




 本文详细阐述了计算机存储模型中的虚拟内存概念及其管理方式,包括页式管理、页表、页表项、多级页表、MMU、快表TLB、页面置换算法以及段式管理等核心内容,旨在帮助读者理解如何在有限的物理内存中高效运行多个程序。
本文详细阐述了计算机存储模型中的虚拟内存概念及其管理方式,包括页式管理、页表、页表项、多级页表、MMU、快表TLB、页面置换算法以及段式管理等核心内容,旨在帮助读者理解如何在有限的物理内存中高效运行多个程序。
接着前两篇文章
浅谈计算机中的存储模型(一)存储体系
浅谈计算机中的存储模型(二)物理内存
这篇主要介绍虚拟内存
目录
- 虚拟存储器
- 页式管理
- 页表
- 页表项
- 单一页表
- 多级页表
- 倒排页表
- MMU
- 快表TLB
- 页错误/缺页异常
- 页面置换算法
- OPT
- FIFO
- 第二次机会
- 时钟算法
- LRU
- 老化算法
- NRU
- 页表
- 段式管理
- 段/页式管理
- 内存映射和写时复制
- 页式管理
这里先补充下地址空间的概念:
现代系统都是多任务系统,而我们的进程是在内存中运行的,内存是有限的,我们如何保证可以安全而又高效的在有限的内存中运行多个程序呢?于是系统给每个进程抽象出一个地址空间。
物理地址直接暴露给进程会带来一些问题:
1.进程可能会访问禁止访问的空间,如操作系统的地址
2.运行多个进程是困难的
看下图
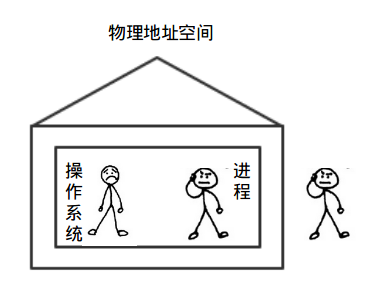
地址空间为程序创造了一种抽象的内存。地址空间是一个进程可用于寻址内存的一套地址集合。每个进程都有一个自己的地址空间,并且这个地址空间独立于其他进程的地址空间。
地址空间
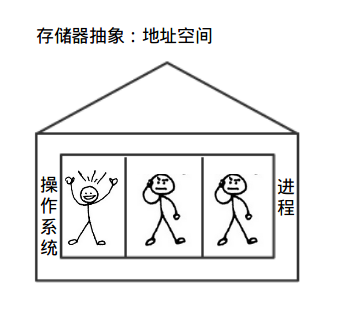
虚拟存储器
虚拟存储器概念:现代系统为了更好的管理存储器并且保证安全提供了一种对主存的抽象概念,叫做虚拟存储器。
虚拟存储器提供了三个重要的能力:
1. 它将内存看为是磁盘的高速缓存,在内存中只保存活跃的区域,并根据需要在内存和磁盘中来回传送数据,使得主存的使用更加高效。
2.它为每个进程抽象出了一致的内存空间,使得多进程可以更加简单的运行,简化了存储器的管理。
3.它保护了每个进程可以单独的,高效的运行,每个进程的地址空间不会被其他进程破坏
看完了概念看张图理解下:
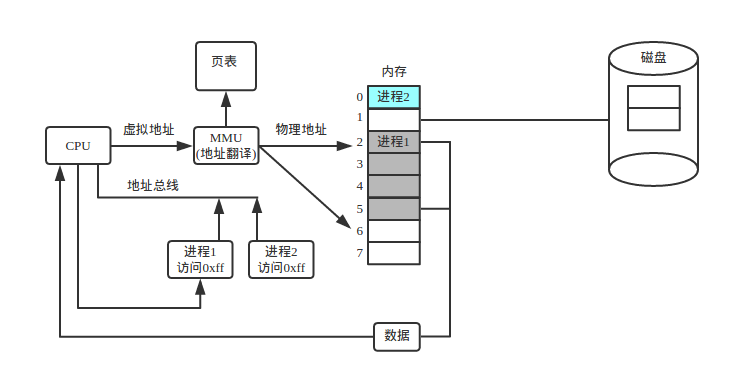
描述下上图的过程
前面说了每个进程都有一个抽象的地址空间,进程1访问物理内存中的数据时,它获得的地址是抽象的虚拟地址,需要将虚拟地址转化为物理地址,那么就需要硬件MMU通过一些数据结构来进行地址转换从而得到物理内存的地址,然而物理内存是有限的,如果每个进程都要全部加载到内存中内存肯定不够,后来先辈们就发现我为什么要把进程全部内容加载到内存中去呢,根据二八定理,百分之百的内容常用的也就百分之二十,所以我只需要将每个进程常用的加载到内存中,不用的我先暂存到磁盘,如果需要它时在从磁盘中将它加载出来。这就是上图中内存和磁盘的连线关系,装过系统的朋友都知道无论是linux还是windows分区时我们都要给它分交换分区,交换分区其实就是暂存物理内存中不用的内容。这时如果物理内存中有数据就传送给cpu,如果没有就产生异常,然后内存和磁盘进程数据交换后在由内存将数据传送给cpu。
这就是虚拟存储器
如果你还是不理解为什么要抽象出地址空间,每个进程要抽象出虚拟内存,可以这样想。
32位机器下,内存最大是2^32也就是4GB,比如你的内存是4GB,现在你的机器上跑了10个程序,开始10个都占据内存非常少,但是,但是每个程序都有这样的能力,我是可以使用到4G内存的,只是我暂时没有这个需要!!,这时10个程序中的其中一个突然开始大量使用内存,它有能力使用到近乎4G的内存,而其它9个也正常运行。
还是看图吧!
纵坐标表示内存占用率,横坐标表示进程
那么可以这样使用

也可以这样
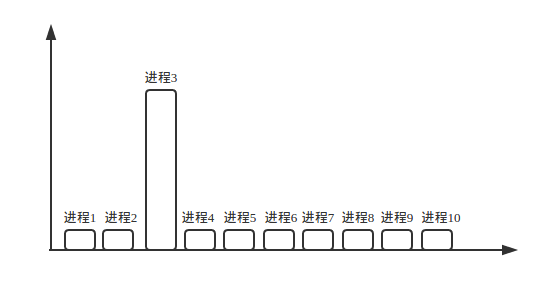
还可以这样,总量不超过内存大小即可
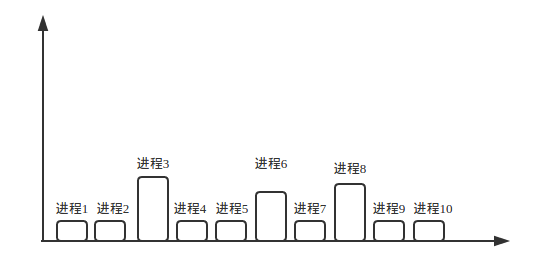
实际上每个进程都可能很大的,不用的我们先放到磁盘嘛。
下面我们来细说。
页式管理
当代系统一般都采用的是页式管理内存,什么是页式管理,简单的来讲就是将内存分为固定大小的内存块,x86下一块大小是4k,一块我们称为为一页。抽象出的虚拟内存也是按页大小分配的,而物理内存的页一般称为页框(页帧或内存块),磁盘上的交换分区也是按页大小来组织的,这样我们能发现虚拟内存->物理内存->磁盘都是相同大小的结构来组织数据。
页表
内存是有限的,所以进程使用自己的地址空间虚拟内存,但是当进程需要访问自己的数据时肯定要去物理内存中的物理地址找数据,那么从虚拟内存向物理内存地址转换在页式管理中我们就需要通过页表这个数据结构来进行转换。
看下图:
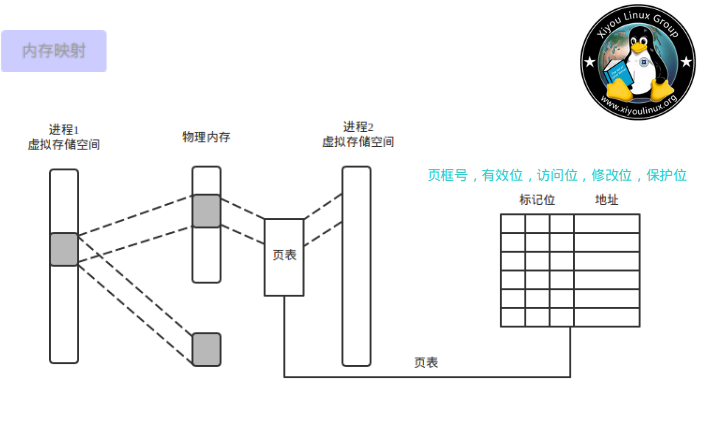
应该可以清楚页表的作用了吧~
继续
页表项
页表项就是页表中的每一项,就和链表中的每一个节点,数组中的每一个元素一样。
页表项有什么内容呢,首先肯定要有地址转换,也就是虚拟地址通过变换成物理地址,其次还有一些标记位,这里我们说常见的几个标记位。
我们以x86架构32位机器来看,地址总线是32位,也就是寻址能力是2^32,为了加快地址转换我们需要一次传送地址就能转换,前面说了一个页大小一般为4K,我们要定位到具体的数据肯定要在页面内寻址,4K=2^12,所以12位即可。32-12=20,剩余20位我们来表示物理内存的页框号。
下图:
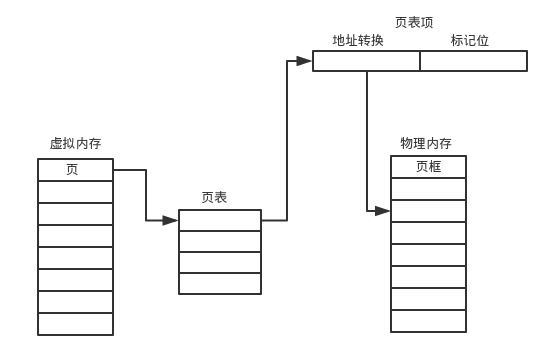
虚拟内存页中保存的是页表的中某一项索引,索引到页表中的页表项时,前20位地址转换得到物理内存的页框号,后12位得到4K大小的页的页内偏移。这样就完成了一次访问过程。
一般标记位有效位,访问位,修改位和保护位。
有效位 表示此时这个页面是在内存中还是转换到了磁盘上。
访问位 表示这个页面在近期是否被访问过
修改位 表示这个页面在近期是否被修改过
保护位 是个权限位,比如这个页面属于操作系统的,那么普通程序没有权限访问它,它受保护。
多级页表
单一页表就是上面所述,从上面的描述我们可以大致计算出来页表占据空间的大小,每个进程一个页表,每个页表映射所有的物理页面,这个计算下来耗费是非常大的,所以引入多级页表。
多级页表其实是根据使用过的页面来建立页表,一级索引二级,二级索引内存,该进程没有使用的页面二级页表就不会映射。
如下图:
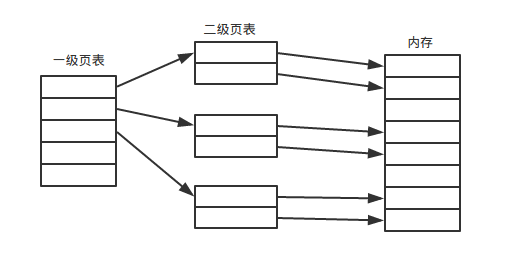
部分内存该进程并没有使用,所以未使用的不存在二级页表。
这样节省了空间。
当然不仅仅有二级页表,corei7使用的就是4级页表。
倒排页表
倒排页表其实是从物理内存出发,物理内存有多大,就建立多大的页表,因为所有进程共用物理内存,所以所有的进程共用这一张页表,然后更具页面的变换情况来刷新此页表。
MMU
前面简单介绍过MMU,MMU是Memory Management Unit的缩写,中文名是内存管理单元,它是中央处理器(CPU)中用来管理虚拟存储器、物理存储器的控制线路,同时也负责虚拟地址映射为物理地址,以及提供硬件机制的内存访问授权,多用户多进程操作系统。
它的功能主要有两个:
1.将线性地址映射为物理地址
2.提供硬件机制的内存访问授权
其实就是将我们刚才叙述的交给MMU来执行,单独出来一个硬件效率是比较高的。
快表TLB
快表其实就是一个页表项的缓存,如果没有快表,我们需要多次访问内存才能得到我们需要的页表项,前面说过二八定理,我们将经常使用的页表项缓存到TLB快表中,由于快表也是硬件集成的,它是并行的来查找,所以速度非常快。
页错误/缺页异常
页错误:刚说过页表上有访问位,权限位等,页错误就是我们没有按照这些标记位的规则来访问页面,比如这个页面是只读的,我们写了它,或者属于操作系统,我们错误的访问了等等。
缺页异常:我们需要访问的页面在页表中没有记录或者有效位为0表示此页面不在内存中,这时就会产生一个缺页异常,需要操作系统去磁盘上调度将页交换到内存中去。
页面置换算法
页面置换算法是针对内存和磁盘交换页面的,目的是为了尽量少交换页面,少产生缺页异常,因为访问磁盘是非常耗时的,这个后面会说到。
网上将页面置换算法的很多了,这里简单叙述下。
比如我们内存只能存储3个页面,此时页面访问顺序为2 3 2 1 5 2 4 5 3 2 5 2,肯定会出现某时该页面不在内存中的情况,此时要产生缺页异常,我们的目的是尽量少产生。
OPT理想页面置换算法:
将未来不使用的或者很久后才使用的页面置换出内存。
我们可以看出这样发生缺页异常会少很多,但是这个算法是不能实现的,它的意义是用来作为一个衡量的标准,评判其他算法的好坏。
FIFO先进先出算法
思想很简单,当需要置换页面时,将最早到来的置换出去,因为它存在的最久,这个算法是最简单的,但是缺不高效,因为我们不能保证停留最久的页面不是最常访问的。
第二次机会算法
在FIFO算法的一种改进,按照FIFO思想,本身轮到你置换出去了,现在我在给你一次机会,我访问你页表项中的访问位,如果访问位为1说明你最近被访问过,我这次不将你置换出去,把你的访问位设置为0,然后从队头放到队尾。下次再次轮到你时我在判断。如果你的访问位为0说明你最近没有被访问过,置换出去。
时钟算法
是在第二次机会算法上的一种结构的改进,将链式结构改造成环状,类似环形数组,这样就想一个时钟一样转即可,不需要像第二次机会算法一样每次每次还要将队头放到队尾这种耗时的操作。
LRU
LRU是Least Recently Used的缩写,即最少使用页面置换算法
将近期使用次数最少的页面置换出去,这种算法也是不能实现的,只有接近它的算法
老化算法
老化算法就是接近LRU的一种算法,它是给每个页面一串bit位,比如8位00000000,当每访问一个页面时,我就将每个页面的bit位向右移动一位,然后被访问的页面首位补1。
其实就像高低信号一样,随着时间右移,有新信号为1,没有则为0,长时间没有的就慢慢衰减的00000000。
NRU
NRU也是近似LRU的一种算法,不过它是根据页面的标记位来判断,比如修改位和访问位,最近访问的和最近修改的都会被置为1,没有被访问和修改这两位都为0。根据2位4中情况来判断淘汰页面。
段式管理
段式管理(segmentation),是指把一个程序分成若干个段进行存储,每个段都是一个逻辑实体,程序员需要知道并使用它。它的产生是与程序的模块化直接有关的。段式管理是通过段表(和页表类似)进行的,它包括段号或段名、段起点、装入位、段的长度等。此外还需要主存占用区域表、主存可用区域表。
在段式存储管理中,每个段地址的说明为两个量:一个段名和一个位移。在段内,是连续完整存放的。而在段与段之间是不一定连续编址的。段名和位移构成了一种二维编址。 段式管理是不连续分配内存技术中的一种。其最大特点在于他按照用户观点,即按程序段、数据段等有明确逻辑含义的“段”,分配内存空间。克服了页式的、硬性的、非逻辑划分给保护和共享与支态伸缩带来的不自然性。 段的最大好处是可以充分实现共享和保护,便于动态申请内存,管理和使用统一化,便于动态链接;其缺点是有碎片问题。
段式比较简单,就不展开说了,感兴趣可以下去查查。
段页式
就是将段式和页式组合起来管理内存。
看下图:
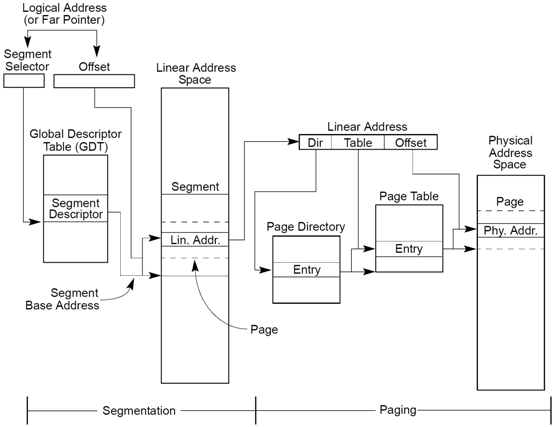
段页式内存管理有段表和页表,先通过段表来找到段,在通过段表的段内偏移其实是页框号加页内偏移,这样就再次索引页表来定位。
因为段页式管理是段式管理的页式管理方案结合而成的,所以具有它们二者的优点。但反过来说,由于管理软件的增加,复杂性和开销也就随之增加了。另外,需要的硬件以及占用的内存也有所增加。
内存映射和写时复制
内存映射
从mmap函数零拷贝内存映射角度来看,其实mmap仅仅是在内核中建立了文件与虚拟内存空间的对应关系,这样就脱离了磁盘文件系统的管理,普通的read,write都要经过文件系统,效率较低于mmap,交换分区要单独出来的原因也是这样,直接交给操作系统来管理避免磁盘文件系统。
写时复制
从fork函数创建子进程来看,其实是父子进程都通过各自的页表映射到物理内存上相同的页,当子进程修改数据时,页表上有访问权限位,得知只读时,操作系统会为它分配新的页。


















 3122
3122

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











