







一、假设函数
当处理分类问题时,尤其是二分类问题,应该限定预测的结果为
0⩽y⩽1
,所以需要一个分类函数把结果正好限定在[0,1]内,逻辑函数
g(z)=11+e−z
正是这样的一个函数
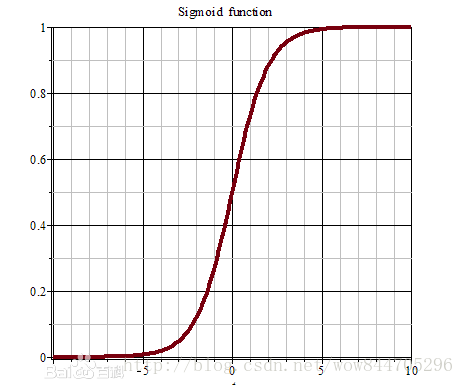
如果我们假设
z=θTx
,那么
现在 h(x) 对于任何样本的预测值都是一个介于0,1之间的值,如果 h(x)=0.7 ,我们就可以说 P(y=1|x;θ)=0.7 ,意思就再说在预测参数为 θ 的情况下样本x为1的概率为0.7,相应的预测值为0的概率为0.3。
二、决策边界
从上面所讲的我们可以知道,当
θTx⩾0
时,
hθ(x)
>0.5。
如果我们定义
hθ(x)⩾0
的样本因为它的
P(y=1|x;θ)⩾0.5
,所以我们把这样的样本分类为1,
<0
<script type="math/tex" id="MathJax-Element-210"><0</script>的样本分类为0,那么
θTx=0
恰好就像一个边界将样本分成两个部分,从而实现了分类任务。
当
θTx
是一个一次方程的时候,恰好是一个直线。但是有时候样本并不是一条直线可以划分的,这时候我们就可以采用类似线性回归的办法,采用多项式的办法。如
θTx=θ0+θ1x1+θ2x2+θ3x21+θ4x22
,我们令
θ=[−1,0,0,1,1]
`那么`
θTx=−1+x21+x22
,这时候的决策边界就是一个圆,同理我们可以设计更复杂的决策边界适应更复杂的样本。但是不管什么样的决策边界,最后决定他形状的是参数$\theta$。
三、成本函数
这里不能采用与线性回归相同的函数,因为运用到逻辑回归,会成波状函数,有许多局部最小值。我们可以采用类似的函数:
因为当y=1的时候,cost函数的图像如图所示:
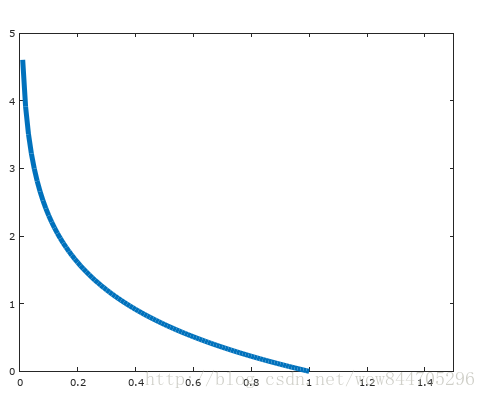
从图我们可以看出当 h(x) 趋近于y的时候,Cost函数值越小,趋近于0的时候则是无穷大。同理y=0的情况下也是。
我们可以把两个Cost函数合二为一:
如果用向量表示:
四、梯度下降
可以看出是和线性回归相同的,不同的是这里的 hθ(x) 和线性回归不同。
用向量表示:
五、高级优化
“Conjugate gradient”, “BFGS”, and “L-BFGS” 是三种比梯度下降速度更快但是更加复杂的算法去优化
θ
,我们比不需要写出这三种算法,直接调用现成的库就可以了。为了使用这些现成库我们首先要计算:
J(θ)
`和`
∂∂θjJ(θ)
。对此我们可以专门写一个函数:
function [jVal, gradient] = costFunction(theta)
jVal = [...code to compute J(theta)...];
gradient = [...code to compute derivative of J(theta)...];
end接下来我们选用一种优化算法作为options,然后用fminunc()函数去实现优化。
options = optimset('GradObj', 'on', 'MaxIter', 100);
initialTheta = zeros(2,1);
[optTheta, functionVal, exitFlag] = fminunc(@costFunction, initialTheta, options);六、多分类问题
上面谈的只是二分类问题,当处理多分类的时候,
y=(0,1,2,3...n)
,我们就可以把它转化成n+1个二分类问题。














 1115
1115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









