







期望交叉熵也称为KL距离,反映的是文本类别的概率分布和在出现了某个特征的条件下文本类别的概率分布之间的距离,具体公式表示如下
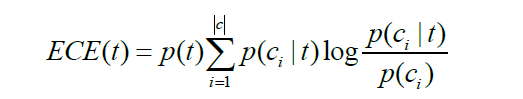
其中, P(t)表示特征t在文本中出现的概率, P(ci)表示ci类文本在文本集中出现的概率, P(ci|t)表示文本包含特征t时属于类别c的概率,|c|表示类别总数。如果特征t和类别强相关,即P(ci|t)大,并且相应的P(ci)又比较小,则说明特征t对分类的影响大,相应的期望交叉熵值也较大,特征在特征子集中的排名就会比较靠前。
期望交叉熵在文本分类的特征选择中得到了广泛的应用,并且取得了很好的效果,与信息增益相比,期望交叉熵不再考虑特征项不出现的情况,这就大大降低了一些出现次数很少的稀有特征的干扰,提高了分类的效率。期望交叉熵在特征选择上虽然已经取得了很好的效果,但是还存在一些不足,最明显的一点就是它只考虑了特征与类别之间的相关性,而忽略了特征项在类内和类间分布的均匀程度。如果考虑到特征在类内和类间分布的影响,则特征项集中的出现在某一个类中比均匀分布在很多类中含有更多的类别信息,特征项在某一个类中均匀地分布在很多文本中比只在该类中个别文本中出现含有更多的类别信息。
特征项在类内和类间分布的均匀程度与它对分类的影响有以下两方面的关系:
1) 若存在某个特征词,该特征词如果集中地出现在某个类别中,而在其他类别中很少出现,那么这个特征词就可以很好的将其所在的类别和其他类别区分,就可以很好的代表当前类别,对分类的贡献也就越大。
2) 若存在某个特征词,在其当前所在类别中,如果含有该特征词的文本数在该类别中所占的比例越高,就越能代表当前类别,对分类的贡献也就越大。
为了描述以上两方面的关系,本文引入了特征项的类间集中度和类内分散度两个概念。
类间集中度(Concentration Degree):表示的是特征项在各个类别中分布的均匀程度,特征项越集中分布在某个类别中而不是均匀分布在各个类中时,带有的类别信息就越多,表征类别的能力就越强。计算公式如下:

其中,N_c_t表示ci类中出现特征t的文本数,N_t表示训练集中出现t的文本数。
类内分散度(Distribution Degree):表示的是特征项在某个类内部分布的均匀程度,特征 项在某个类中越多的文本中出现,越分散,就越能代表该类,对分类的贡献越大。计算公式如下:
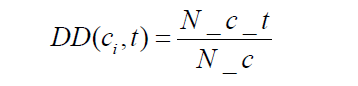
其中,N_c_t 表示ci类中出现特征t的文本数,N_c 表示ci类中的总文本数。
特征项的类间集中度和类内分散度是需要综合考虑的,两者缺一不可。如果只考虑二者其一,得到的特征项就不能很好地提高分类效果,不仅不能提高期望交叉熵的特征选择效果,还会对特征选择造成干扰。例如:假设有三个类别,每个类别有100篇文本,若某个特征词只在其中一个类别中出现了1次,该特征词明显是一个稀有特征词,不能很好地代表该类的信息,是应该在特征选择中被淘汰的,但如果只考虑类间集中度,则该特征项的类间集中度为100%,特征选择算法计算的分数会较高,会对特征选择造成干扰;若存在另一个特征词,分别在三个类别中都出现了80 次,则该特征词不能很好的进行类别区分,应该在特征选择中被淘汰,但如果只考虑类内分散度, 该特征词在每个类中的分散度都是80%,计算得到的特征分数会很高,也会对特征选择造成干扰。综合以上分析,类间集中度和类内分散度是一个不可分的整体,应该将两者进行综合考虑。改进后的基于类间集中度和类内分散度的期望交叉熵公式为:
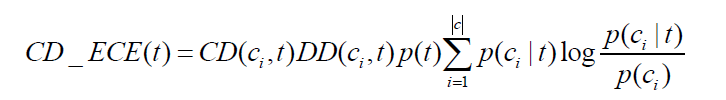
由公式可见,在基于类间集中度和类内分散度的期望交叉熵中,特征项在传统期望交叉熵基础上,若类间集中度越高,类内分散度越高,得到的特征分数就越高,就越有可能被选入特征子集。














 1014
1014











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









