







沃趣科技 熊中哲
随着交流机会的增多(集中在金融行业,规模都在各自领域数一数二),发现大家对 Docker + Kubernetes 的接受程度超乎想象, 并极有兴趣将这套架构应用到 RDS 领域。数据库服务的需求可以简化为:
实现数据零丢失的前提下,提供可接受的服务能力。
因此存储架构的选型至关重要。到底是选择计算存储分离还是本地存储?
本文就这个问题,从以下几点展开:
回顾:计算存储分离, 本地存储优缺点
MySQL 基于本地存储实现数据零丢失
性能对比
基于 Docker + Kubernetes 的实现
来分享个人理解。
计算存储分离
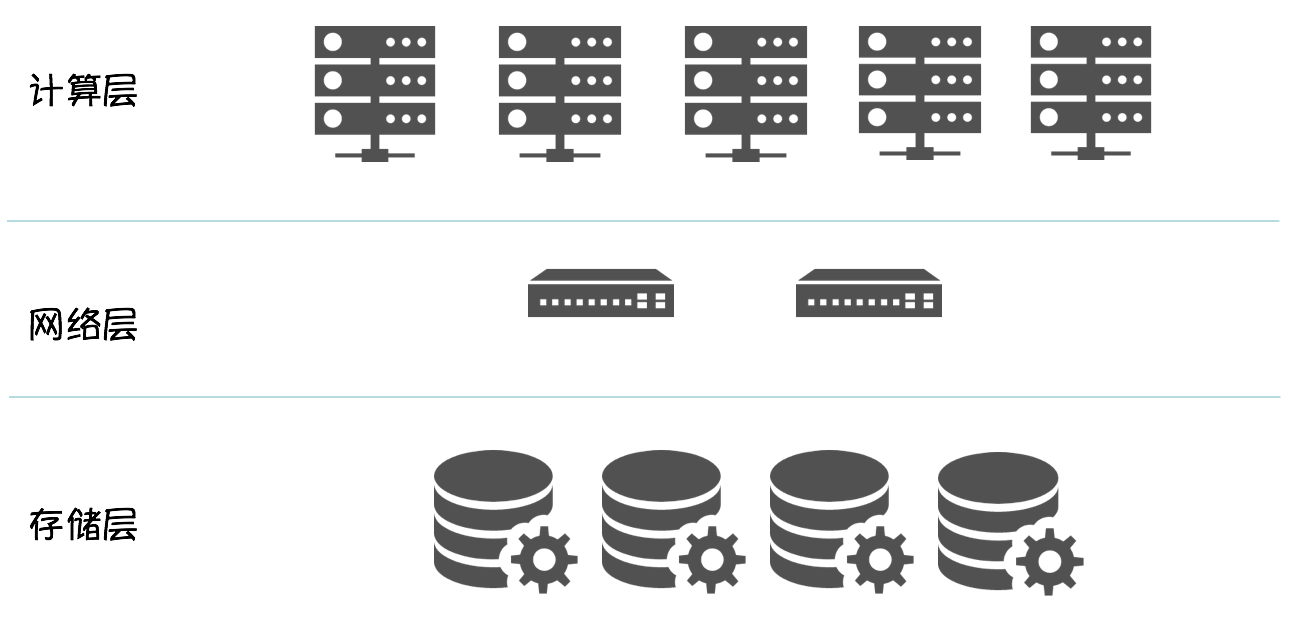
先说优点:
架构清晰
计算资源 / 存储资源独立扩展
提升实例密度,优化硬件利用率
简化实例切换流程:将有状态的数据下沉到存储层,Scheduler 调度时,无需感知计算节点的存储介质,只需调度到满足计算资源要求的 Node,数据库实例启动时,只需在分布式文件系统挂载 mapping volume 即可。可以显著的提高数据库实例的部署密度和计算资源利用率。
以 MySQL 为例
通用性更好,同时适用于 Oracle、MySQL,详见:《容器化RDS——计算存储分离架构下的"Split-Brain"》。
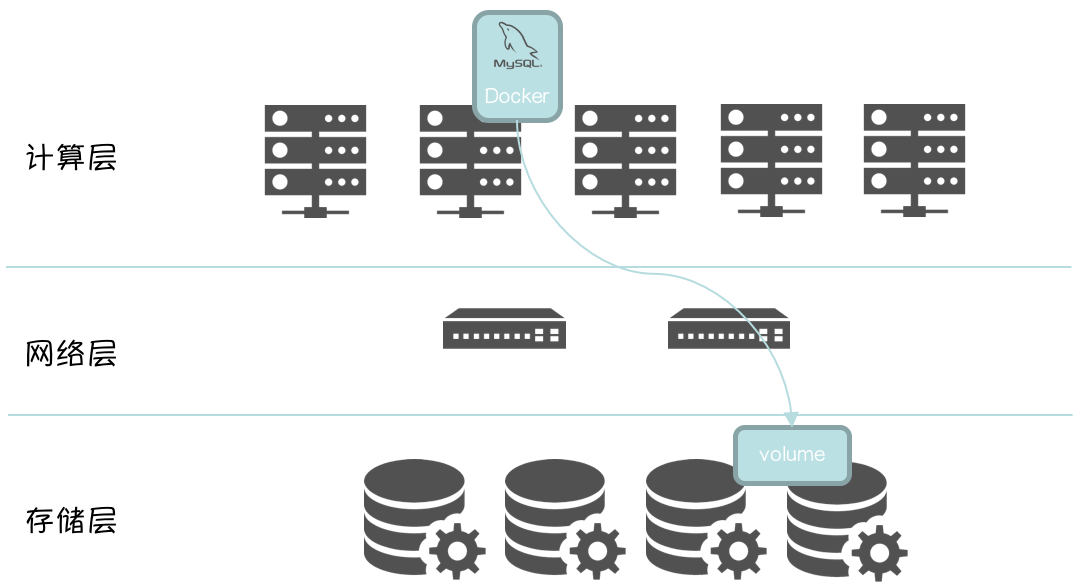
从部分用户的上下文来看,存在如下客观缺点:
引入分布式存储,架构复杂度加大。一旦涉及到分布式存储的问题,DBA 无法闭环解决。
分布式存储选型:
选择商用,有 Storage Verdor Lock In 风险。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 727
727

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









