的不少组件进行了二次封装。。。














 2632
2632











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









