










前几天百度面试,当时让实现一个 LRU Cache,要求 O(1) 完成查找。后来发现这个也可以用在自己简易的 key-value 数据库项目中。
简单来说 LRU 是内存管理的一种算法,淘汰最近不用的页。
O(1) 时间完成查找,那除了 hash 别无选择。LRU 用双向链表实现即可。数据结构选择好了,查找我们用 hash 通过 key 得到链表节点的位置,然后更新 LRU 链表即可。
简单说下自己的项目,一个类似 Memcache 的小型数据库。
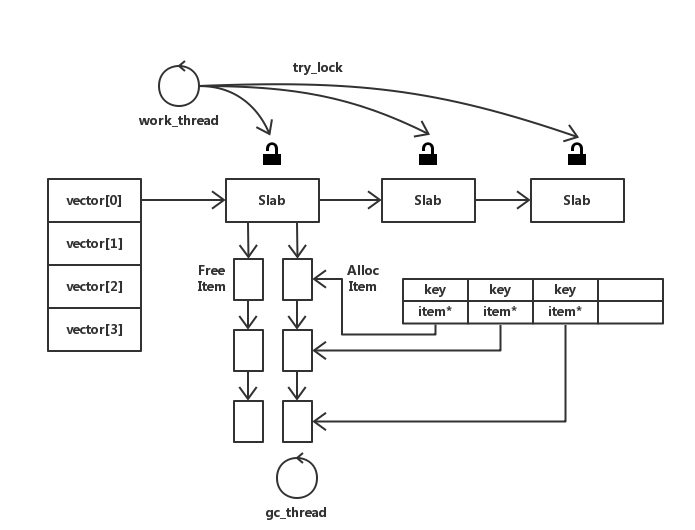
当时和 Memcache 设计不同的一点是没有将所有 Slab 上的 item 串到一起。而是将 Slab 串成一个链,每个 Slab 有自己的 Free Item List 和 Alloc Item List,当前 Slab 锁如果被占用,自旋若干次,还失败则到下一个 Slab 尝试获取锁,避免阻塞。这样减小锁的颗粒度,在并发情况下性能应该会好些。每个 Slab 的 Alloc Item List 就是一个 LRU Cache。若 Free Item 分配完时,则通过 hashmap 来找到 Alloc Item List 上的节点,完成 LRU 策略。
看代码吧,这里简单的将 Item 设置成key value 都为 string 的一个 pair。
hodis_LRU.h
#include <iostream>
#include <list>
#include <map>
#include <unordered_map>
#include <memory>
#include <string>
#include <mutex>
#include <utility>
namespace hodis {
class LRUCache {
public:
using Item = std::pair<std::string, std::string>;
using Iter = std::list<Item>::iterator;
using LRUCacheList = std::shared_ptr<std::list<Item>>;
using LRUHashMap = std::shared_ptr<std::unordered_map<std::string, Iter>>;
LRUCache();
LRUCache(uint64_t size);
~LRUCache();
public:
void set(const std::string &key, const std::string &value);
std::string get(const std::string &key);
void foreach();
private:
/* LRUCache List */
LRUCacheList lruCache;
/* hashmap
* key:string
* value:item*
* */
LRUHashMap hashMap;
uint64_t lruCacheCurSize;
uint64_t lruCacheMaxSize;
};
} /* hodis */hodis_LRU.cpp
#include "hodis_LRU.h"
namespace hodis {
LRUCache::LRUCache(uint64_t size) {
/* 创建 LRU 链表和 hashmap */
lruCache = std::make_shared<std::list<Item>>();
hashMap = std::make_shared<std::unordered_map<std::string, Iter>>();
lruCacheCurSize = 0;
lruCacheMaxSize = size;
}
LRUCache::~LRUCache() {
}
void
LRUCache::set(const std::string &key, const std::string &value){
std::mutex mutex;
auto item = std::make_pair(key, value);
/* 加锁 */
std::lock_guard<std::mutex> lock(mutex);
/* 如果当前 size 小于最大 size 则不用淘汰
* 仅仅更新 LRU 链表即可
* 如果当前 size 大于等于最大 size 则需要淘汰和更新
* */
if (lruCacheCurSize < lruCacheMaxSize) {
lruCacheCurSize++;
lruCache->insert(lruCache->begin(), item);
hashMap->insert({key, lruCache->begin()});
}else {
/* erase last item */
lruCache->erase(--lruCache->end());
lruCache->insert(lruCache->begin(), item);
if (hashMap->find(key) != hashMap->end()) {
(*hashMap)[key] = lruCache->begin();
}else {
hashMap->insert({key, lruCache->begin()});
}
}
}
std::string
LRUCache::get(const std::string &key) {
std::mutex mutex;
/* 加锁 */
std::lock_guard<std::mutex> lock(mutex);
if (hashMap->find(key) != hashMap->end()) {
auto iter = (*hashMap)[key];
auto item = *iter;
/* 注意:删除节点时,当前迭代器会失效
* 其余迭代器不变 */
lruCache->erase(iter);
lruCache->insert(lruCache->begin(), std::move(item));
(*hashMap)[key] = lruCache->begin();
return (*(*hashMap)[key]).second;
}else {
return "";
}
}
void
LRUCache::foreach() {
for (auto &item : *lruCache) {
std::cout << "key:" << item.first << " value:" << item.second << std::endl;
}
std::cout << std::endl;
}
} /* hodis */测试代码:
#include <iostream>
#include "hodis_LRU.h"
int main() {
hodis::LRUCache lruCache(5);
lruCache.set("1", "1");
lruCache.set("2", "2");
lruCache.set("3", "3");
lruCache.set("4", "4");
lruCache.set("5", "5");
lruCache.foreach();
/* 新加节点,大于 size 执行 LRU 策略 */
lruCache.set("6", "6");
lruCache.foreach();
lruCache.set("5", "5");
lruCache.foreach();
auto s1 = lruCache.get("5");
auto s2 = lruCache.get("10");
std::cout << s1 << std::endl;
std::cout << s2 << std::endl;
}运行结果如下:
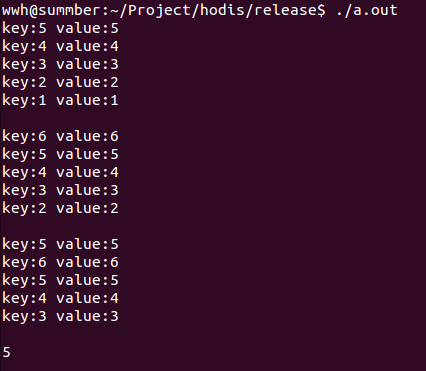
当到达 LRU Max Size 时,进行 LRU 算法。















 136
136











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











