







1、一个简单的多对多关系配置和操作示例。先导入jar包、新建2个实体类和对应的映射配置文件、配置Hibernate文件、写个Hibernate工具类,写个类做测试。
——映射文件里,双方都使用set,和之前一对多里面的一方类似,但是这里面多了一个table中间表属性,虽然我们不会创建一个实体类来对应中间表,但是在数据库中多对多的关系里面是存在这么一个中间表在数据库中的,所以我们需要在双方指定这个中间表的名字,要相同。
public class Student {
private Integer id;
private String name;
private Set<Course> courses=new HashSet<Course>();
……
}public class Course {
private Integer id;
private String name;
private Set<Student> students=new HashSet<Student>();
……
}多对多里面需要一方放弃维护外键,这里我们让Student维护,让Course放弃外键。所以Student这里需要使用级联保存和修改。
<hibernate-mapping package="com.hello.domain">
<class name="Student" table="t_student">
<id name="id" column="id">
<generator class="native"></generator>
</id>
<property name="name" column="name"></property>
<!-- 这个table就是中间表,存放cid和sid -->
<set name="courses" table="t_student_course" inverse="false" cascade="save-update">
<key column="sid"></key>
<many-to-many class="Course" column="cid"></many-to-many>
</set>
</class>
</hibernate-mapping>Course这里需要放弃外键维护。
<hibernate-mapping package="com.hello.domain">
<class name="Course" table="t_course">
<id name="id" column="id">
<generator class="native"></generator>
</id>
<property name="name" column="name"></property>
<set name="students" table="t_student_course" inverse="true">
<key column="cid"></key>
<many-to-many class="Student" column="sid"></many-to-many>
</set>
</class>
</hibernate-mapping>Hibernate配置文件:
<hibernate-configuration>
<session-factory>
<property name="hibernate.connection.driver_class">com.mysql.jdbc.Driver</property>
<property name="hibernate.connection.username">root</property>
<property name="hibernate.connection.password">root</property>
<property name="hibernate.connection.url">jdbc:mysql://localhost:3306/h03</property>
<property name="show_sql">true</property>
<property name="format_sql">true</property>
<property name="hibernate.connection.autocommit">true</property>
<property name="hibernate.current_session_context_class">true</property>
<property name="hibernate.hbm2ddl.auto">update</property>
<property name="hibernate.dialect">org.hibernate.dialect.MySQLDialect</property>
<mapping resource="com/hello/domain/Student.hbm.xml"/>
<mapping resource="com/hello/domain/Course.hbm.xml"/>
</session-factory>
</hibernate-configuration>最后测试:
@Test
public void test01(){
Session openSession = HibernateUtil.openSession();
openSession.beginTransaction();
Student stu1=new Student();
stu1.setName("Eric");
Student stu2=new Student();
stu2.setName("Andy");
Course c1=new Course();
c1.setName("Math");
Course c2=new Course();
c2.setName("Nature");
Course c3=new Course();
c3.setName("English");
stu1.getCourses().add(c1);
stu1.getCourses().add(c2);
stu2.getCourses().add(c2);
stu2.getCourses().add(c3);
openSession.save(stu1);
openSession.save(stu2);
openSession.getTransaction().commit();
openSession.close();
}注意:如果我们再执行一遍程序,数据库中就会继续新增一遍记录,重复的记录,并不会覆盖原先的记录。
2、加载策略,优化查询。
——延迟加载和立即加载。
——类级别的加载策略(加载对象是)和关联级别的加载策略(一对多等关系)。
——类级别的加载策略。比如get是立即查询数据库将数据初始化,load是先返回一个代理对象,使用代理对象属性时才去查询数据库。但是我们的load是否是立即加载还是延迟加载取决于XXX.hbm.xml里面的类的配置属性lazy。默认是true,如果修改为false那么load方法就和get方法是一样的立即加载。
<hibernate-mapping package="com.hello.domain">
<class name="Course" table="t_course" lazy="true">
……
</class>
</hibernate-mapping>——验证类级别的2种加载策略方法。我们写下面2句测试代码。当我们不做任何配置的时候,其实Course类的load方法加载策略默认是延迟加载,即我们如果加断点的话会发现第1句代码执行时并没有发送select语句查询数据库,而是在使用它的属性也就是第2句话执行的时候才去select数据库查询数据。如果我们修改成lazy="false"的话,我们会发现执行第1句时就发送了select去数据库查询数据。当然我们可以测试一下get方法,它是立即去查询数据库的。
Course c4=(Course) openSession.load(Course.class, 1);
System.out.println(c4.getName());——关联级别的加载策略。(先看一对多的加载策略,也就是说我们)意思就是说在查询有关联关系的数据时,加载一方数据时是否需要将另一方数据立即查询出。
- 结论是查询时,默认是懒加载,即在查询的时候才去加载。其实我们懒加载的本质是加载关联关系的数据,就是我们的集合Set,比如我有一个Customer和Order类,在Customer里面有一个Order集合属性。我在查询Customer(实例化为c1)的时候,这个Order是没有一并被查询出来的,而是在我调用它(c1.getOrders())的时候才去查询Order。所以决定这个集合是否被懒加载,决定权不在Customer类,而在Customer里面的集合Set身上,这个Set集合也有一个lazy属性,默认也是true,也就是默认是懒加载的。
<hibernate-mapping package="com.hello.domain">
<class name="Customer" table="t_customer">
……
<set name="orders" table="t_customer_order" inverse="false" cascade="save-update" lazy="true">
</set>
……
</class>
</hibernate-mapping>- 所以,结论是如果我想要立即加载关联级别的查询,那就把上面的Set的lazy设置成false。
- 除了lazy决定了关联级别的加载策略外,set标签还有一个属性叫做fetch属性,它有3个值,默认是select,还有join(表连接查询)和subselect(子查询)。比如,我们使用设置成join的时候,然后用get查询,打印的SQL查询语句就是外连接把2个表的数据都查询出来了。
- 排列组合一下:
- fetch=”select” lazy=”true”,这是默认的,会在使用集合的时候才加载集合,用的是select语句查询。
- fetch=”select” lazy=”false”,立即用select语句加载集合。
- fetch=”join” lazy=”true”,因为查询的时候使用的是表的外连接,所以直接把2个表的数据都查询出来了,所以也就是立即加载集合,用的是join语句。
- fetch=”join” lazy=”false”,上面拦截在的情况就已经立即加载了,这种情况肯定更是立即加载了。相当于fetch取join的时候,lazy属性相当于是失效了。
- fetch=”subselect” lazy=”true”,会在使用时加载,用子查询语句。
- fetch=”subselect” lazy=”false”,立即加载,用子查询语句。
注意:其实set标签的lazy属性除了true和false外,还有一个extra,叫极其懒惰,意思是我们使用集合Set的时候,要看情况,一般不涉及到真正使用集合里面数据的时候,它只调用size方法查询数量,Hibernate发送count方法查询数量,不加载集合里面的数据。只有当真正使用里面的属性了才发送查询语句加载里面的数据。
- fetch=”select” lazy=”extra”,只在使用集合时加载,但加载也分情况,如果只是查询集合长度不使用集合里面数据,那么它只发送count查询数量。
- fetch=”join” lazy=”extra”,立即加载。join比较强势,基本lazy属性就相当于失效了。
- fetch=”subselect” lazy=”extra”,只在使用集合时加载,使用子查询语句,如果只是查询集合长度不使用集合里面数据,那么它只发送count查询数量。
3、多对一的加载策略,也就是说我们的配置现在是多方的many-to-one标签上。在客户-订单的例子中就是订单方的配置了。
——它也有两个属性lazy和fetch,但是取值不一样了。
fetch=”select” lazy=”false”,表示加载订单的时候立即加载客户,使用select语句。我们使用
Order o=(Order)openSession.get(Order.class,1);可以断点查看输入的SQl语句,发现它发送了2条SQL语句,先查询订单然后把客户也都查询了。fetch=”select” lazy=”proxy”,proxy的话要看对方类的加载策略(也就是Customer类的加载策略要么是lazy=”true”要么是”false”)。如果对象Customer的lazy是false,也就是人家类加载策略是立即加载,那么这里我们查询订单Order的时候就立即把Customer查询出来;相反就在使用的时候再查询。也就是说当我们多方Order加载策略是proxy的时候,是否立即加载1方Customer取决于1方Customer自己的类加载策略,它想被立即加载就立即加载。
fetch=”join” lazy=”false”,遇到了join,lazy失效了,所以都是立即加载。
fetch=”join” lazy=”proxy”,遇到了join,lazy失效了,所以都是立即加载。
**注意:**lazy还有一个no-proxy值,这里暂不讨论。
4、批量查询。我们先来看如下的代码:
List<Customer> list=openSession.createQuery("from Customer").list(); //1
for(Customer c:list){ //2
System.out.println(c.getOrders().size()); //3
}上面的这个语句在第一行会调用查询语句,在第3行的时候循环一次调用一次查询语句,如果这里有很多循环的话,那么查询次数就会很多,我们可以设置每次查询多少客户的订单,而不是每次只查询1个客户的订单。这个设置就是在客户类的set标签里,有个batch-size,如果设置为10,那么每次就查询加载10个客户下所有的订单,那么上面的语句就只会输出一遍查询语句(我们只有2个客户,<10)。我们可以看到它的这次查询时使用in条件查询的。
注意:我们在日常使用时,要看具体情况来选择立即加载(检索)还是延迟加载(检索)还是表连接加载(检索)。如果取A的时候经常要用到B的话那么立即加载适合,如果不是就尽量使用延迟加载。这里还有内存的考虑,延迟加载节省内存;这里还有二级缓存的考虑,如果使用了二级缓存,可以使用立即加载。
此外,我们在具体实践中药尤其注意懒加载带来的困惑,因为如果是懒加载的话,我们一定要保证获得了这个数据,不然我们直接返回给页面使用的时候,我们是拿不到数据的,这样的解决办法要么是设置成立即加载,要么就在service层里面调用一下这个数据(因为懒加载只有在调用的时候才加载数据),然后再给页面使用。
5、Hibernate查询总结与强化。
- get/load:根据OID查询。
- 对象检索视图:比如c.getOrders()。
- SQL语句:createSqlQuery()。
- HQL语句:createQuery()。
Critieria语句:createCritieria()。
——我们来看HQL语句。可以看下面3句查询语句的演变,第一句是最简单的,第二句加了个别名其实结果和第一个一样,第三句就用了别名来查询每个属性,注意,这里面是类的属性,而不是表里的column,虽然我们一般是让两者相同。如果查询的是一列,那么直接返回一个List,比如是
List<String>等。如果查询多列,那么返回的也是一个List,只是这个List里面是很多的数组Array。
Query createQuery1 = openSession.createQuery("from Student");
Query createQuery2 = openSession.createQuery("from Student s");
Query createQuery3 = openSession.createQuery("select s.id,s.name from Student s");
List<Student> list = createQuery1.list();——投影查询,用的不是很多。主要是基于上面的例子,比如我们上面查询了2列,查出来的结果是在数组里然后封装在List里返回,如果我们能把结果封装到对象里(虽然只是查了部分属性)那就十分美好了。投影查询就是这么个功能。但本质上是利用了实体类的构造方法(我们自己写的)。比如在实体类中增加一个我们自定义的构造方法,顺便补充一下无参构造方法:
public Student() {
}
public Student(Integer id, String name) {
super();
this.id = id;
this.name = name;
}然后在HQL查询的时候语句修改成相当于new一个实例出来一样:
Query createQuery3 = openSession.createQuery("select new Student(s.id,s.name) from Student s");——排序desc/asc:
Query createQuery3 = openSession.createQuery("from Student s order by s.id desc");——分页:
Query createQuery3 = openSession.createQuery("from Student s order by s.id desc");
//从索引0开始,取10条
createQuery3.setFirstResult(0);
createQuery3.setMaxResults(10);——绑定参数。有两种形式。一种是?表示占位符,一种是:+变量名的方式。
第一种方式使用?:
Query q=openSession.createQuery("from Student s where s.id=? and s.name=?");
//第一个参数是占位符的索引位置,就是第一个0,赋值为2
q.setInteger(0,2);
q.setString(1,'eric');
Student s1=(Student)q.uniqueResutlt();第二种使用:命名,就是用名称代替索引,常见一些:
Query q=openSession.createQuery("from Student s where s.id=:idValue and s.name=:nameValue");
//第一个参数是占位符的索引位置,就是第一个0,赋值为2
q.setInteger("idValue",2);
q.setString("nameValue","eric");
Student s1=(Student)q.uniqueResutlt();——聚合函数和分组。
Query q=openSession.createQuery("select count(*) from Student s");
Query q=openSession.createQuery("select avg(c.id) from Student s");
Query q=openSession.createQuery("select sum(c.id) from Student s");
Query q=openSession.createQuery("select max(c.id) from Student s");
Query q=openSession.createQuery("select min(c.id) from Student s");
Object xxx=q.uniqueResult();
//直接打印xxx即可得到数据Query q=openSession.createQuery("select o.customer,count(o) from Order o group by o.customer");
//List里面的数组,装了2个东西,一个是Customer对象,一个是值
List<Object[]> list=q.list();Query q=openSession.createQuery("select o.customer,count(o) from Order o group by o.customer having count(o)>2");
//List里面的数组,装了2个东西,一个是Customer对象,一个是值
List<Object[]> list=q.list();6、表连接。 交叉连接(笛卡尔积)、内连接、左外连接、右外连接。
——交叉连接,就是不配置任何连接方式,直接查询两个表。
Query createQuery = openSession.createQuery("from Customer c,Order o");
List<Object[]> list = createQuery.list();
for(Object[] obj : list){
System.out.println(Arrays.toString(obj));
}——内连接。隐式内连接就是在笛卡尔积基础上过滤掉无效数据,显示内连接就是直接使用inner join关键字。
隐式的:
Query createQuery = openSession.createQuery("from Customer c,Order o where o.customer=c");显示的:
Query createQuery = openSession.createQuery("from Customer c inner join c.orders");迫切内连接,就是在inner join后面添加fetch。区别在于:非迫切内连接,返回到的是List<Object[]>,这个Object[]数组里面装的是[Customer对象,与Customer相关的Order对象]。迫切内连接,返回的是List<Customer>,直接将子装入父中,行程一个对象,所以List里面不再是一个数组泛型,而是父的泛型。
——左外连接,就是把左边的都显示出来,右边的没有的话用null。
Query createQuery = openSession.createQuery("from Customer c left outer join c.orders");——右外连接同样的道理。外连接也同样可以和迫切结合就在后面加fetch。
7、命名查询。
——先在映射的配置文件中配置全局的查询语句或者局部的查询语句:
<hibernate-mapping package="com.hello.domain">
<class name="Student" table="t_student">
//局部的是写在class标签里
<query name="jubu"><![CDATA[from Course]]></query>
</class>
//全局的直接写在映射标签里
<query name="quanju"><![CDATA[from Student]]></query>
</hibernate-mapping>——使用的时候,全局的直接写name,局部的前面要加上类名。
//Query namedQuery = openSession.getNamedQuery("quanju");
Query namedQuery2 = openSession.getNamedQuery("com.hello.domain.Student.jubu");
List<Course> list = namedQuery2.list();
for(Course c:list){
System.out.println(c);
}8、QBC查询,就是Critieria,很少用,它的功能不全,只支持单表查询。仅作了解。
9、连接池。使用C3P0。连接池的配置一般由经验丰富的开发者配置,不然性能和效率不一定能达到最优。
——先导入C3P0包。在hibernate-distribution-3.6.10.Final\lib\optional\c3p0里面HIbernate放在了可选jar里,我们可以直接从这里取。添加再add to bulid path。
——然后在hibernate.cfg.xml中配置C3P0的信息。这些属性都在hibernate-distribution-3.6.10.Final\project\etc的hibernate.properties文件里面。
<!-- 配置C3P0,如果不配置,Hibernate会自动选择内置的 -->
<property name="hibernate.connection.provider_class">org.hibernate.connection.C3P0ConnectionProvider</property>
<!-- 配置属性,不配置的话会使用默认数据 -->
<property name="hibernate.c3p0.max_size">5</property>——配置好后验证,写下面1句代码,然后看控制台的输出。
System.out.println(openSession);信息: Initializing c3p0-0.9.1 [built 16-January-2007 14:46:42; debug? true; trace: 10]
2016-10-11 15:20:06 com.mchange.v2.c3p0.impl.AbstractPoolBackedDataSource getPoolManager
信息: Initializing c3p0 pool... com.mchange.v2.c3p0.PoolBackedDataSource@432010c0……10、事务。如果是真正开发的时候,我们在hibernate.cfg.xml里面就不需要配置自动提交事务,下面这个属性就不配置了。
<property name="hibernate.connection.autocommit">true</property>——事务的ACID。
- Atomicity原子性。是一个整体,要么都成功,要么都失败。
- Consistency一致性。总体不变,比如转账,不管多少操作,这些人的账户最终总金额是不变的。
- Isolation隔离性。保证读取不受影响。
- 持久性Durability。受到影响的数据都被同步到数据库了。
然后出来4个级别:read uncommitted(1)、read committed(2)、repeatable read(4,MySQL默认级别)、 serializable(8,串行化)。
在Hibernate中,即在hibernate.cfg.xml中可以改变数据库的隔离级别。
<property name="hibernate.connection.isolation">4</property11、数据库中的锁。
——悲观锁,就是认为我在修改数据的时候总觉得别人也会在修改数据,所以这是防止别人跟我抢着修改数据的策略。乐观锁就相反,它是人为控制的锁。
——悲观锁又分为读锁、写锁。读锁:就是我在读取数据的过程中自己不会修改数据也不希望别人修改数据,我就可以给我读取的数据加个读锁。写锁:我需要读取并修改数据,所以我给读取的数据加一个写锁。
——读锁,也叫共享锁。我们假设有两个人在读数据如下。如果没有第二个人的话,第一个人虽然是在读取数据的时候加了读锁,但是它自己还是可以修改数据的。但是当第二个人读取数据加了读锁之后第一个人就不能修改数据了,它能修改数据的条件是要么这个读锁只被它一个人持有,要么其他人虽然持有但是已经提交了事务释放了锁最后还是它一个人持有。我们可以看到读锁其实是大家都能持有的锁,大家约定不对读取的数据进行修改,所以读锁也叫做共享锁。
第一个人:
start transaction;
select * from t_customer lock in share mode;
update t_customer set name="hello" where id=1;
commit;第二个人:
start transaction;
select * from t_customer lock in share mode;
commit;——写锁,也叫排它锁。下面的语句就是给数据加了写锁,所以这个语句如果在第一个人里执行了,那么再第二个人那里有不能执行这句语句,因为写锁是排它锁,只能一个人持有。
select * from t_customer for update——在Hibernate中使用悲观锁的写锁(读锁就是把UPGRADE换成READ):
Student s = (Student)openSession.get(Student.class, 1, LockOptions.UPGRADE);我们可以观察打印的SQL语句,有for update:
Hibernate:
select
student0_.id as id0_0_,
student0_.name as name0_0_
from
t_student student0_
where
student0_.id=? for update——乐观锁本身相当于没有锁,任何人都可以覆盖修改,所以乐观锁的实施其实需要一些约定。比如有如下数据是一个消费者,有2个商家要扣款,第1个商家取出数据后扣除了100,然后把version+1改成2(这就是约定),再同步到数据库去。如果当时也正好有第2个商家也在取出了数据扣除了钱修改了version为2,这个时候商家2提价的时候就会发现自己的version不满足大于数据库中version这个条件,说明自己数据不是最新的,所以就无法提交,它只能重新获取version2时候的数据,扣除100再把version变成3,再同步到数据库。
id name balance version
1 eric 1000 1上面的原理其实相当于是SVN的原理。它会给我们每次的文件配置一个version。
我们在Hibernate中使用乐观锁,2个步骤:
- 第一步,给需要加乐观锁的实体类添加一个Integer的属性,一般叫version,并生成getter和setter方法。
private Integer version;
……- 然后在类的映射配置文件比如
Student.hbm.xml中添加配置信息,需要在id之后、property之前添加。
//name就是我们定义的属性
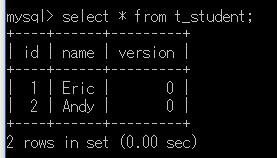
<version name="version"></version>测试,我们如果不执行其他语句,只是执行下面的几句代码,可以观察数据库的t_student表后面增加了一列version,初始值都是0:
@Test
public void test01(){
Session openSession = HibernateUtil.openSession();
openSession.beginTransaction();
openSession.getTransaction().commit();
openSession.close();
}
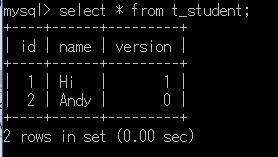
而如果我们执行了下列代码,即修改了一下数据,
@Test
public void test01(){
Session openSession = HibernateUtil.openSession();
openSession.beginTransaction();
Student s = (Student) openSession.get(Student.class, 1);
s.setName("Hi");
openSession.getTransaction().commit();
openSession.close();
}我们可以看到id为1的记录的数据变化了,而且version自动加1。
如果你想要看到乐观锁的version条件下提交失败的例子的话,你加个断点,在取出数据后修改好数据没有提交事务之前,自己在命令行工具或者数据库管理工具中修改一下这个记录对应的version数据,比如设置的大一些,然后在程序里面放行断点,提交事务的时候它就不会打印update语句,因为提交失败了,所以没成功更新数据。














 3984
3984











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









