







PS:第一次用markdown编辑器来编辑,发现它真是其乐无穷啊。嘿嘿,谁用谁知道@-@
1. XML是什么
- XML 指可扩展标记语言(EXtensible Markup Language)
- XML 被设计用来结构化、存储以及传输信息。
- XML 的设计宗旨是传输数据,而非显示数据,HTML被设计来显示数据,二者不可相互替代
- XML 标签没有被预定义。您需要自行定义标签。
- XML 没什么特别的。它仅仅是纯文本而已。有能力处理纯文本的软件都可以处理 XML。
这里先给出一个XML文件,下面的讲解以此为例来说明
<?xml version="1.0" encoding="UTF-8"?>
<product wangke="king">
<car>
<name>Lamborghini</name>
<number>鄂A:88888</number>
<firm name="Automobili">
<address>意大利圣亚加塔·波隆尼</address>
<value>10billion</value>
</firm>
<birthday>2017</birthday>
<lifeSpan>20</lifeSpan>
</car>
<car>
<name>Ferrari</name>
<number>鄂A:99999</number>
<firm name="恩佐·法拉利">
<address>意大利马拉内罗</address>
<value>30billion</value>
</firm>
<birthday>2018</birthday>
<lifeSpan>30</lifeSpan>
</car>
</product>2.Java中的XML描述对象
1.Node
Node接口是最基本的一个接口,相当于Java中的Object对象,其他所有的XML组成元素都继承自这个接口。这个接口主要用来描述XML其他所有组成元素的公共属性和公共操作。
Node中有很多static short类型的字段,这些字段表示某一个节点具体是什么类型的Node。比如,若该节点是一个Element,则类型为ELEMENT_NODE;若该节点是一个Text,则类型为TEXT_NODE。
2.Element
Element接口用来描述XML中的一个元素,可以理解为HTML中的一个标签,如示例中的
<name>Ferrari</name>3.Text
Text接口继承自CharacterData,并且表示Element或Attr的文本内容(在XML中称为字符数据),如果元素的内容中没有标记,则文本是一个Text类型的对象中。否则将继续对文本进行解析。
4.Attr
Attr表示Element对象中的属性,由于它不是它们描述元素的子节点,DOM不会将它们作为文档树的一部分,所以Node属性的parentNode,previousSibling和nextSibling作用于Attr对象时返回null。
如下,这个节点中的name=”Automobili”就是一个Attr类型的Node。
<firm name="Automobili">5.Document
表示整个XML文档,它是文档树的根,并提供对文档数据的基本访问。
6.Root节点
其实Java中没有描述根节点,因为根节点也是一个Element,每个XML文档中有且仅有一个根节点,就是包裹在最外层的Element。很多解析XML的框架都有document.getRootElement()方法,返回的就是一个根节点。Java API自带的org.w3c.dom 中document.getFirstChild(),也是返回根节点。
特别注意:每个Element的前后都有一个Text类型的Node,不要以为上下两个Element之间有换行,没有任何文本,就以为它们之间没有Node,以下图为例:
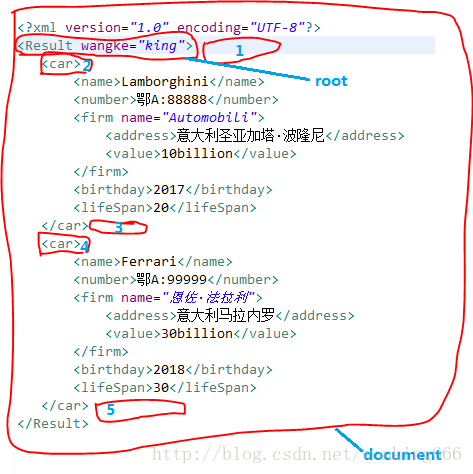
进一步挖掘这句话可以得出一个结论:任何一个Element,调用其getFirstChild()都将返回一个Text类型的Node。(尽管它可能在视觉上表现为一个换行)
Node root=document.getFirstChild();
NodeList nodes=root.getChildNodes();
System.out.println(nodes.getLength()); //输出子节点个数为5,而不是2
root.getFirstChild.getNextSibling(); //这样才返回第一个car元素还需要特别注意Node中的如下三个属性和对应的get方法,nodeName,nodeValue,attributes
W3C上是这样说明的:
属性nodeName,nodeValue,attributes作为一个获取节点信息的机制,无需向下强制转换为特定的派生接口,在没有对特定的nodeType(如Element的nodeValue或Comment的attributes)的属性进行显式映射的情况下,这将返回null。注意,特定的接口可能包含其他更方便的机制来获取和设置相关信息。
上面的话可以这样简单来理解:某一种类型的node若没有特殊实现其getNodeValue()(或者getAttributes()等方法),默认返回null。但需要注意的是,一个node一定有类型和名称,所以getNodeType()和getNodeName()是一定有返回值的。
举个栗子:如果一个Node是Text类型,则getNodeValue()返回其文本内容,否则返回null,因为只有Text类型的Node实现了getNodeValue()方法(也就是说,getNodeValue()方法只能获取到Text类型的Node中的数据)
下面是本人写的一个简单的递归遍历所有的Text类型的Node(原谅我的懒,最近实在项目缠身。日后一定抽空完善),在此基础上加工一下就可以实现从XML中解析出一个Java实体类。
public static void ergodic(Node node,Map<String, String> map){
if(node.getNodeType()==Node.TEXT_NODE){
System.out.println(node.getParentNode().getNodeName()+":"+((Text)node).getWholeText());
return;
}
NodeList list=node.getChildNodes();
for(int i=0;i<list.getLength();++i){
ergodic(list.item(i), map);
}
}四种(框架)解析方法正在更新中……














 216
216











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









