csdnSpider.py代码
import bs4
import requests
origin = 'http://blog.csdn.net'
user_agent = ('Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36')
headers = {
'origin': origin,
'User-Agent': user_agent,
}
date = []
for i in range(1, 5):
url = 'http://blog.csdn.net/WuLex/article/list/'+str(i)
r = requests.get(url=url, headers=headers)
page = r.content.decode('utf-8')
doc = bs4.BeautifulSoup(page, 'lxml')
articleList = doc.findAll('div', attrs={'class': 'list_item article_item'})
for ele in articleList:
title=ele.find('span', attrs={'class': 'link_title'}).get_text()
descripe = ele.find('div', attrs={'class': 'article_description'}).get_text()
views = ele.find('span', attrs={'class': 'link_view'}).get_text()
date.append(title + "\r\n" + descripe + "\r\n" + views + "\r\n"+"-------------------------------------------------------------------"+ "\r\n")
with open('blognames', 'w',encoding='utf-8') as f:
for i in date:
f.write(i)
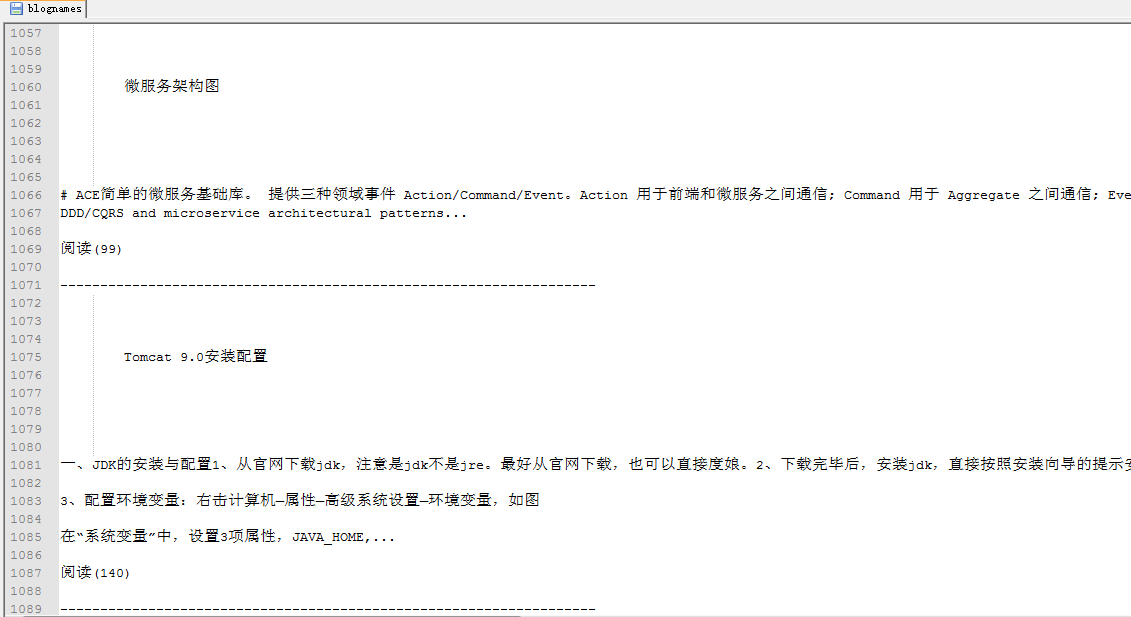
运行结果如图






















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









