HashMap通过hashcode对其内容进行快速查找,而TreeMap中所有的元素都保持着某种固定的顺序,如果你需要得到一个有序的结果你就应该使用TreeMap(HashMap中元素的排列顺序是不固定的)。
集合框架”提供两种常规的Map实现:HashMap和TreeMap (TreeMap实现SortedMap接口)。在Map 中插入、删除和定位元素,HashMap 是最好的选择。但如果您要按自然顺序或自定义顺序遍历键,那么TreeMap会更好。使用HashMap要求添加的键类明确定义了hashCode()和equals()的实现。 这个TreeMap没有调优选项,因为该树总处于平衡状态。
TreeMap的顺序是自然顺序(如整数从小到大),也可以指定比较函数。但不是插入的顺序。
用LinkedHashMap吧。它内部有一个链表,保持插入的顺序。迭代的时候,也是按照插入顺序迭代,而且迭代比HashMap快。
对于HashMap、Hashtable、TreeMap、LinkedHashMap的内部排序,发现网上有很多人都理解错了。
比如,有的人认为:
Hashtable.keySet() 降序
TreeMap.keySet() 升序
HashMap.keySet() 乱序
LinkedHashMap.keySet() 原序
也有的人认为是keyset跟entryset的区别导致的。那么下面我就通过两种遍历方式来给大家试验一下。
把全部要论证的问题先抛在这里,待会看代码看结果:
1.HashMap、Hashtable、TreeMap、LinkedHashMap的内部排序
2.分别用 keyset跟entryset遍历出来的结果有区别吗
3.HashMap、Hashtable、TreeMap、LinkedHashMap初始默认的大小
研究了一些天,有了些结果,都是通过代码测试出来的,亲测有效~~~ (分别对int,String进行测试,主要看key的排序)
(终极声明,大家先不要吐槽范型的问题,我只是做个测试,不影响实际操作,谢过)
先来重现一下网上的舆论结果,看我的代码
- package testCollections;
-
- import java.util.*;
- import java.util.Map.Entry;
-
- public class TestOfOrderOfMap {
-
-
- public void testOfKeyset(Map map, Object obj[]){
- for(int i=0; i<obj.length; i++){
- map.put(obj[i], obj[i]);
- }
-
- if(map instanceof LinkedHashMap){
- System.out.println("LinkedHashMap" +": " + map);
- }else if(map instanceof HashMap){
- System.out.println("HashMap" +": " + map);
- }else if(map instanceof Hashtable){
- System.out.println("Hashtable" +": " + map);
- }else if(map instanceof TreeMap){
- System.out.println("TreeMap" +": " + map);
- }
-
- System.out.print("key: ");
- Iterator it = map.keySet().iterator();
- <span style="white-space:pre"> </span>while (it.hasNext()) {
- <span style="white-space:pre"> </span>Object key = it.next();
- System.out.print(key+" ");
- <span style="white-space:pre"> </span>}
- <span style="white-space:pre"> </span>System.out.println();
- }
-
-
- public void testOfEntryset(Map map, Object obj[]){
- for(int i=0; i<obj.length; i++){
- map.put(obj[i], obj[i]);
- }
-
- if(map instanceof LinkedHashMap){
- System.out.println("LinkedHashMap" +": " + map);
- }else if(map instanceof HashMap){
- System.out.println("HashMap" +": " + map);
- }else if(map instanceof Hashtable){
- System.out.println("Hashtable" +": " + map);
- }else if(map instanceof TreeMap){
- System.out.println("TreeMap" +": " + map);
- }
-
- System.out.print("key: ");
- Iterator it = map.entrySet().iterator();
- <span style="white-space:pre"> </span>while (it.hasNext()) {
- <span style="white-space:pre"> </span>Entry e = (Entry) it.next();
- <span style="white-space:pre"> </span>System.out.print(e.getKey()+" ");
- <span style="white-space:pre"> </span>}
- <span style="white-space:pre"> </span> System.out.println();
- }
-
- public static void main(String[] args) {
- TestOfOrderOfMap test = new TestOfOrderOfMap();
-
- HashMap hm1 = new HashMap();
- Hashtable ht1 = new Hashtable();
- TreeMap tm1 = new TreeMap();
- LinkedHashMap lhm1 = new LinkedHashMap();
-
- Integer a[] = new Integer[]{3, 2, 5, 1, 4};
-
-
- System.out.println("这里是KeySet的测试:");
- test.testOfKeyset(hm1, a);
- test.testOfKeyset(ht1, a);
- test.testOfKeyset(tm1, a);
- test.testOfKeyset(lhm1, a);
-
-
- System.out.println();
- System.out.println("这里是EntrySet的测试:");
- test.testOfEntryset(hm1, a);
- test.testOfEntryset(ht1, a);
- test.testOfEntryset(tm1, a);
- test.testOfEntryset(lhm1, a);
-
- }
- }
看结果
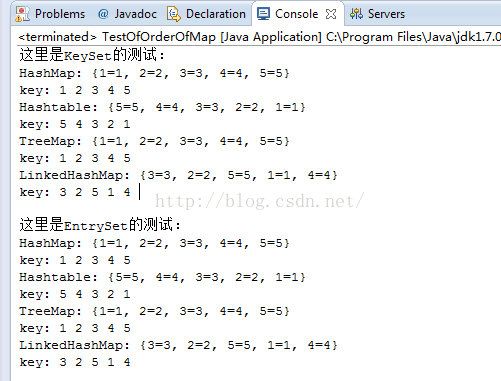
图1
大家是不是觉得就跟上面说的一样啊,博主,你逗我们的吧?
Hashtable.keySet() 降序
TreeMap.keySet() 升序
HashMap.keySet() 乱序
LinkedHashMap.keySet() 原序
且听博主慢慢讲解噢,在这里可以肯定的是keyset 跟 entryset所遍历的结果完全是一样的,证明了第二点,那么第一点呢,
如果我把上面的 Integer a[] = new Integer[]{3, 2, 5, 1, 4}; 改为 Integer a[] = new Integer[]{13, 2, 5, 1, 4}; 也就是把3改为了13,
你们再看结果

图2
是不是想说,咦,这是什么鬼。是不是上面的论断结果是错误的了呀,
Hashtable.keySet() 降序 //错误
TreeMap.keySet() 升序 //正确
HashMap.keySet() 乱序 //可以说错误,因为你还不懂它的原理
LinkedHashMap.keySet() 原序 //可以说错误,因为你还不懂它的原理,这和LinkedHashMap的构造方法有关,后面我会说
再来看几组结果,听我分析。(以后我只列出keyset的结果截图,因为entryset 跟 keyset一样)
如果我把上面的 Integer a[] = new Integer[]{3, 2, 5, 1, 4}; 改为 Integer a[] = new Integer[]{16, 2, 5, 1, 4};

图3
如果我把上面的 Integer a[] = new Integer[]{3, 2, 5, 1, 4}; 改为 Integer a[] = new Integer[]{11, 2, 5, 1, 4};

图4
如果我把上面的 Integer a[] = new Integer[]{3, 2, 5, 1, 4}; 改为 Integer a[] = new Integer[]{0, 65, 3, 17, 32};

图5
大家看出端倪没有,是这样的,如果看过这些集合类源码的哥哥姐姐可能就会知道,它们的遍历与它们的存储有关,而存储与容器的大小有关,
而在我们创建容器却没有指定容器大小的情况下,容器一般都会有一个默认大小,这个很好理解。
HashMap 的默认大小为16,每次增长会加倍,Hashtable的默认大小为11,每次增长原来的2倍加1,TreeMap 跟 LinkedHashMap暂时无法确定或者说无限大,
不过在这里不影响我们的理解。好了,HashMap是会根据key的hashCode再进行hash计算,最后散列到Entry中,看源码
- public V put(K key, V value) {
- if (key == null)
- return putForNullKey(value);
- int hash = hash(key);<span style="white-space:pre"> </span>
- int i = indexFor(hash, table.length);
- for (Entry<K,V> e = table[i]; e != null; e = e.next) {
- Object k;
- if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
- V oldValue = e.value;
- e.value = value;
- e.recordAccess(this);
- return oldValue;
- }
- }
-
- modCount++;
- addEntry(hash, key, value, i);
- return null;
- }
- final int hash(Object k) {
- int h = 0;
- if (useAltHashing) {
- if (k instanceof String) {
- return sun.misc.Hashing.stringHash32((String) k);
- }
- h = hashSeed;
- }
-
- h ^= k.hashCode();
-
-
-
-
- h ^= (h >>> 20) ^ (h >>> 12);<span style="white-space:pre"> </span>
- return h ^ (h >>> 7) ^ (h >>> 4);
- }
- static int indexFor(int h, int length) {
- return h & (length-1);
- }
- void addEntry(int hash, K key, V value, int bucketIndex) {
- if ((size >= threshold) && (null != table[bucketIndex])) {
- resize(2 * table.length);
- hash = (null != key) ? hash(key) : 0;
- bucketIndex = indexFor(hash, table.length);
- }
-
- createEntry(hash, key, value, bucketIndex);
- }
- void createEntry(int hash, K key, V value, int bucketIndex) {
- Entry<K,V> e = table[bucketIndex];
- table[bucketIndex] = new Entry<>(hash, key, value, e);
- size++;
- }
取value的过程也一样,就是根据key存放的位置来取,所以说HashMap不是无序的,而是按照hash值来存取的,只不过这个hash值,我们比较难以计算出来罢了。
有个小发现,当key的值不超过16时,HashMap的存取是按照从小到大的顺序来存取的
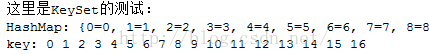
图6
至于Hashtable的存取,跟HashMap大同小异,只不过在方法前加了个synchronized同步字段,其次是hash值的计算有点小区别
有个小发现,当key的个数不超过11且key的值不超过11时,Hashtable的存取是按照从大到小的顺序来存取的
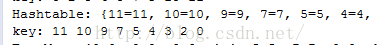
图7
T
reeMap就比较好理解了,其底层实现采用的是红黑树,key按照从小到大的顺序排好,搞定。
LinkedHashMap这里呢,有两个顺序,一个是插入的顺序,一个是访问的顺序,取决于构造方法里面的参数accessOrder是否为true,当accessOrder为true时,遍历LinkedHashMap是按照访问顺序存储,当accessOrder为false时,LinkedHashMap是按照插入顺序存储,默认为false。看例子。
- package testCollections;
-
- import java.util.*;
- import java.util.Map.Entry;
-
- public class TestOfOrderOfMap {
-
- public void testOfKeyset(Map map, Object obj[]){
- for(int i=0; i<obj.length; i++){
- map.put(obj[i], obj[i]);
- }
-
- System.out.println("LinkedHashMap" +": " + map);
- System.out.print("key: ");
- Iterator it = map.keySet().iterator();
- while (it.hasNext()) {
- Object key = it.next();
- System.out.print(key+" ");
- }
- System.out.println();
- }
-
- public static void main(String[] args) {
- TestOfOrderOfMap test = new TestOfOrderOfMap();
- LinkedHashMap lhm1 = new LinkedHashMap();
- Integer a[] = new Integer[]{7, 0, 5, 10, 17, 6, 2, 8, 3, 31};
-
- test.testOfKeyset(lhm1, a);
- }
- }
结果:

图8
- 插入的顺序为Integer a[] = new Integer[]{7, 0, 5, 10, 17, 6, 2, 8, 3, 31}
- 打印的顺序也是 7, 0, 5, 10, 17, 6, 2, 8, 3, 31
下面看按访问顺序的,把上面的
- LinkedHashMap lhm1 = new LinkedHashMap();
改为 LinkedHashMap lhm1 = new LinkedHashMap(16, 0.75f,true);全部修改如下:
- package testCollections;
-
-
- import java.util.*;
- import java.util.Map.Entry;
-
-
- public class TestOfOrderOfMap {
-
-
- <span style="white-space:pre"> </span>public void testOfKeyset(Map map, Object obj[]){
- <span style="white-space:pre"> </span>for(int i=0; i<obj.length; i++){
- <span style="white-space:pre"> </span>map.put(obj[i], obj[i]);
- <span style="white-space:pre"> </span>}
-
- <span style="white-space:pre"> </span>System.out.println("LinkedHashMap" +": " + map);
-
- <span style="white-space:pre"> </span>System.out.print("访问 " + map.get(7)+" 之后: ");
- <span style="white-space:pre"> </span>System.out.println(map);
- <span style="white-space:pre"> </span>System.out.print("访问 " + map.get(10)+" 之后: ");
- <span style="white-space:pre"> </span>System.out.println(map);
-
- <span style="white-space:pre"> </span>System.out.print("最后key: ");
- <span style="white-space:pre"> </span>Iterator it = map.keySet().iterator();
- <span style="white-space:pre"> </span>while (it.hasNext()) {
- <span style="white-space:pre"> </span>Object key = it.next();
- <span style="white-space:pre"> </span>System.out.print(key+" ");
- <span style="white-space:pre"> </span>}
- <span style="white-space:pre"> </span>System.out.println();
- <span style="white-space:pre"> </span>}
-
- <span style="white-space:pre"> </span>public static void main(String[] args) {
- <span style="white-space:pre"> </span>TestOfOrderOfMap test = new TestOfOrderOfMap();
- <span style="white-space:pre"> </span>LinkedHashMap lhm1 = new LinkedHashMap(16, 0.75f,true);
- <span style="white-space:pre"> </span>Integer a[] = new Integer[]{7, 0, 5, 10, 17, 6, 2, 8, 3, 31};
-
- <span style="white-space:pre"> </span>test.testOfKeyset(lhm1, a);
- <span style="white-space:pre"> </span>}
- }
结果为
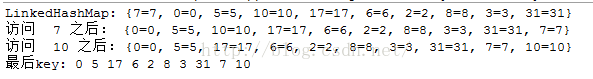
图9
分析:插入的顺序为 7, 0, 5, 10, 17, 6, 2, 8, 3, 31 map.get(7)之后,也就是访问7之后,就把7放在了链表的最末尾,也就是放在了31之后,变成了
0,5,10,17,6,2,8,3,31,7 接着map.get(10)之后,也就是访问10之后,就把10放在了链表的最末尾,也就是7之后,变成了 0,5,17,6,2,8,3,31,7,10
这就是按访问顺序存储,据说这样的好处就是可以实现LRU,即把所有访问过的对象放在了最后,那么没有被访问过的对象就在最前面了,当内存不够用时,
就可以直接把前面最近最久没有使用的对象删除以接受新对象,从而实现置换。
下面附加一个小知识,
当构造方法的参数 accessOrder为true时,LinkedHashMap的get()方法会改变数据链表,那会有什么后果呢?先看结果
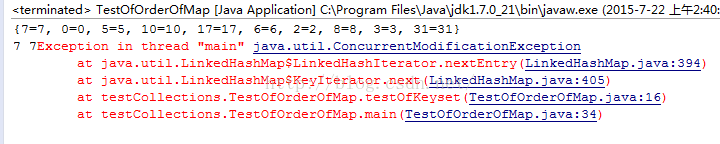
图10
啊哦,报错了,Java.util.ConcurrentModificationException,先说明下,当用Entryset 来遍历的时候就不会有错,用keyset 遍历的时候就会有错,就是下面这段代码
- <span style="white-space:pre"> </span>Iterator it = map.keySet().iterator();
- while (it.hasNext()) {
- <span style="white-space:pre"> </span>Object key = it.next();
- <span style="white-space:pre"> </span>System.out.print(key+" ");
- <span style="white-space:pre"> </span>System.out.print(map.get(key));
- }
这是为什么呀,根据报错的源代码就很好理解了
- <span style="white-space:pre"> </span>nextEntry() {
- if (modCount != expectedModCount)
- throw new ConcurrentModificationException();
- if (nextEntry == header)
- throw new NoSuchElementException();
-
- Entry<K,V> e = lastReturned = nextEntry;
- nextEntry = e.after;
- return e;
- }
因为当 accessOrder为true时,
LinkedHashMap的get(
)方法会改变数据链表,因为每访问一次都要把这个key对应的Entry放到链表的最末尾(上面已经分析过),而Keyset 的 Iterator对象不允许我们动态去改变LinkedHashMap的数据链表结构,正如上面的源代码所说的,Entry 被修改的次数不等于它期望的被修改次数。因为本来就是排好序的了,你现在每访问一个,就把它放在最末尾,那么我接下来去找它的下一个的时候却发现原来那个已经不在了,因为这是动态发生的,谁也察觉不到,只有当访问到它的时候才发现不在那个位置了(拿上面那个例子,访问第一个位置上7的时候还是没问题的,访问完之后,把7放到最后面,原来的第二个位置对应的0,现在被顶到了第一个位置上,那么我下一轮该访问0的时候却发现0不见了,换成了5,那么是不是就应该报错呢)。现在明白了吧。就好比我用书包背十个乒乓球去体育馆打球,突然过来一个同学偷偷摸摸拿走了一个,还把一个坏了的放我书包里面,也不跟我打声招呼,我也没看见,过了一个小时,我把其中的9个乒乓球都打坏了,想拿第十个来用,发现,咦,怎么是坏的啊,谁换了我的乒乓球啊,我这时是不是该报警啊(哈哈,开个玩笑)
那为什么accessOrder 为false时,采用keyset遍历就不会出现这种异常啊,因为为false 时,是按插入顺序存储啊,没有破坏原来的顺序啊,也就不会出现
modCount != expectdModCount 的情况了。
那为什么entryset遍历的时候就不会出错呀?因为,keyset 只是预先把所有的key 放到了set当中,没有跟value对应起来,
而entryset是把预先所有的Entry 都放在了set中,Entry中有key对应的value,所以key改变的时候value 也会跟着改变,就不会发现错位的情况了。
两个的源码比较
- private class KeyIterator extends LinkedHashIterator<K> {
- public K next() { return nextEntry().getKey(); }
- }
- private class EntryIterator extends LinkedHashIterator<Map.Entry<K,V>> {
- public Map.Entry<K,V> next() { return nextEntry(); }
- }
其中next()里面的return,在KeyIterator类中还多了一个getKey()。
记得啊,你要犯这一个错误得要有三个条件才行呢,1,accessOrder 设为true。2,用keyset 遍历。3,使用map.get(key)方法
到此,最开始提出的三个问题都已经解决了。
那么回过头来,我们来测试当key为String 对象的时候又是个什么情形呢,其实也是大同小异啦
- package testCollections;
-
- import java.util.*;
- import java.util.Map.Entry;
-
- public class TestOfOrderOfMap {
-
- public void testOfKeyset(Map map, Object obj[]){
- for(int i=0; i<obj.length; i++){
- map.put(obj[i], obj[i]);
- }
-
- if(map instanceof LinkedHashMap){
- System.out.println("LinkedHashMap" +": " + map);
- }else if(map instanceof HashMap){
- System.out.println("HashMap" +": " + map);
- }else if(map instanceof Hashtable){
- System.out.println("Hashtable" +": " + map);
- }else if(map instanceof TreeMap){
- System.out.println("TreeMap" +": " + map);
- }
-
- System.out.print("key: ");
- Iterator it = map.keySet().iterator();
- <span style="white-space:pre"> </span>while (it.hasNext()) {
- <span style="white-space:pre"> </span>Object key = it.next();
- <span style="white-space:pre"> </span>System.out.print(key+" ");
- <span style="white-space:pre"> </span>}
- <span style="white-space:pre"> </span>System.out.println();
- }
-
- public static void main(String[] args) {
- TestOfOrderOfMap test = new TestOfOrderOfMap();
-
- HashMap hm2= new HashMap();
- Hashtable ht2 = new Hashtable();
- TreeMap tm2 = new TreeMap();
- LinkedHashMap lhm2 = new LinkedHashMap(10, 0.75f, true);
-
-
- String a[] = new String[]{"aa", "Ok", "YOU", "abc", "67k"};
-
-
- System.out.println("这里是KeySet的测试:");
- test.testOfKeyset(hm2, a);
- test.testOfKeyset(ht2, a);
- test.testOfKeyset(tm2, a);
- test.testOfKeyset(lhm2, a);
-
-
-
-
-
-
-
-
-
- }
- }
结果

图11
分析,HashMap 跟 Hashtable 一样都是无章可循的,根据它自己的hashCode来存储,TreeMap呢,根据key 的第一个字母进行排序,先数字到大写字母再到小写字母。
LinkedHashMap 就还是跟上面的分析一样。完毕!
总结:
1、HashMap、Hashtable的存储顺序跟key 所对应的hashCode有关,但是有小规律,当key的值不超过16时,HashMap的存取是按照从小到大的顺序来存取的, 当key的个 数不超过11且key的值不超过11时,Hashtable的存取是按照从大到小的顺序来存取的。TreeMap 的顺序按照从小到大,LinkedHashMap的顺序有两种,一种是按插入顺 序,一种是按访问顺序,取决于accessOrder是否为true。
2、keyset 跟 entryset 的遍历结果没有区别,有一点点区别是在LinkedHashMap中当按访问顺序存储时,采用keyset 遍历 get()方法会报错。
3、HashMap 的默认大小为16,每次增长会加倍,Hashtable的默认大小为11,每次增长原来的2倍加1,TreeMap 跟 LinkedHashMap暂时无法确定或者说无限大,不过在这里不影响我们的理解。






















 101
101











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









