










论文地址:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
前言
虽然GoogLeNet在ILSVRC2014上斩获了各种大奖,但是GooGle的各位大牛依然没有闲着,他们马上又抛出了一个新的问题:Internal Covariate Shift,也就是本文要研究的问题,他们提出了一个新的层:Batch Normalization(BN),不仅能够很好的解决这个问题,而且在增快训练速度的基础上能够有效的提高模型的性能。
Internal Convariate Shift
以下是载自于李理:卷积神经网络之Batch Normalization的原理及实现中的一段话:
如果训练时和测试时输入的分布变化,会给模型带来问题。当然在日常的应用中,这个问题一般不会太明显,因为一般情况数据的分布差别不会太大,但是在很深的网络里这个问题会带来问题,使得训练收敛速度变慢。因为前面的层的结果会传递到后面的层,而且层次越多,前面的细微变化就会带来后面的巨大变化。如果某一层的输入分布总是变化的话,那么它就会无所适从,很难调整好参数。我们一般会对输入数据进行”白化“除理,使得它的均值是0,方差是1。但是之后的层就很难保证了,因为随着前面层参数的调整,后面的层的输入是很难保证的。比较坏的情况是,比如最后一层,经过一个minibatch,把参数调整好的比之前好一些了,但是它之前的所有层的参数也都变了,从而导致下一轮训练的时候输入的范围都发生变化了,那么它肯定就很难正确的分类了。这就是所谓的Internal Covariate Shift。
简言之就是:先前层参数的调整会导致之后每一层输入值的分布发生变化,所以在深度神经网络模型的训练中, 通常需要细致选取初始参数并采取较小的学习率。
数据预处理
常用的数据预处理手段,如归一化(normalization)、PCA/ZCA白化(whitening),能够对数据进行去均值、标准方差、去相关等操作,使得网络训练的收敛速度加快。如果在模型的每一层的输入都使用类似的预处理操作,就可以实现输入的固定分布,从而能够有效的消除Internal Convariate Shift的影响。如下图所示:
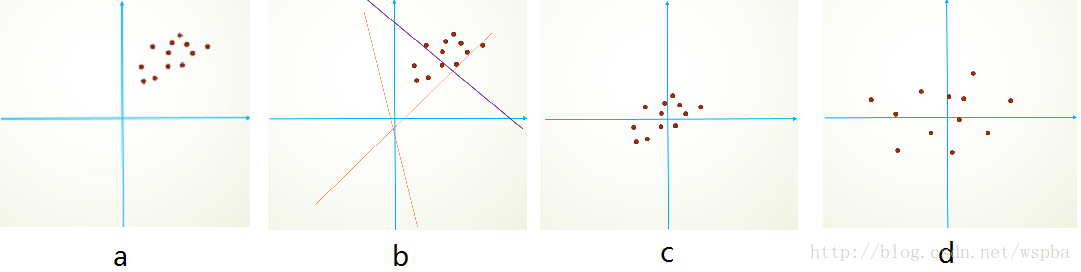
原始数据分布如a所示,如果要对它直接进行拟合会比较难(b的红色虚线到紫色实线),如果进过去均值(c),和去相关(d)操作,这样就可以明显的提升训练的效率和效果。
但是类似于白化的操作要参考所有的样本,并且需要计算协方差矩阵、求逆等操作,计算量很大,同时,在反向传播时,白化操作不一定处处可导。因此在每一层都加一个类似于白化的操作是不现实的,但是也为接下来的工作提供了很好的思路。
Batch Normalization
白化的计算代价太大,而且不是处处可导,因此作者做出了两个简化。
第一个简化:在数据的每一个维度上进行归一化,即对于一个d维的输入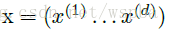
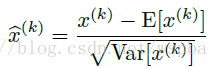
虽然这无法消除数据间的相关性,但是能够提高模型的收敛速度。
但是这样一个简单的归一化操作可能会影响到该层所学习到的特征,例如对sigmoid函数,如果使用这个简单的归一化操作,可能会将数据限制在sigmoid的线性部分,如下图,这样非线性函数就失去的意义。
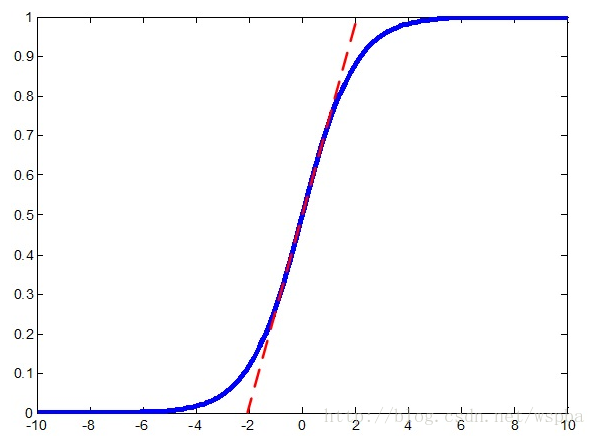
于是作者又提出了两个参数: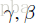
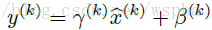
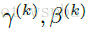
第二个简化:既然模型是使用mini-batch来进行前向和反向计算,那么对于每一个batch的激活也可以是用该batch的数据来对均值和方差进行估计。
这样的话,整个Batch Normalization的前向公式为:

同时它还是处处可导的,它的反向求导公式为:
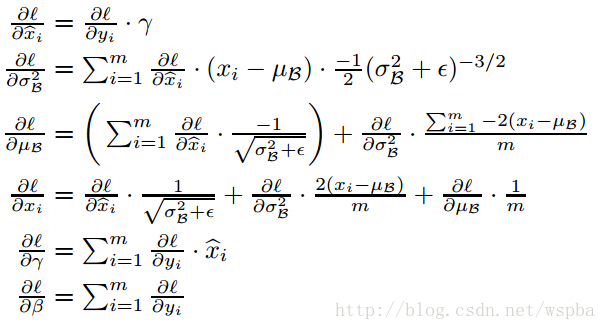
BN的推理过程
依赖小批量数据的BN在训练过程中,可以利用batch的信息对数据进行归一化,能够有效的加速训练,但是在推理过程(inference)中,可能无法利用到batch的信息(假设只有一个测试样本),这样的话,没有均值,没有方差,该如何进行归一化计算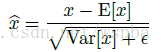
作者的做法是,利用训练的mini-batch中计算的均值的期望和方差的期望来作为全部样本均值和方差的无偏估计,即:
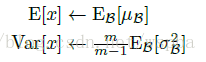
再加上训练得到的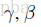
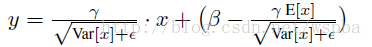
这样除了x和y以外,所有值在模型训练完毕后就已经固定了,这就相当于对输入x的一个线性变换。
CNN的BN
作者提到,在卷积层的输出和非线性层(sigmoid或ReLU)的输入之间使用BN层,在不在卷积层的输入之前使用BN,原因是卷积层的输入通常为非线性层的输出,其分布可能在训练过程中发生改变,依然会产生Internal Covariate Shift的问题,而在卷积层后,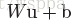
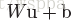
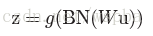
由于卷积层具有权值共享性,因此对于每一个feature map,共享一组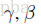
BN的作用
- 可以使用更大的学习率,加速训练,加速训练,加速训练(重要的事情说三遍,在模型训练中真正体会到了什么叫做兵贵神速啊)。
- 提高了模型下的正则化,可以去除dropout、L2正则化。
- 不再需要LRN层,BN本身能起到normalization的效果。
实验
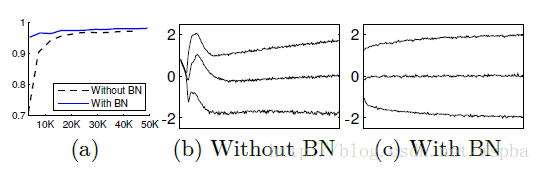
从sigmoid输入的分布上来看,分布更加稳定,能够提高模型的准确性。
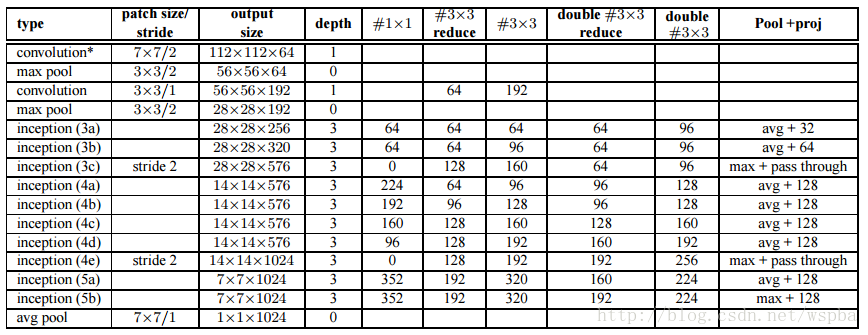
对于ImageNet分类上,作者使用了GoogLeNet Inception的改进:增加了BN层;将5*5的卷积层使用两个3*3卷积层的堆叠来替代(与vgg类似),模型的框架如下:
可以参照GoogLeNet Inception V1。
实验结果:
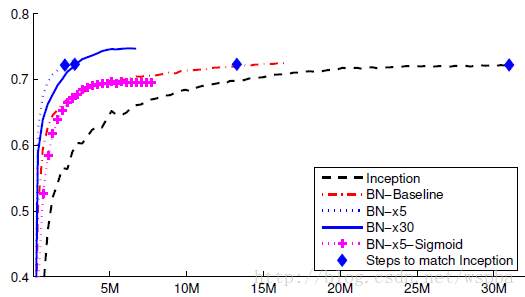

其中x5和x30分别为将学习率提高了5倍和30倍。结果表明,使用BN能够大大提高收敛速度,例如BN-x5达到与Inception相同的72.2%准确率,训练速度提高了14倍。同时在精度上也得到了提高。
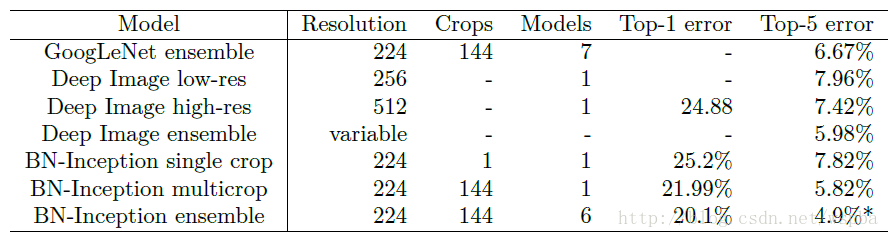
在essemble的分类top1和top5错误率上,使用BN的性能也好于其他模型。
学习参考:《Batch Normalization Accelerating Deep Network Training by Reducing Internal Covariate Shift》阅读笔记与实现














 1923
1923











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









