










《Edge Boxes: Locating Object Proposals from Edges》是ECCV2014的一篇关于目标检测的一篇文章,作者是来自于微软研究院的Piotr等人,属于大中牛范畴。本文并没有涉及到“机器学习”,其采用的是纯图像的方法,这点让我大感意外,因为很多提取proposals的文献,例如BING等,都是基于学习理论的方法。此外,本文的许多内容,甚至数学公式,都是基于作者的直觉直接建立,可以说,牛的一腿。。。。。
一篇学术paper,一般由研究目标,研究方法和实验结论组成,以下部分分别从这几方面进行介绍。
本文的研究目的:为了加速现有目标检测算法,提出了一种能够以较高精度确定proposal的新方法。其中,proposal还没有一个确定的中文翻译,一般被称作“目标大概可能的位置”。这个概念非常重要,我们大家想想,当我们看到一幅图像的时候,我们绝对不会像传统检测算法那样,从图像左上角开始扫描图像,而是一眼“纵观全局”,直接发现目标“大概的位置”,然后进一步细看,proposal正是由人类这一特质启发,而提出的。显而易见,这样的方式,速度会很快,但是,如果proposal提取的不准,那么就悲催了。
本文的研究方法:利用边缘信息(Edge),确定框框内的轮廓个数和与框框边缘重叠的轮廓个数(这点很重要,如果我能够清楚的知道一个框框内完全包含的轮廓个数,那么目标有很大可能性,就在这个框中。这也是作者的一大直觉,牛吧?),并基于此对框框进行评分,进一步根据得分的高低顺序确定proposal信息(由大小,长宽比,位置构成)。而后续工作就是在proposal内部运行相关检测算法。
下面试着详细介绍本文算法流程。

图 1. 算法思想图示
图1来自于文献,箭头是我自己加的,我觉得这幅图像,可以很好的说明该文的算法思想。
首先,第一行是原图,第二行是基于文献《Structured Forests for Fast Edge Detection》所提出的结构化边缘检测算法,得到的边缘图像,这时的边缘图像显得很紧密,需要用NMS进一步处理得到一个相对稀疏的边缘图像。
其次,第三行中,本来灰色的边缘变成了五颜六色的边缘,其实这些五颜六色的边缘是基于某种策略,将边缘点集合起来得到的N多个小段,论文中,叫做edge group。所采用的的策略是:将近乎在一条直线上的边缘点,集中起来形成一个edge group,具体的做法是,不停地寻找8连通的边缘点,直到两两边缘点之间的方向角度差值的和大于pi/2,这样便得到了N多个edge group。
再其次,得到N个edge group之后,还要进一步计算两两edge group之间的相似度,相似度的公式很简单,如下:
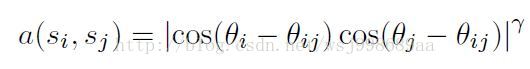
这样变使得,如果两个edge group越在一条直线上,上述公式计算得到的相似度就越高,反之亦然。作者之所以引入edge group概念,是为了确定轮廓个数做准备,因为一个轮廓中的所有edge group当然是最相似的,这点可以在纸上画画,十分明显。
最后,让我们看看作者是怎么根据edge group来确定轮廓的。作者的做法在我看起来很奇葩,他给每一个edge group一个权值,换句话说,打个分数,然后把权值均为1的edge group归为框框内轮廓上的一部分,把权值为0的edge group归为框框外或者与框框边界重叠的轮廓的一部分。采用了一个数学公式达到了上述目的,如下:
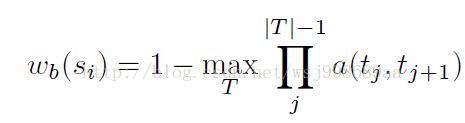
其中,T是指从框框的边缘开始到达si的edge group序列集合,当然,会有很多个T,看到没,它的目标就是从这么多的路径T中,寻找相似度最高的路径,这就是传说中的轮廓。值得注意的是,在某路径T上,一旦出现相似度为0(这很容易出现)的情况,这条路径T就废弃了,所以想找到那个合适的T,真的很快。。。。
最最后,作者给出了框框的评分(具体公式没什么好解释的,就不给出了)。然后就得到了倒数第二行的效果,效果还是很不错的。
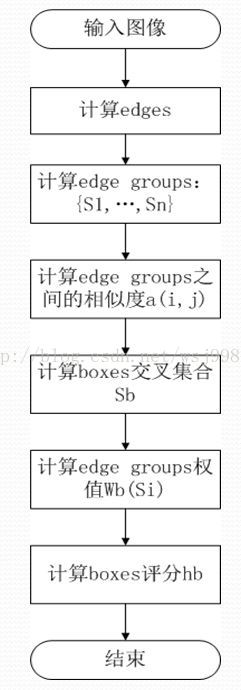
综上,给出自己画的算法流程图,如下所示:
本文的实验效果:作者和几个当前流行的proposal提取算法进行了比较,得到了比较不错的效果,主要是基于经典的PASCAL VOC数据集,但是不得不说,他把BING弄得太差了。另外,这个算法存在一个较大的缺陷。
本文算法的不足:一句话,通过demo测试,发现,其评分较高的proposals均为近乎整幅图像,比如说,图像中有8个人,那么该算法评分最高的proposal肯定是同时包含了这8个人的,这一点不足,使得这个算法的含金量大大缩水,因为,在实际应用中,我想要的效果往往是,最高评分的几个proposal最好是单独的人,而不是8个人一起。
至于原因,不难理解,上面已经说过了,本文不是基于“学习”的算法,没有训练过程,不可能像BING那样,训练了单独人体,那么最高评分的proposal肯定就是单独的人体,训练了汽车,那么最高评分的proposal肯定就是单独的汽车等等。。。。
关于读后感:其实这篇文章,我有很多细节还没有说出来,一方面时间不够,另一方面,自己的文采不行,说多了就会显得啰嗦。所以,还请各位读者不吝批评赐教,大家一起学习,共同进步!!!!
(转载请注明:http://blog.csdn.net/wsj998689aa/article/details/39476551)














 4376
4376











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









