







全随机写无疑是最慢的写入方式,在logic dump测试中很惊讶的发现,将200M的内存数据随 机的写入到100G的磁盘数据里面,竟然要2个小时之多。原因就是虽然只有200M的数据,但实际上却是200万次随机写,根据测试,在2850机器上, 这样完全的随机写,r/s 大约在150~350之间,在180机器上,r/s难以达到250,这样计算,难怪需要2~3个小时之久。
如何改进这种单线程随机写慢的问题呢。一种方法就是尽量将完全随机写变成有序的跳跃随机写。实现方式,可以是简单的在内存中缓存一段时间,然后排序,使得在 写盘的时候,不是完全随机的,而是使得磁盘磁头的移动只向一个方向。根据测试,再一次让我震惊,简单的先在内存中排序,竟然直接使得写盘时间缩短到1645秒,磁盘的r/s也因此提升到1000以上。写盘的速度,一下子提高了5倍。
一个需要注意的地方,这种跳跃写对性能的提升,来至与磁头的单方向移动,它非常容易受其他因素的影响。测试中,上面提到的测试是只写block文件, 但如果在每个tid的处理中再增加一个写index的小文件。虽然如果只写index小文件,所用时间几乎可以忽略,但如果夹杂在写block文件中间的 话,对整体的写性能可能影响巨大,因为他可能使得磁盘的磁头需要这两个地方来回跑。根据测试,如果只写index文件,只需要300s就可以写完所有 200万个tid,单如果将写索引和写block放在一起,总时间就远大于分别写这两部分的时间的和。针对这种情况,一种解决方案就是就不要将小数据量的数据实时的刷盘,使用应用层的cache来缓存小数据量的index,这样就可以消除对写block文件的影响。
从原理上解释上面的表象,一般来说,硬盘读取数据的过程是这样的,首先是将磁头移动到磁盘上数据所在的区域,然后才能进行读取工作。磁头移动的过程又可以 分解为两个步骤,其一是移动磁头到指定的磁道,也就是寻道,这是一个在磁盘盘片径向上移动的步骤,花费的时间被称为“寻道时间”;其二就是旋转盘片到相应 扇区,花费的时间被称为“潜伏时间”(也被称为延迟)。那么也就是说在硬盘上读取数据之前,做准备工作上需要花的时间主要就是“寻道时间”和“潜伏时间” 的总和。真正的数据读取时间,是由读取数据大小和磁盘密度、磁盘转速决定的固定值,在应用层没有办法改变,但应用层缺可以通过改变对磁盘的访问模式来减少“寻道时间”和“潜伏时间”, 我们上面提到的在应用层使用cache然后排序的方式,无疑就是缩短了磁盘的寻址时间。由于磁头是物理设备,也很容易理解,为什么中间插入对其他小文件的读写会导致速度变慢很多。
建议:尽量避免完全的随机写,在 不能使用多线处理的时候,尽量使用应用层cache,确保写盘时尽量有顺序性。对于小数据量的其他文件,可以一直保存在应用层cache里面,避免对其他大数据量的数据写入产生影响。
2. 多线程随机读、处理速度、响应时间
多线程随机读的处理速度可以达到单线程随机读的10倍以上,但同上也带来了响应时间的增大。测试结论如下:(每个线程尽量读)
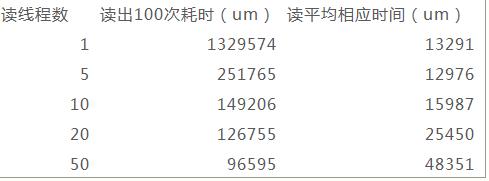
结论标明增加线程数,可以有效的提升程序整体的io处理速度。但同时,也使得每个io请求的响应时间上升很多。
从底层的实现上解释这个现象:应用层的io请求在内核态会加入到io请求队列里面。内核在处理io请求的时候,并不是简单的先到先处理,而是根据磁盘的特 性,使用某种电梯算法,在处理完一个io请求后,会优先处理最临近的io请求。这样可以有效的减少磁盘的寻道时间,从而提升了系统整体的io处理速度。但对于每一个io请求来看,由于可能需要在队列里面等待,所以响应时间会有所提升。
响应时间上升,应该主要是由于我们测试的时候采用每个线程都尽量读的方式。在实际的应用中,我们的程序都没有达到这种压力。所以,在io成为瓶颈的程序里面,应该尽量使用多线程并行处理不同的请求。对于线程数的选择,还需要通过性能测试来衡量。
3. 是否使用direct io
首先看测试结论:

可见在小数据量下非dio方式更快,但随着数据量增大,dio方式更快,分界线在50G左右。(注,测试基于: 线程数:50,每次读操作读出:4K, 机器:del 180, 内存:机器总内存8G,使用其他程序占用3G,剩余5G左右, 其他情况可能有不同的分界线。)
4. 系统缓存
4.1. 系统缓存相关的几个内核参数:
1. /proc/sys/vm/dirty_background_ratio
该文件表示脏数据到达系统整体内存的百分比,此时触发pdflush进程把脏数据写回磁盘。
缺省设置:10
2. /proc/sys/vm/dirty_expire_centisecs
该文件表示如果脏数据在内存中驻留时间超过该值,pdflush进程在下一次将把这些数据写回磁盘。
缺省设置:3000(1/100秒)
3. /proc/sys/vm/dirty_ratio
该文件表示如果进程产生的脏数据到达系统整体内存的百分比,此时进程自行把脏数据写回磁盘。
缺省设置:40
4. /proc/sys/vm/dirty_writeback_centisecs
该文件表示pdflush进程周期性间隔多久把脏数据写回磁盘。
缺省设置:500(1/100秒)
4.2. 系统一般在下面三种情况下回写dirty页:
1. 定时方式: 定时回写是基于这样的原则:/proc/sys/vm/dirty_writeback_centisecs的值表示多长时间会启动回写线程,由这个定时 器启动的回写线程只回写在内存中为dirty时间超过(/proc/sys/vm/didirty_expire_centisecs / 100)秒的页(这个值默认是3000,也就是30秒),一般情况下dirty_writeback_centisecs的值是500,也就是5秒,所以 默认情况下系统会5秒钟启动一次回写线程,把dirty时间超过30秒的页回写,要注意的是,这种方式启动的回写线程只回写超时的dirty页,不会回写 没超时的dirty页,可以通过修改/proc中的这两个值,细节查看内核函数wb_kupdate。
2. 内存不足的时候: 这时并不将所有的dirty页写到磁盘,而是每次写大概1024个页面,直到空闲页面满足需求为止
3. 写操作时发现脏页超过一定比例: 当脏页占系统内存的比例超过/proc/sys/vm/dirty_background_ratio 的时候,write系统调用会唤醒pdflush回写dirty page,直到脏页比例低于/proc/sys/vm/dirty_background_ratio,但write系统调用不会被阻塞,立即返回.当脏 页占系统内存的比例超/proc/sys/vm/dirty_ratio的时候, write系统调用会被被阻塞,主动回写dirty page,直到脏页比例低于/proc/sys/vm/dirty_ratio
4.3. pb项目中的感触:
1,如果写入量巨大,不能期待系统缓存的自动回刷机制,最好采用应用层调用fsync或者sync。如果写入量大,甚至超过了系统缓存自动刷回的速 度,就有可能导致系统的脏页率超过/proc/sys/vm/dirty_ratio, 这个时候,系统就会阻塞后续的写操作,这个阻塞有可能有5分钟之久,是我们应用无法承受的。因此,一种建议的方式是在应用层,在合适的时机调用 fsync。
2,对于关键性能,最好不要依赖于系统cache的作用,如果对性能的要求比较高,最好在应用层自己实现cache,因为系统cache受外界影响太大,说不定什么时候,系统cache就被冲走了。
3,在logic设计中,发现一种需求使用系统cache实现非常合适,对于logic中的高楼贴,在应用层cache实现非常复杂,而其数量又非常 少,这部分请求,可以依赖于系统cache发挥作用,但需要和应用层cache相配合,应用层cache可以cache住绝大部分的非高楼贴的请求,做到 这一点后,整个程序对系统的io就主要在高楼贴这部分了。这种情况下,系统cache可以做到很好的效果。
5. 磁盘预读
关于预读,从网上摘录如下两段:
预读算法概要
1. 顺序性检测
为了保证预读命中率,Linux只对顺序读(sequential read)进行预读。内核通过验证如下两个条件来判定一个read()是否顺序读:
- 这是文件被打开后的第一次读,并且读的是文件首部;
- 当前的读请求与前一(记录的)读请求在文件内的位置是连续的。
如果不满足上述顺序性条件,就判定为随机读。任何一个随机读都将终止当前的顺序序列,从而终止预读行为(而不是缩减预读大小)。注意这里的空间顺序性说的 是文件内的偏移量,而不是指物理磁盘扇区的连续性。在这里Linux作了一种简化,它行之有效的基本前提是文件在磁盘上是基本连续存储的,没有严重的碎片 化。
2. 流水线预读
当程序在处理一批数据时,我们希望内核能在后台把下一批数据事先准备好,以便CPU和硬盘能流水线作业。Linux用两个预读窗口来跟踪当前顺序流的预读 状态:current窗口和ahead窗口。其中的ahead窗口便是为流水线准备的:当应用程序工作在current窗口时,内核可能正在ahead窗 口进行异步预读;一旦程序进入当前的ahead窗口,内核就会立即往前推进两个窗口,并在新的ahead窗口中启动预读I/O。
3. 预读的大小
当确定了要进行顺序预读(sequential readahead)时,就需要决定合适的预读大小。预读粒度太小的话,达不到应有的性能提升效果;预读太多,又有可能载入太多程序不需要的页面,造成资源浪费。为此,Linux采用了一个快速的窗口扩张过程:
首次预读: readahead_size = read_size * 2; // or *4
预读窗口的初始值是读大小的二到四倍。这意味着在您的程序中使用较大的读粒度(比如32KB)可以稍稍提升I/O效率。
后续预读: readahead_size *= 2;
后续的预读窗口将逐次倍增,直到达到系统设定的最大预读大小,其缺省值是128KB。这个缺省值已经沿用至少五年了,在当前更快的硬盘和大容量内存面前,显得太过保守。
# blockdev –setra 2048 /dev/sda
当然预读大小不是越大越好,在很多情况下,也需要同时考虑I/O延迟问题。
6. 其他细节:
6.1. pread 和pwrite
在多线程io操作中,对io的操作尽量使用pread和pwrite,否则,如果使用seek+write/read的方式的话,就需要在操作时加锁。这种加锁会直接造成多线程对同一个文件的操作在应用层就串行了。从而,多线程带来的好处就被消除了。
使用pread方式,多线程也比单线程要快很多,可见pread系统调用并没有因为同一个文件描述符而相互阻塞。pread和pwrite系统调用在底层 实现中是如何做到相同的文件描述符而彼此之间不影响的?多线程比单线程的IOPS增高的主要因素在于调度算法。多线程做pread时相互未严重竞争是次要 因素。
内核在执行pread的系统调用时并没有使用inode的信号量,避免了一个线程读文件时阻塞了其他线程;但是pwrite的系统调用会使用inode的 信号量,多个线程会在inode信号量处产生竞争。pwrite仅将数据写入cache就返回,时间非常短,所以竞争不会很强烈。
6.2. 文件描述符需要多套吗?
在使用pread/pwrite的前提下,如果各个读写线程使用各自的一套文件描述符,是否还能进一步提升io性能?
每个文件描述符对应内核中一个叫file的对象,而每个文件对应一个叫inode的对象。假设某个进程两次打开同一个文件,得到了两个文件描述符,那么在 内核中对应的是两个file对象,但只有一个inode对象。文件的读写操作最终由inode对象完成。所以,如果读写线程打开同一个文件的话,即使采用 各自独占的文件描述符,但最终都会作用到同一个inode对象上。因此不会提升IO性能














 970
970











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









