









1. 定义
在有向图G中,如果两个顶点vi,vj有一条从vi到vj的有向路径,同时还有一条从vj到vi的路径,则称两个顶点强连通。如果有向图G中的每对顶点都强连通,称G是一个强连通图。有向图的极大强连通子图,称为强连通分量。
2. 求解
(1) 按照深度优先(DFS)遍历图G。遍历时图中每个顶点获得一个记录“x/y”,其中x表示第一次访问到该顶点时的序号,y表示从该顶点离开时的序号。
(2) 按照每个顶点的记录的后一个元素(y)对图中的顶点进行降序排序,排序结果R。
(3) 以R中的当前第一个元素开始逆序遍历图G,逆序遍历到的顶点(在R中的顺序在逆序访问的开始结点之后)与该顶点本身构成强连通分量。
(4) 删除(3)中求出的强连通分量,继续执行(3),直到R为空。
注:(3)中的实现需要先求出图G的逆图GT,然后在逆图中按照R顺序执行深度优先遍历即可。
3. 举例说明
(1) 如图2-1所示,每一个顶点上都标出了第一次深度优先遍历时得到的记录。例如顶点c对应的记录“1/10”表示访问c时序号为1,结束时为10。
(2) 按照每个顶点的结束序号对顶点排序后结果R={b, e, a, c, d, g, h, f}。
(3) 当前R中第一个元素为顶点b,逆序遍历可得能够到达b的顶点为a和e,则{b, e, a}构成强连通分量。
(4) 当前R中第一个元素为顶点c,易得能够到达c的顶点为d(虽然b也能到c,但在R中b在c前边,因此b不是),则{c, d}构成强连通分量;
(5) 同理可得{g, f}与{h}也构成强连通分量。
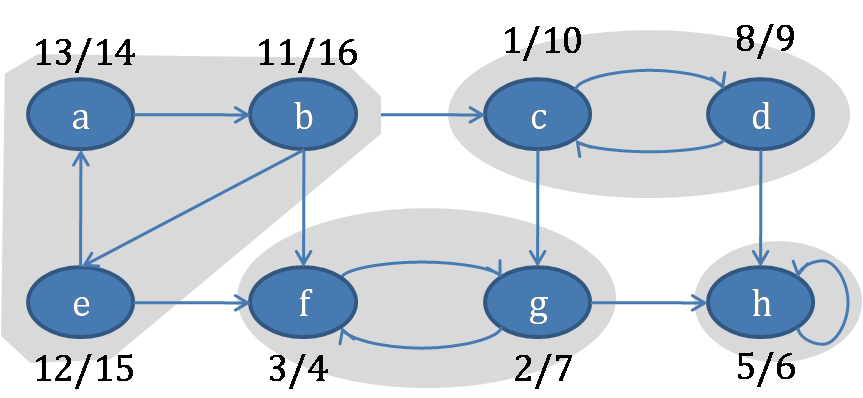
图2-1
4. 正确性
即说明为什么两次深度优先遍历就可以得到强连通分量。
根据上述的求解过程,易得对于R中的第一个元素m后边的所有顶点可以分为两类:m能够到达与m不能够到达的。在过程步骤3)中以逆序遍历得到的顶点中必是m能够到达的。因为如果是m不能够到达且能够到达m的其在R中的顺序必在顶点m之前。如图4-1所示,对于顶点b与e来说,无论从b或者e开始遍历都有顶点e的结束标记大于顶点b。
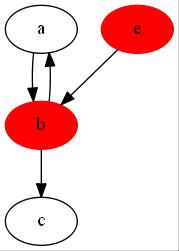
图 4-1
5. 代码说明
1. 开发环境:vs2010,语言:c++。
2. 用Kosaraju算法实现了强连通分量的求解。其中data中包含的GoolNodes测试集为Google提供的网页之间的连接经转化而来,每一个结点均代表一个网页。
3. 缺点:为了使用以前的CGraph类,强行添加了结点文件,其中第一行为结点总数,其他行均为三列:第一列表示网页编号,后两列不代表任何信息。边文件中,每行表示一条有向边,第三列权重不表示任何信息。
代码下载地址:http://download.csdn.net/detail/woniu317/7193095














 1399
1399











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









