







#28讲项目实战:网站搜索功能+单页面开发
一、搜索功能调用
1、在首页搜索功能的位置,调用代码: <?php get_search_form(); ?>
2、查看编译后的代码,然后把编译后的代码替换自己写好的样式代码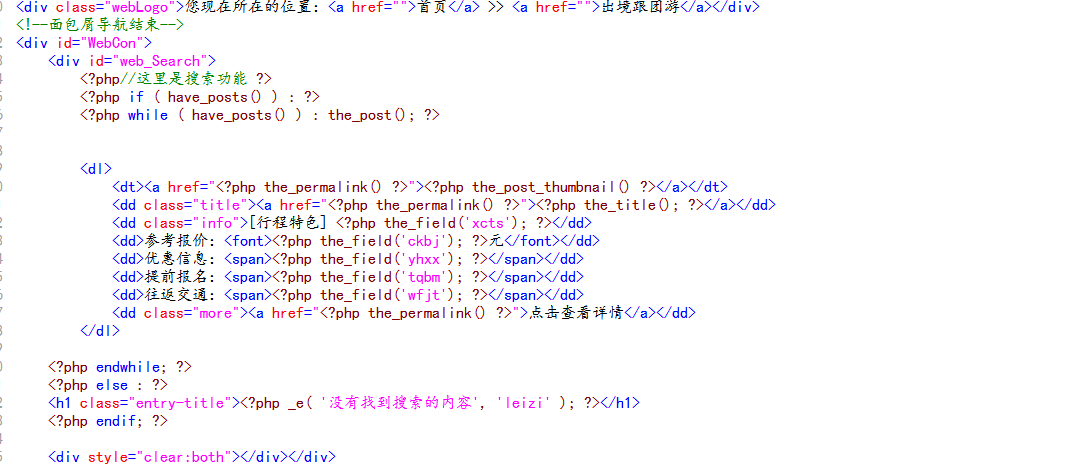
1、在首页搜索功能的位置,调用代码: <?php get_search_form(); ?>
2、查看编译后的代码,然后把编译后的代码替换自己写好的样式代码
二、构建搜索模板
1、在主题模板文件夹下,新建 search.php (搜索模板)
2、搜索页模板标签的调用,其中调用所属栏目: <?php the_category(' , '); ?>
1、在主题模板文件夹下,新建 search.php (搜索模板)
2、搜索页模板标签的调用,其中调用所属栏目: <?php the_category(' , '); ?>
三、搜索结果的分页功能
1、不分页
2、找到functions.php 找到之前添加分页功能的代码 (具体操作看视频)
单页面开发
一、单页面开发
1、进到后台,找到页面->新建页面
2、单页面链接地址 /web/?page_id=111
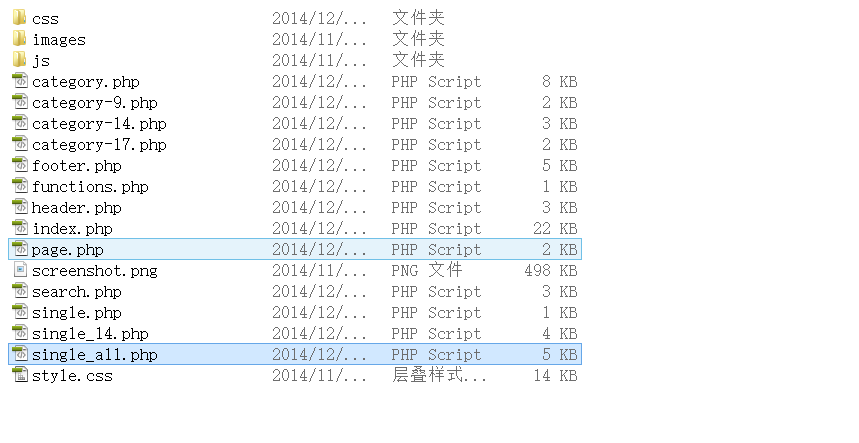
3、找到主题模板文件夹,新建单面板文件 page.php
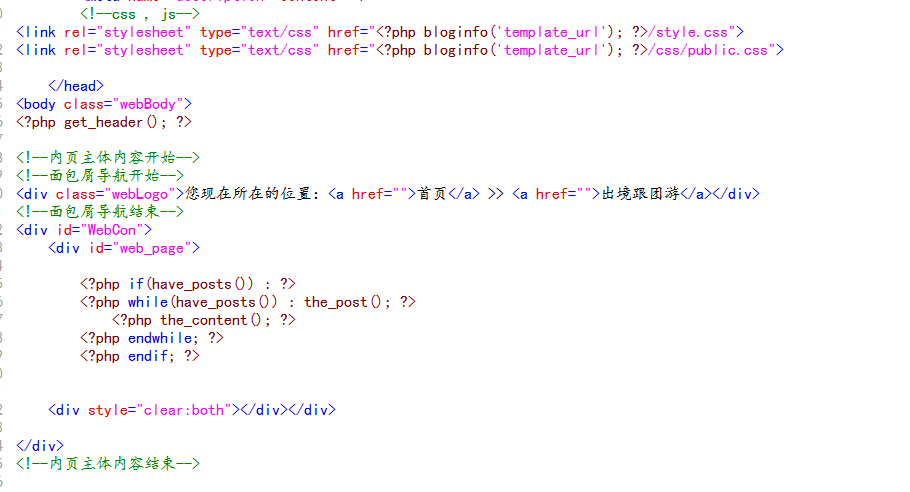
4、单页模板内容调用代码如下
1、不分页
2、找到functions.php 找到之前添加分页功能的代码 (具体操作看视频)
单页面开发
一、单页面开发
1、进到后台,找到页面->新建页面
2、单页面链接地址 /web/?page_id=111
3、找到主题模板文件夹,新建单面板文件 page.php
4、单页模板内容调用代码如下
<?php if(have_posts()) : ?>
<?php while(have_posts()) : the_post(); ?>
<?php the_content(); ?>
<?php endwhile; ?>
<?php endif; ?>
<?php while(have_posts()) : the_post(); ?>
<?php the_content(); ?>
<?php endwhile; ?>
<?php endif; ?>














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









