







先执行以下一小段代码:
public static void main(String[] args) {
String name = "LinDa";
String name2 = "LinDa";
String name3 = new String("LinDa");
String name4 = "Lin"+"Da";
String name5 = "Lin";
String name6 = "Da";
String name7 = name5+name6;
Integer iName = 2;
Integer iName2 = 2;
Integer iName3 = new Integer(2);
int a = 2;
System.out.println(name==name2);
System.out.println(name==name3);
System.out.println(name==name4);
System.out.println(name4==name7);
System.out.println(iName==iName2);
System.out.println(iName==iName3);
System.out.println(a==iName2);
System.out.println(a==iName3);
}输出结果为
true
false
true
false
true
false
true
true我们先了解下java的内存分配(只列出我们涉及到的):

再看下面一组图(不管正确与否,下图可以帮我们理解机制):
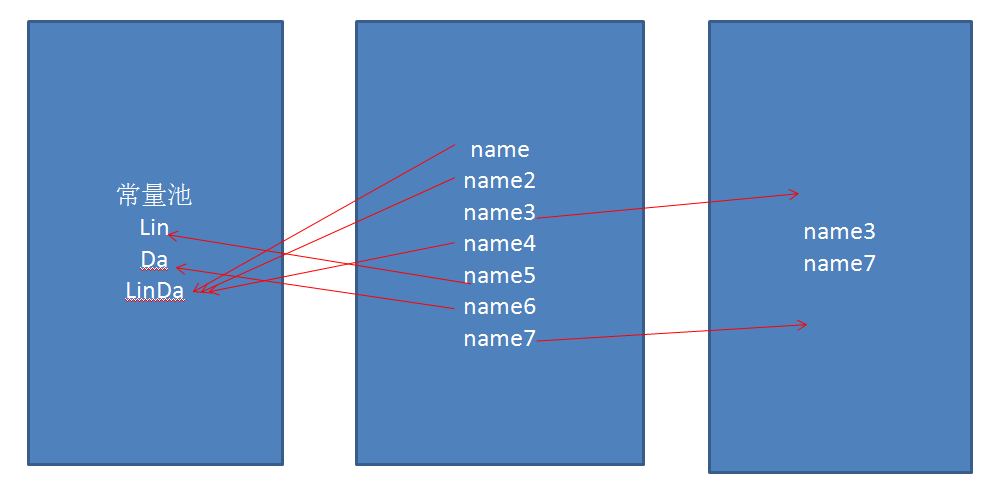
我们这样理解如果是字符串以”“形式拼接,我们可以认为它属于半个原生(基础)数据类型,我们将它的声明方式认为与基础数据类型一致;
每次定义相当于将引用指向常量池中的常量;(name,name2,name4,name5,name6都属于这种形式);
其中不一样的是name4因为JDK中关于String有这么一句介绍;
Strings are constant; their values cannot be changed after they are created. 凡是已经赋值的String它们的值就不会再改变了,在name4中使用到了”Lin”,”Da”,因为常量池中事先没有这两个常量所以常量池必须先定义这两个常量才能使用它,因为凡是用+拼接的String,拼接多少次常量池就要定义多少个其中不重复的常量;所以拼接会浪费一部分的内存;
而name3和name7使用new和引用的集合方式就相当于重新生成了一个对象,而对象都存放于堆中,那么它们的引用就指向了堆中的对象,这种方式适用于基础类型的封装类和其他Object类型;而第一种常量相加方式则试用于基础数据类型;
因此我们可以说String既可以被认为是基础数据类型又可以认为是Object类型;唯一不同的是基础数据类型的==操作比较的是值是否相等;而它的封装类型则和String的一样;















 2112
2112

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









